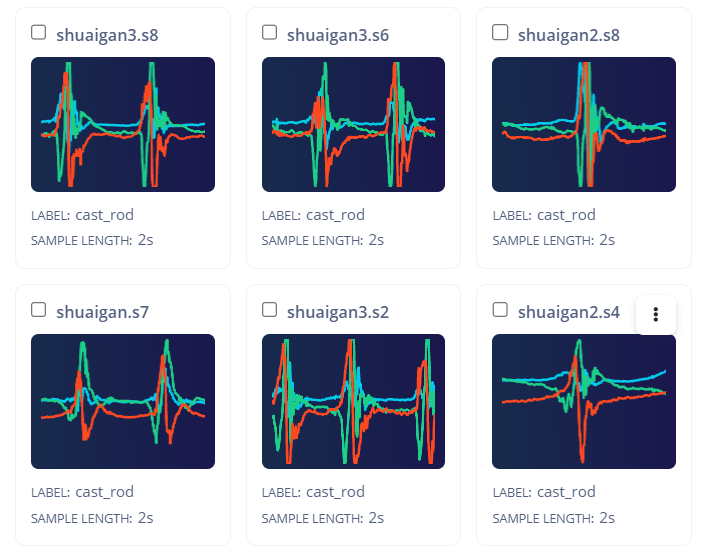
I collected about 20 seconds of accelerometer sensor data and segmented it into 2-second samples using a time-series CSV template. However, I found that the number of actions within each sample is inconsistent — as shown in the image I uploaded, some samples contain one action, while others contain two or even three.
I’d like to know whether this kind of mixed data would affect the performance of the trained AI model. Should I instead try to make sure that each sample contains the same number of actions?
For your use-case it is worth considering what your model will encounter in the real-world. In a given 2 second window is it likely that the user is going to perform the action multiple times? If so then represent this in the dataset like you have. If you’ll only ever see a single action then collect data based on that. In your case, is it likely someone is going to cast their rod twice or 3 times in 2 seconds? If not then perhaps focus on single samples.
The goal with data collection is to create a dataset that accurately represents all the things your model will see in the real world, both what you want to detect, but also crucially what you don’t want to detect. Background labelling is just as important.
I reccomend reading the dataset chapter of the book AI at the Edge, which some of our team wrote, it’s a great primer on this topic. You can get a free PDF download here: Edge AI - AI at the Edge eBook