I spent at least two weeks trying to get my Nicla Voice to recognise four simple words.
I tried with samples found on the net and then recording my voice with various types of audio, from a telephone, from a webcam, with a professional microphone and sound card.
I tried adding and removing various types of noise and unknown samples, using or not using system optimisations, adjusting sample volumes and modifying pitch and speed.
Unfortunately, I was never able to make more than 3 words understood, and in a fairly approximate manner.
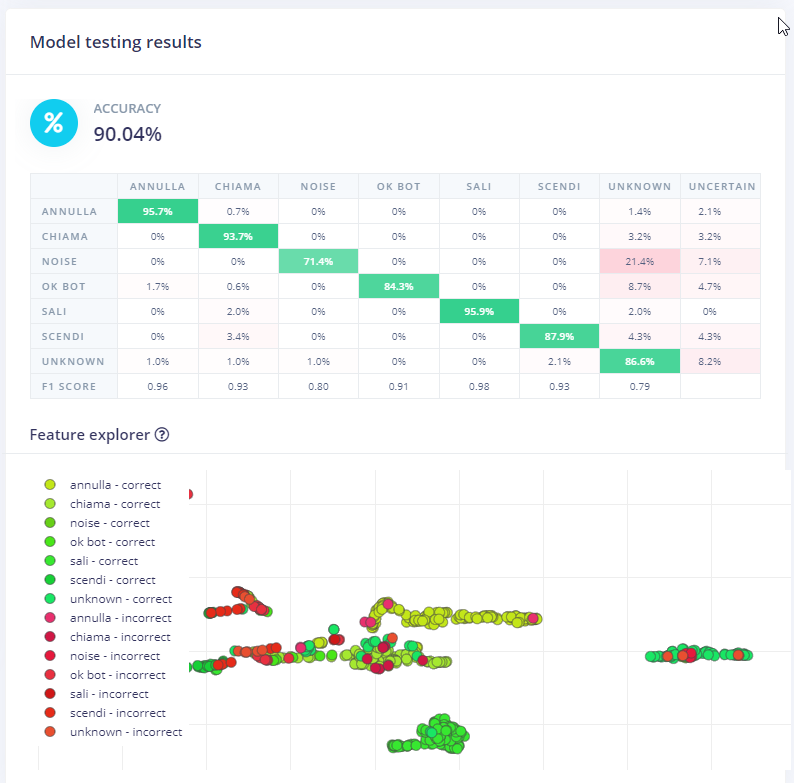
I would like to understand how to interpret the graphical and numerical results that the framework reports after the various sequences of operations, whether one can deduce from these whether a sample or a series of samples have problems and what type of problem it is.
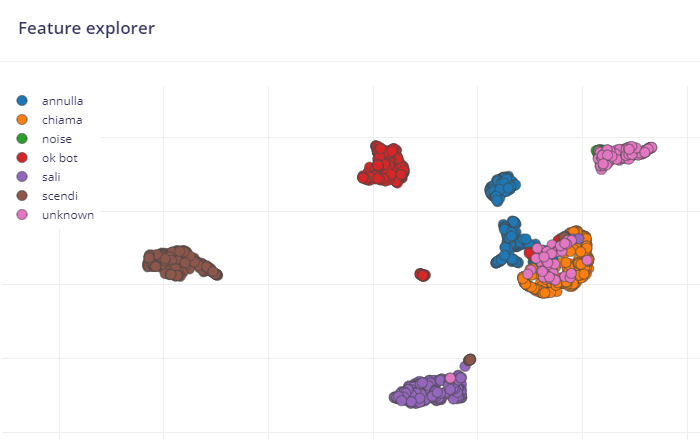
I see that some sample sets overlap graphically but I do not understand how this affects the goodness of recognition. The system reports graphical and numerical information of the efficiency of the samples but I do not know how to exploit this to optimise the system.
Thanks to anyone who wants to give me some tips.
Which graphical features are you referring to? Can you post some screenshots? That will help us identify what you are trying to do. Also, are you planning to deploy to the Syntiant board?
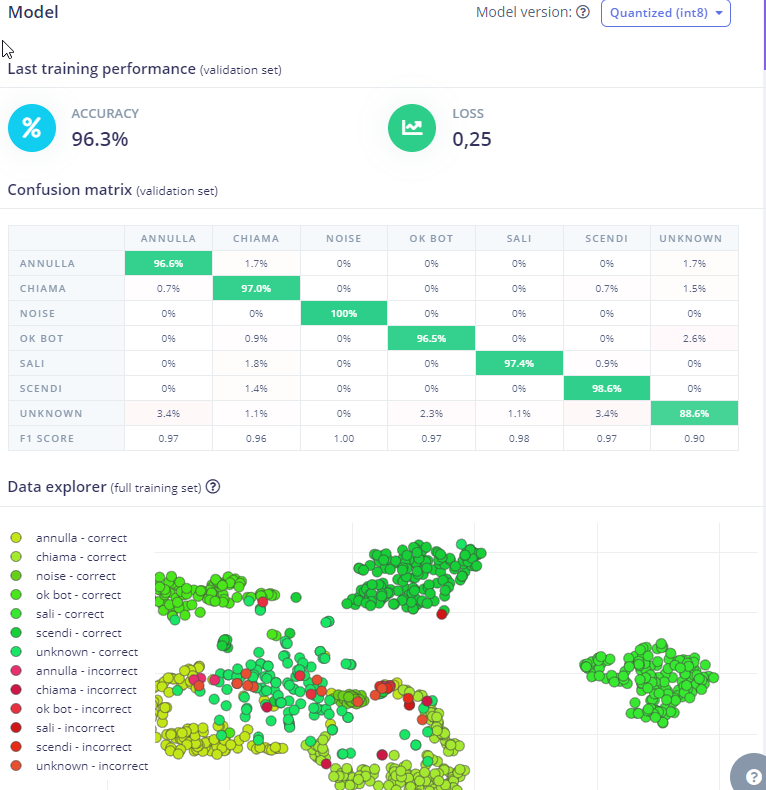
Based on what I can see from your data, it appears your model is overfitting. Most of your samples sound exactly the same. You have some variation in speed, but it’s the same speaker (you, I’m presuming) and the same background noise for most samples. You also have an unbalanced dataset much fewer “noise” samples. Try getting more noise samples (and different types of noise). My recommendation is to collect samples using the microphone found on your intended target board (e.g. the Syntiant, if that’s what you are using).
yes the voice is always mine and I realise I can’t vary it much although I have tried with audio programmes to vary the pitch and speed on some samples.
I also downloaded samples from the internet but it seemed to me that the recognition got worse. I found noise samples that seemed excessive, trains, horns, washing machines etc. with a very high volume (also the volume of the samples is not clear to me how it should be adjusted). From what I understand from the graphs is that the unknown samples are overlapping with the word samples(?). Anyway I will try to balance the dataset by adding the missing data and I will try to look at your data augmentation scripts.
The Nicla Voice allows you to record only 5sec. at a time and then requires at least 20 to download them onto the PC, furthermore I can only connect the card 1 time out of 5 unless I go to the peripherals page, disconnect the card, disconnect the USB and reconnect it, so on the second attempt usually can load. A very long process.
The first image is for performance calibration, which helps you identify what threshold to use when deploying your model.
The second and third images show confusion matrices, which are useful to determine how well your model performed on a validation set or test set after training. It can help you identify which classes your model struggles with the most (and where you might need to collect more data).
The fourth image is the feature explorer, which helps you see how much your classes are separated. If you see a lot of overlap in the dots, then your model will have a more difficult time discerning between the classes.
I have provided links to documents to help you understand each of those plots.
If you are using the Nicla Voice, then you can use the Edge Impulse firmware to help you collect data directly into your project (see this guide for more information on how to do that).
In your project, I saw that you have the Syntiant processing and Syntiant transfer learning blocks selected. Please note that those blocks will only work if you plan to deploy to a Syntiant board. You will not be able to deploy to an Arduino Nicla Voice. If you are using a Nicla Voice, I highly recommend changing your processing block to “MFE” or “MFCC” (MFCC is better for voice data) and your learning block to “Classification.”
Hi,
many thanks for your time and guidance, I will try to look into the system’s specifications in more detail.
Where you say:
In your project, I saw that you have the Syntiant processing and Syntiant transfer learning blocks selected. Please note that those blocks will only work if you plan to deploy to a Syntiant board. You will not be able to deploy to an Arduino Nicla Voice. If you are using a Nicla Voice, I highly recommend changing your processing block to “MFE” or “MFCC” (MFCC is better for voice data) and your learning block to “Classification.”
I used this configuration because otherwise I can’t find the Nicla Voice board in the Deployment-> Configure your deployment:
I deeply apologize. The Nicla Voice is actually using the Syntiant hardware, so you need to use the two Syntiant blocks you had before. I do not have a Nicla Voice, so I assumed it was using something else. You will need to re-train your model the way you had before in order to deploy to the Nicla Voice.