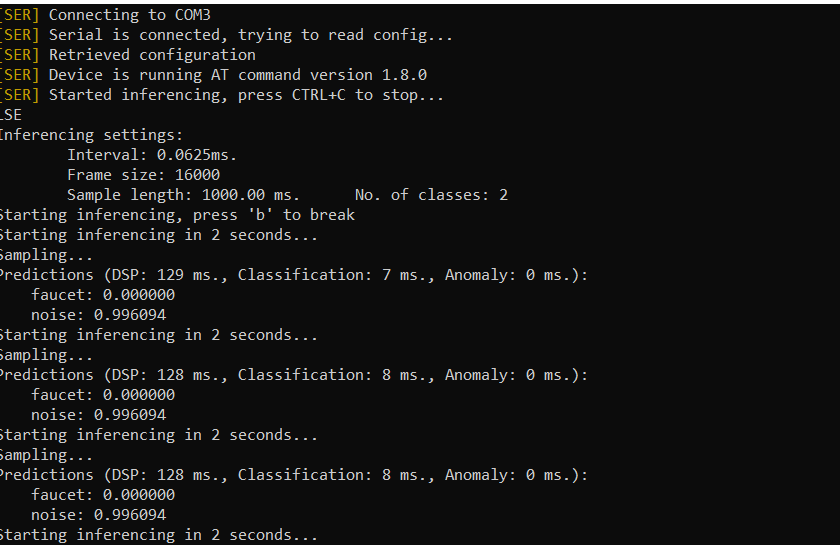
I am able to get to the end of the tutorial and design, train, and verify the impulse using the CLI, and the model works well. However, once I try deploying the binary to my dev board (the SiLabs xG24 Dev Kit), the model no longer works. Every sound is classified as noise with the same certainty no matter what sound I give it. Does anyone have any idea how to fix this?
I am not certain how this dataset was collected.
I would suggest you try to add some data that you collect with your SiLabs xG24 kits (noise and faucet). The microphone and sensibility on this board might be different from the one that has been used to collect the dataset.
Then retrain the model, it should be able to generalize easily.
One tip. You can you the Data Explorer to visualize how your new data is clustered. I believe the newly collected data samples will not belong to the existing clusters. Retraining the model will adjust the weights of the neural network to take into account your new data samples .
Thanks for your response! I did train the model on data collected on the microcontroller itself. The model works in live classification as well – when I use the microcontroller’s microphone to test new data. It is only when I deploy my model to the microcontroller using the binary that the results become incorrect. Would you have any insight on how this issue might be approached?