My Cpp code is based on example_standalone_inferencing from github and the CPP11 library export.
My code:
1 - read in wav file
2 - strip header and convert to 16b PCM
3 - extract remaining wav data needed for window size, convert to 16b PCM, pass (*with header) into raw features vector
4 - run inferencing (same exact code as emample) sprintf results and write output.
5 - move file pointer and repeat N times.
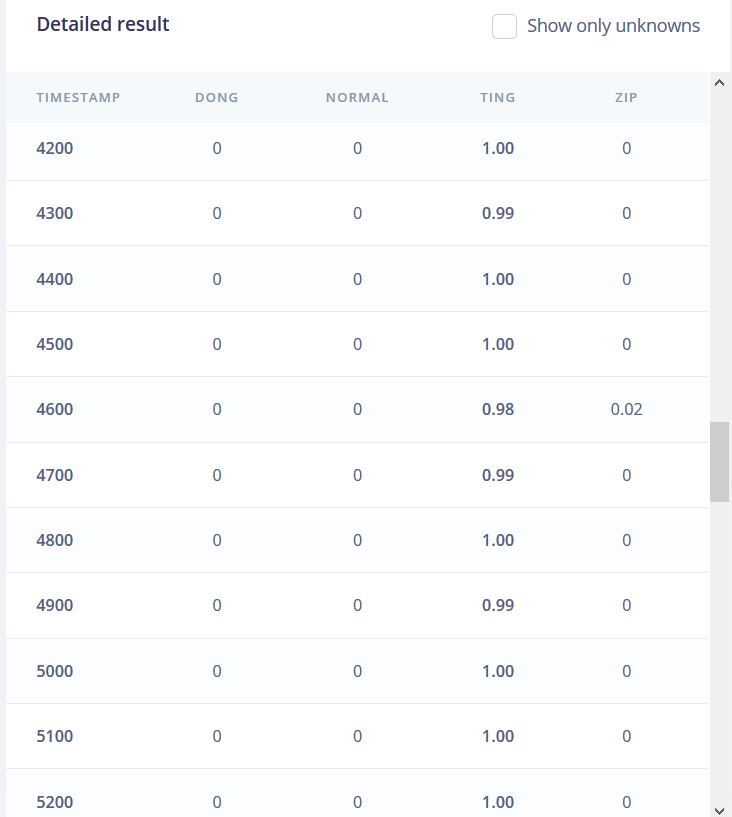
Each time a new model is trained and deployed I delete all 3 library files and recompile with new files. The results have been perfect for the majority of deployments with the exception of two models.
One did not work whatsoever. Everything was classified as the first label at >99% confidence. Retraining the model didnt work. Had to scratch and redo the whole project for it to work. The newer deployment works exactly as expected and tested in the “model testing” tab, with the exception of one class, ting. Not sure if this is a bug. I thought it could possibly be overfitting so I added 0.1 dropout layer and the model testing worked better, but still not deploying properly with the “ting” label.
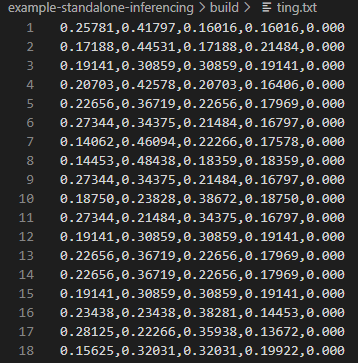
Copy the content to your features vector and check that the correct “ting” label is detected.
If that works, the issue is most likely on the wav data extraction side.
@Kerkenstuff, this looks like the input data is not passed in correctly. The output from the Studio and the C++ Library matches 99.9% when deploying a f32 model (and typically 95% for int8).
extract remaining wav data needed for window size, convert to f32, pass (*with header) into raw features vector
If you have normal 16-bit PCM data you should:
Skip 44 bytes
Read the full file 2 bytes at a time into an int16_t features[16000] buffer.
@aurel You are correct! I misspoke. The data is read in as 16b depth. I will edit my original to clarify that. I have not written the code to accept a copied in list of features but I can work on that!
@janjongboom This is (probably a better and more straightforward way to go about) the same approach I am currently using. Strip off the header and fill the vector with the datatype converted header, then raw_features.push_back the remaining data starting from the pointer location (begins at end of header, increments by window increase).
If it is the case that I am passing in the wrong data, is it possible that it could work correctly with some models and not with others? The only different between model that fails is the increased number of labels. Even so, all of the other labels pass bench testing perfectly. I am not sure what different NN failure modes look like but trying to diagnose based on symptoms is strange in this case because I would assume that if I were passing it in incorrectly it would give wildly wrong results.
If it is the case that I am passing in the wrong data, is it possible that it could work correctly with some models and not with others? The only different between model that fails is the increased number of labels. Even so, all of the other labels pass bench testing perfectly. I am not sure what different NN failure modes look like but trying to diagnose based on symptoms is strange in this case because I would assume that if I were passing it in incorrectly it would give wildly wrong results.
Are you sure the models have exactly the same number of features, same frequency, etc.?
Would be happy to take a look at the code. You can drop it to me at jan@edgeimpulse.com as well if you don’t want to share here.