Hello,
Could you explain what the Image size settings do in relation to how the object detection works.
On the Studio it says “For optimal accuracy with transfer learning blocks, use a 96x96 or 160x160 image size”, does this mean that the largest image I can feed into the detection process is an image of size 160x160, or does it mean that if I feed in an image of say 640x640 the image will be resized down to 160x160 or 96x96, or does it mean that the image detection algorithm will analyze my images in blocks of 96x96 or 160x160 and therefore I should ensure that my input image is a multiple of those values ?
My main concern is that some of my images will loose all the detail I am trying to detect if they are resized down to such a small size.
Thanks.
The Image Data Block Width and Height of the Impulse is what your images will get resized to. You can feed larger images to the Impulse.
I think you’ll be surprised at how well the Model works. I fed a FOMO with 640x640 raw images with the Impulse set to 96x96 and had great results.
As @ MMarcial mentioned the image height, width specified during the Impulse creation refers to how images are rescaled before training and, by default, during inference. I say by default during inference because inference can actually run at any resolution, as long as the pixel size of the objects stays the same.
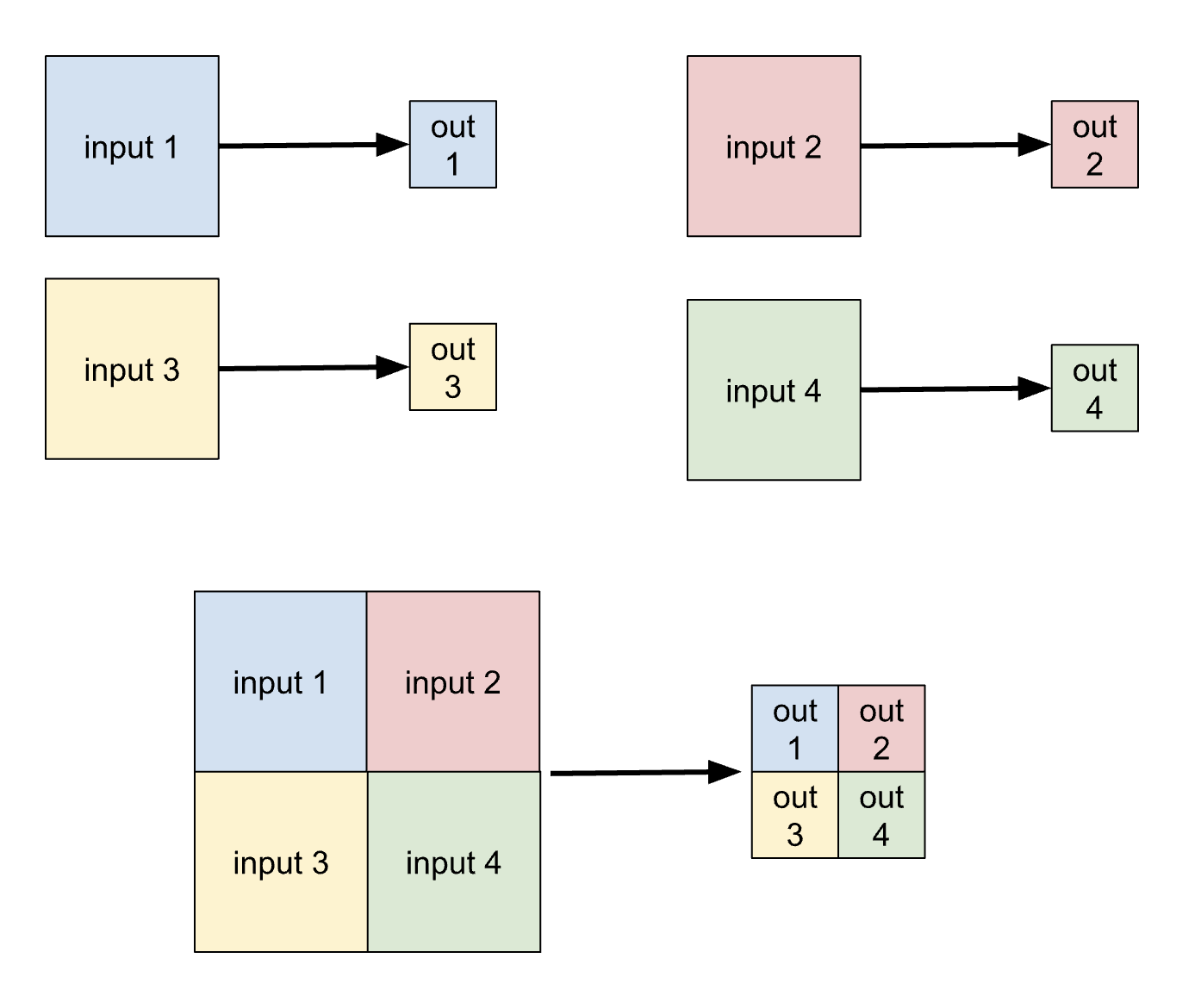
e.g. if you trained at 160x160, FOMO would output 20x20. you could then take 4 of your input images, paste them together in a square of 320x320, run that single image through the trained model and you’d get a 40x40 output that would be equivalent to running the 4 inputs individually ( though, there would be some small boundary effect possibly)
but you’re right to be concerned about resizing, it could be destructive…
for your use case; how big ( in pixels ) are the objects you’re interested in detection? & how big are the original images? if need be we can help with some customish patching
mat
2 Likes
Disclaimer for my comment, I’m new to this.
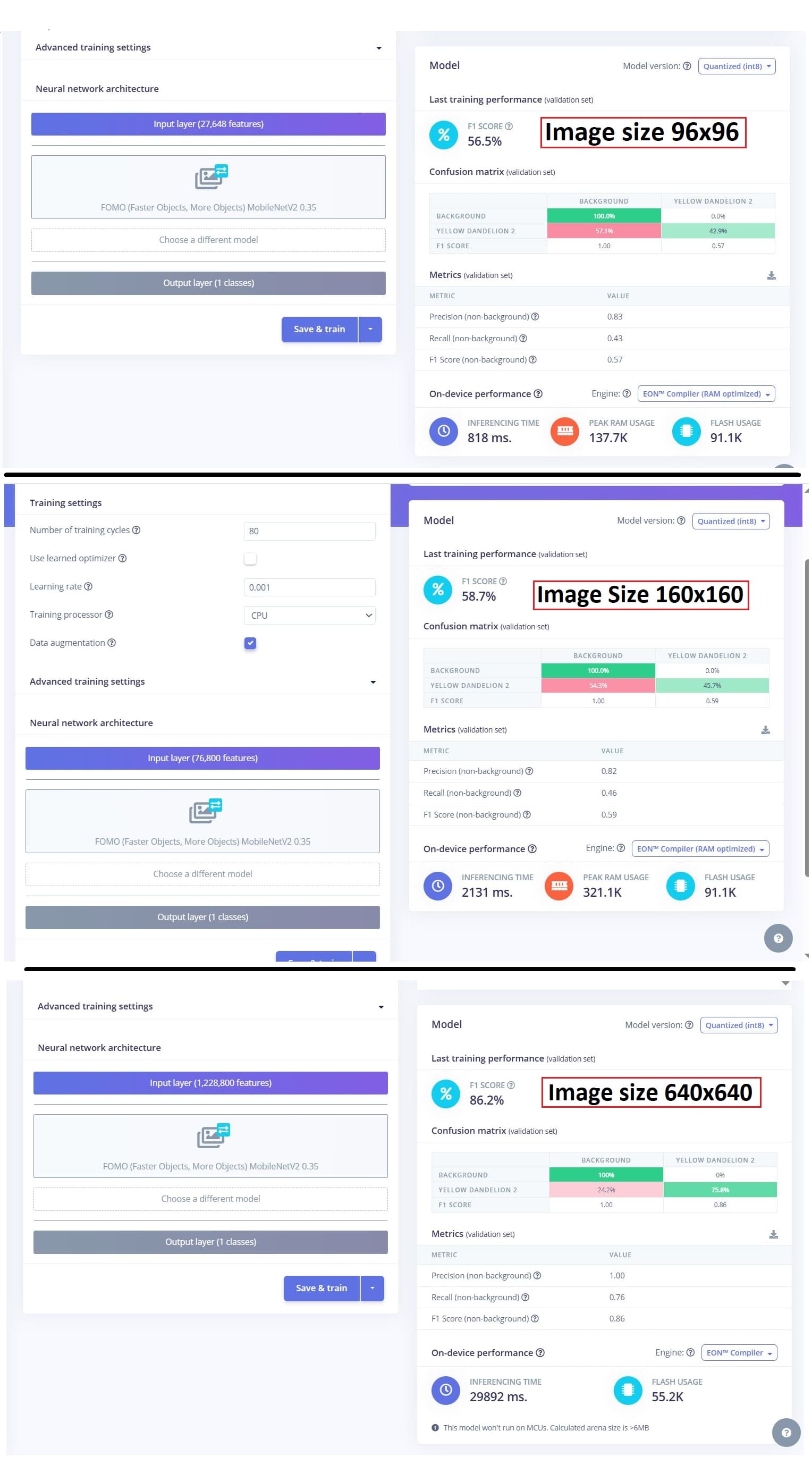
Larger image size gives me better image detection results but also ended up making it too big for a micro-controller. Here are screenshots of my results. The only thing I changed is the image size in the ‘impulse’ block