Hi,
I have got a question about the default image classification task code that is generated (Python) by Edge Impulse.
Looking at the code, I do not see any scaling of the input data. Mobilenet requires the input (images) to be scaled between -1 and 1. This is the function, I usually call in my notebooks.
BTW it seems that during training somehow the input is scaled because the accuracy grows quickly, I think this is true also when evaluating the model against the test set.
I am not sure if the library you can then download (the Arduino one) runs this preprocessing step automatically, as I see bad performances in real-time and I suspect that the input is not scaled before giving it to the classifier.
Any clue?
Thanks
Hi @edge7,
That’s a great question! During training we scale pixel values to between 0 and 1 before they get to the model—you can test this by adding these lines to your Expert Mode code, which will print the max and min pixel values for each image:
for (data, label) in train_dataset.as_numpy_iterator():
print(np.max(data))
print(np.min(data))
We should be doing the same in our embedded SDK, but I’ll double check with our embedded team just to make sure!
Warmly,
Dan
Hi, the scaling code on device is here: https://github.com/edgeimpulse/inferencing-sdk-cpp/blob/00ea7959186db936606a5d67ab4c1e0290de6cce/classifier/ei_run_dsp.h#L1340 
Hi guys,
am trying to understand why cannot run inference successfully through the model generated by your (great) platform, while I have been able to make it work doing everything from scratch (notebook and tensorflow lite)! Am using an ESP32 but that is not important I think.
Let me give you more info and some suggestions.
Each model might have a slightly different preprocessing phase, for instance, the mobile net:
Note: each Keras Application expects a specific kind of input preprocessing. For MobileNetV2, call tf.keras.applications.mobilenet_v2.preprocess_input on your inputs before passing them to the model. mobilenet_v2.preprocess_input will scale input pixels between -1 and 1.
More info here. I think this should be made evident and clear to the user, If a user opens the ‘expert’ mode means he\she has knowledge about what is doing so would probably have this step clear. Also, scaling between 0 to 1 even though might work for most the use cases might not be the best option for all the networks.
This is how am doing that in my notebook:
inputs = tf.keras.Input(shape=(96, 96, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
where: preprocess_input = tf.keras.applications.mobilenet.preprocess_input
Doing so, the model already includes such a preprocessing step, which is also easy to see in the model summary:

Please note the truediv and subtract operations, (in this case they mean: /255.0 -1) they get also included in the tensorflow lite model itself, so there is no need to add more C++ code for doing that. This decouples C++ from the model itself (hope this makes sense).
Can you also add a model summary picture somewhere? It is easy to include in your UI.
Let me also show you some parts of the C++ project am running in my ESP32 which am sure has good performance as it is working live for 1 month now.
The entry point of the processing part is here:
GetImage(error_reporter, kNumCols, kNumRows, kNumChannels,
input->data.int8)
where input is input = interpreter->input(0);
The most important code is then:
ESP_LOGI(“IMAGE PROVIDER”,);
void *ptrVal = NULL; // create a pointer for memory location to store the data
uint32_t ARRAY_LENGTH = fb->width * fb->height * 3;
printf(“Array Length %d”, ARRAY_LENGTH); // calculate memory required to store the RGB data (i.e. number of pixels in the jpg image x 3)
ptrVal = heap_caps_malloc(ARRAY_LENGTH, MALLOC_CAP_SPIRAM);
if(ptrVal == nullptr)
ESP_LOGE(“IMAGE PROVIDER”, “Unable to allocate”); // allocate memory space for the rgb data
uint8_t *rgb = (uint8_t *)ptrVal; // create the ‘rgb’ array pointer to the allocated memory spaceESP_LOGI(“IMAGE PROVIDER”, “ALlocated”);
// convert the captured jpg image (fb) to rgb data (store in ‘rgb’ array)
bool jpeg_converted = fmt2rgb888(fb->buf, fb->len, PIXFORMAT_JPEG, rgb);
if (!jpeg_converted) ESP_LOGE(“IMAGE PROVIDER”," -error converting image to RGB- ");
ESP_LOGI(“IMAGE PROVIDER”, “Converted”);
int MODEL_IMAGE_WIDTH = 96;
int MODEL_IMAGE_HEIGHT = 96;
int NUM_CHANNELS = 3;
int img_size = MODEL_IMAGE_WIDTH * MODEL_IMAGE_HEIGHT * NUM_CHANNELS;
uint8_t * tmp_buffer = (uint8_t *) malloc(img_size);
image_resize_linear(tmp_buffer,rgb,MODEL_IMAGE_HEIGHT,
MODEL_IMAGE_WIDTH,NUM_CHANNELS,fb->width,fb->height);
ESP_LOGI(“IMAGE PROVIDER”, “COPIO PER MODELLO”);
for (int i = 0; i < img_size; i++) {
image_data[i] = (int8_t) ((int) tmp_buffer[i] - 128);
}
A couple of notes there: am using SPIRAM in ESP32, a useful feature to increase my memory space.
The rest of the code is similar to yours, the only thing is that image_data is expecting int data and not uint so I subtract -128.
Please note my get_input_details for the model I generated:
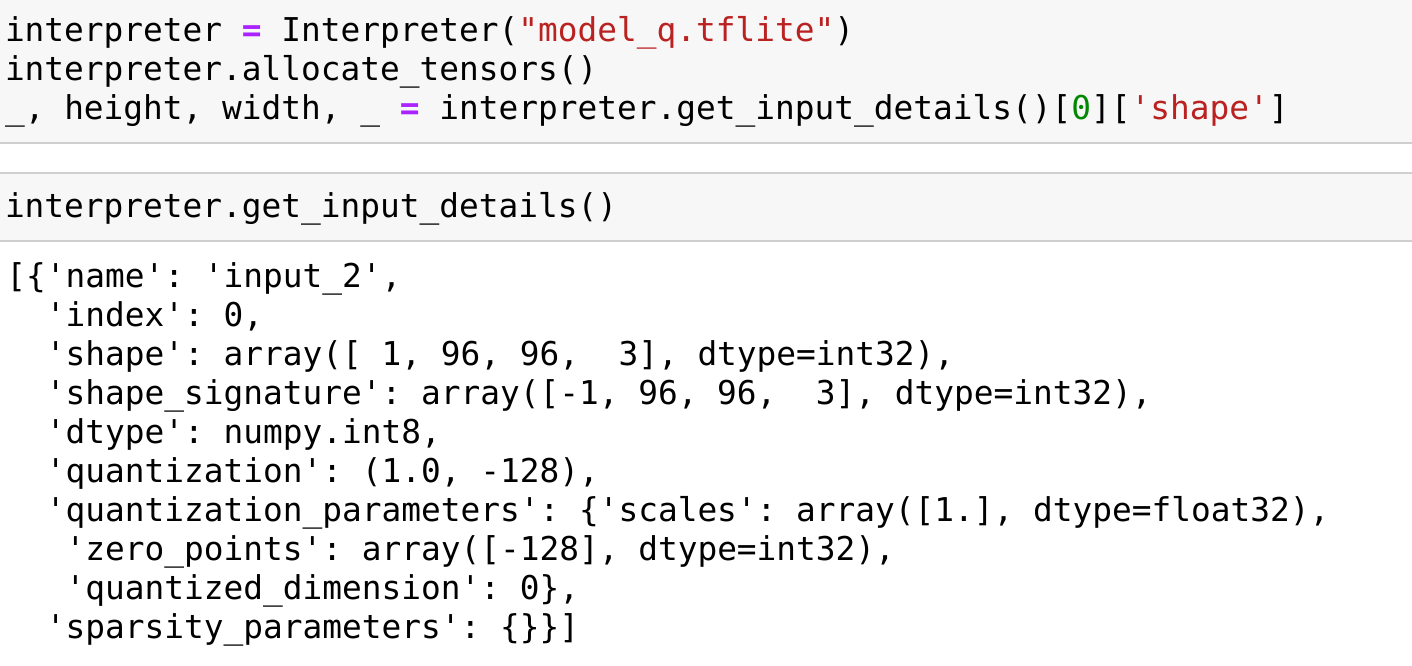
as you can see RGB 96,96 the quantization is scale 1 (so nothing), offset -128 (which I applied just above).
Then this is the way I get the output:
// Run the model on this input and make sure it succeeds.
if (kTfLiteOk != interpreter->Invoke()) {
TF_LITE_REPORT_ERROR(error_reporter, “Invoke failed.”);
}TfLiteTensor* output = interpreter->output(0); // Process the inference results. int8_t no_gat_score = output->data.int8[0];
and that’s it, it works fine I run image classification fine with my ESP32.
Unfortunately, the EDGE Impulse one always recognises the same class.
Hope this helps.
still diving in:
I found (for my project):
#define EI_CLASSIFIER_TFLITE_INPUT_SCALE 0.003921568859368563
#define EI_CLASSIFIER_TFLITE_INPUT_ZEROPOINT -128
not sure why the input scale is so low.
Looking then at this code:
float r = static_cast(pixel >> 16 & 0xff) / 255.0f;
float g = static_cast(pixel >> 8 & 0xff) / 255.0f;
float b = static_cast(pixel & 0xff) / 255.0f;
if (channel_count == 3) {
output_matrix->buffer[output_ix++] = static_cast<int8_t>(round(r / EI_CLASSIFIER_TFLITE_INPUT_SCALE) + EI_CLASSIFIER_TFLITE_INPUT_ZEROPOINT);
output_matrix->buffer[output_ix++] = static_cast<int8_t>(round(g / EI_CLASSIFIER_TFLITE_INPUT_SCALE) + EI_CLASSIFIER_TFLITE_INPUT_ZEROPOINT);
output_matrix->buffer[output_ix++] = static_cast<int8_t>(round(b / EI_CLASSIFIER_TFLITE_INPUT_SCALE) + EI_CLASSIFIER_TFLITE_INPUT_ZEROPOINT);
}
r,g,b should be after your manual scaling between 0.0 and 1.0.
after applying the classifier input scale they should become between 0 and 255 again (1/0.003921568859368563 is circa 255). and then finally adding the zero point, they should be between -128 and 127, which is my starting point. The difference is that, as I shown above, I have got the actual scaling required by my model embedded in my model itself via tensorflow operations…
