Whenever the image gets captured and passed on for the inference, the results of the edge inferenced image drastically varies when running the same image for inference on the web.
My deployment target is ESP32-CAMERA (Ai-Thinker) which is running FreeRTOS (ESP-IDF).
The images used to train the model are not only from the ESP32-CAMERA, but also from some other camera sources like the mobile phones, and open images.
Does it really matter to train the model with the target devices’ camera?
Does it really matter to train the model with the target devices’ camera?
Haven’t seen a response to this yet and it wouldn’t make sense that the images need to come from the camera only as this would imply that using images from the extensive collection of images available from different sources are worthless.
It should not matter much if you have a good dataset.
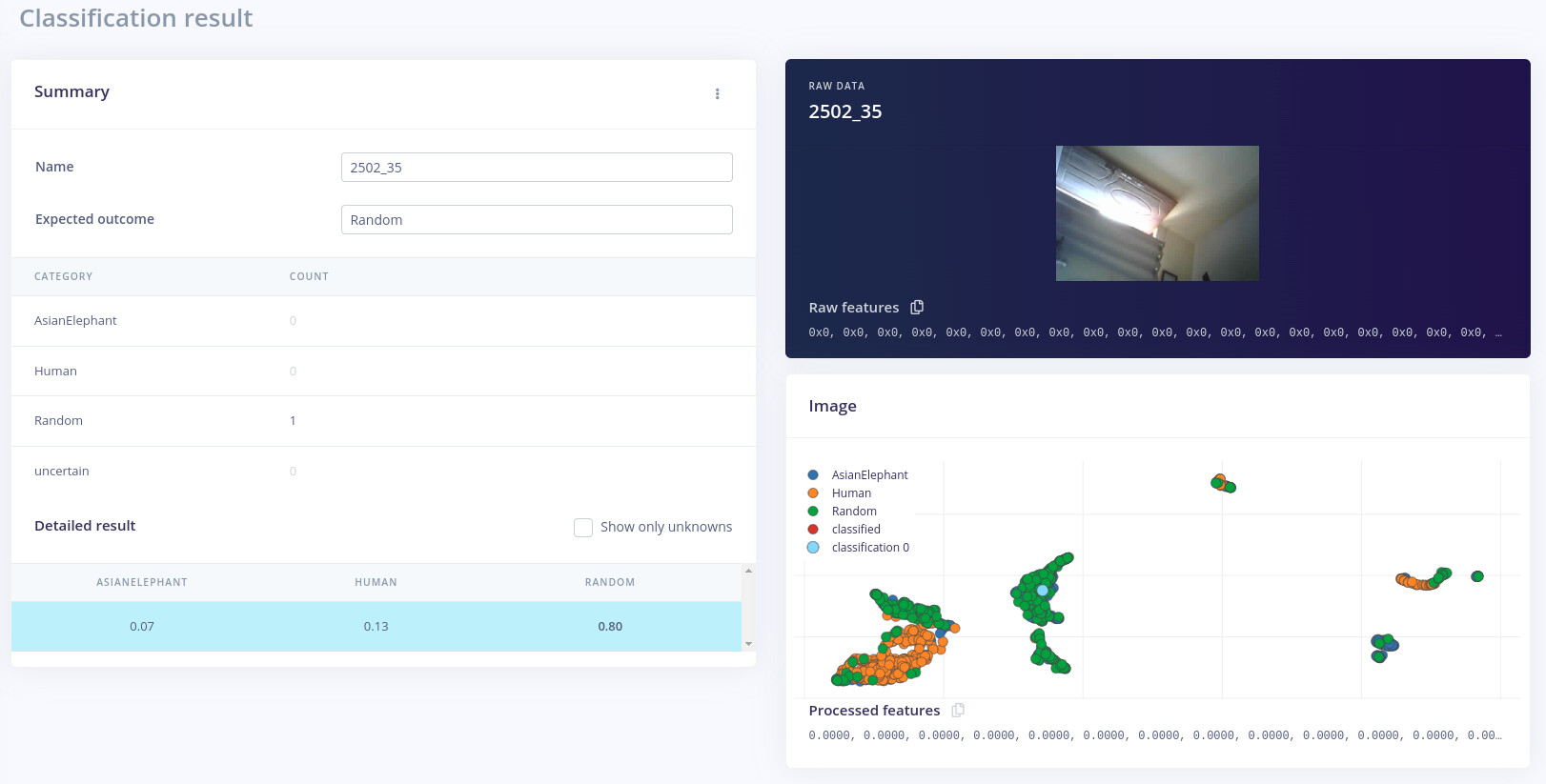
If you have a close look at this image:
You can notice a small line on the upper part of the image. If you have data samples in your dataset of human containing that small line, your NN will likely learn that feature.
Same apply for an image that is too bright or too dark, etc… Those are features a NN can learn.