Question/Issue:
Hi all,
I’m currently working on improving the accuracy of a wake word model (“Wil”) that I created using the initial walkthrough when setting up my Edge Impulse account. During that process, I followed the prompt to record around 38 seconds of audio samples containing the wake word.
After completing the walkthrough, I received a trained model, but the recognition accuracy is currently around 6 out of 10. So I understand that to improve it, I need to retrain it with more samples. Here’s what I did:
What I did so far:
- I went to “Data Acquisition” → “Upload data”, and uploaded a folder named
wake_wordsthat contains ~600.wavsamples (both positive and negative). - Then, I went to “Transfer Learning” and clicked “Save & Train” to start training on the new data.
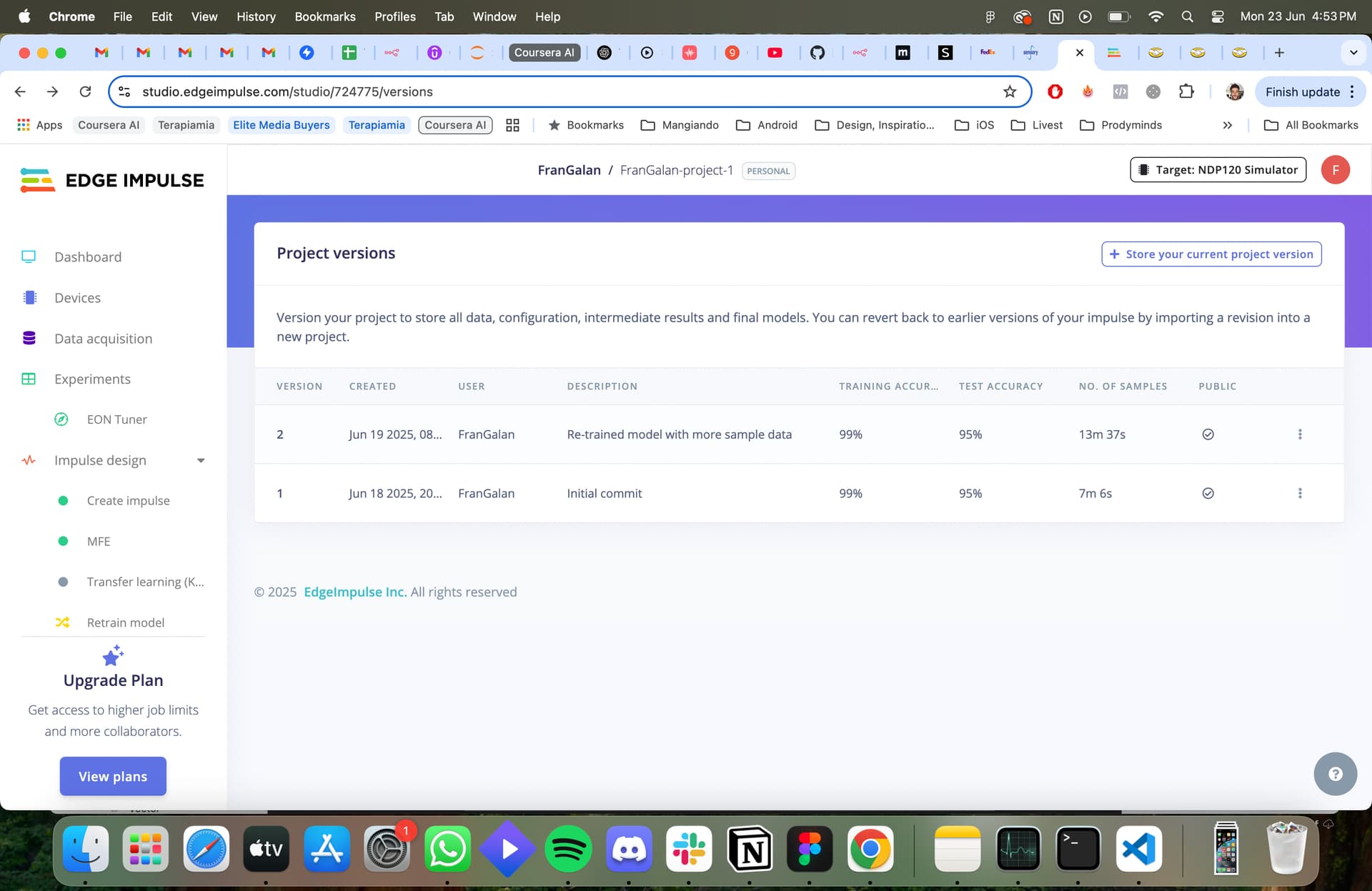
- I visited the “Versioning” tab and created a new Project Version. The original (from onboarding) had ~7 minutes of training data, this new version has ~13 minutes.
My questions:
a) Is this the correct procedure?
Am I missing any important step to ensure that the new data is being used effectively in training?
b) My current model size is around 500KB, and I know I can go up to 1MB.
Does increasing the model size help improve quality? If so, how can I control or adjust the model size?
c) I noticed that even after uploading more samples and training, the performance didn’t improve much.
So I tried clicking “Retrain model” on the right side panel. But the retraining failed (no clear error message was shown).
Is clicking “Retrain model” actually required after uploading new data? Or is “Save & Train” inside the “Transfer Learning” tab sufficient?
Ultimately, my goal is to improve the detection accuracy of the wake word “Wil”.
Right now, it’s missing too many activations. Any advice or guidance to improve the model performance would be greatly appreciated.
Thanks in advance!
Francisco
–
Project ID:
FranGalan-project-1