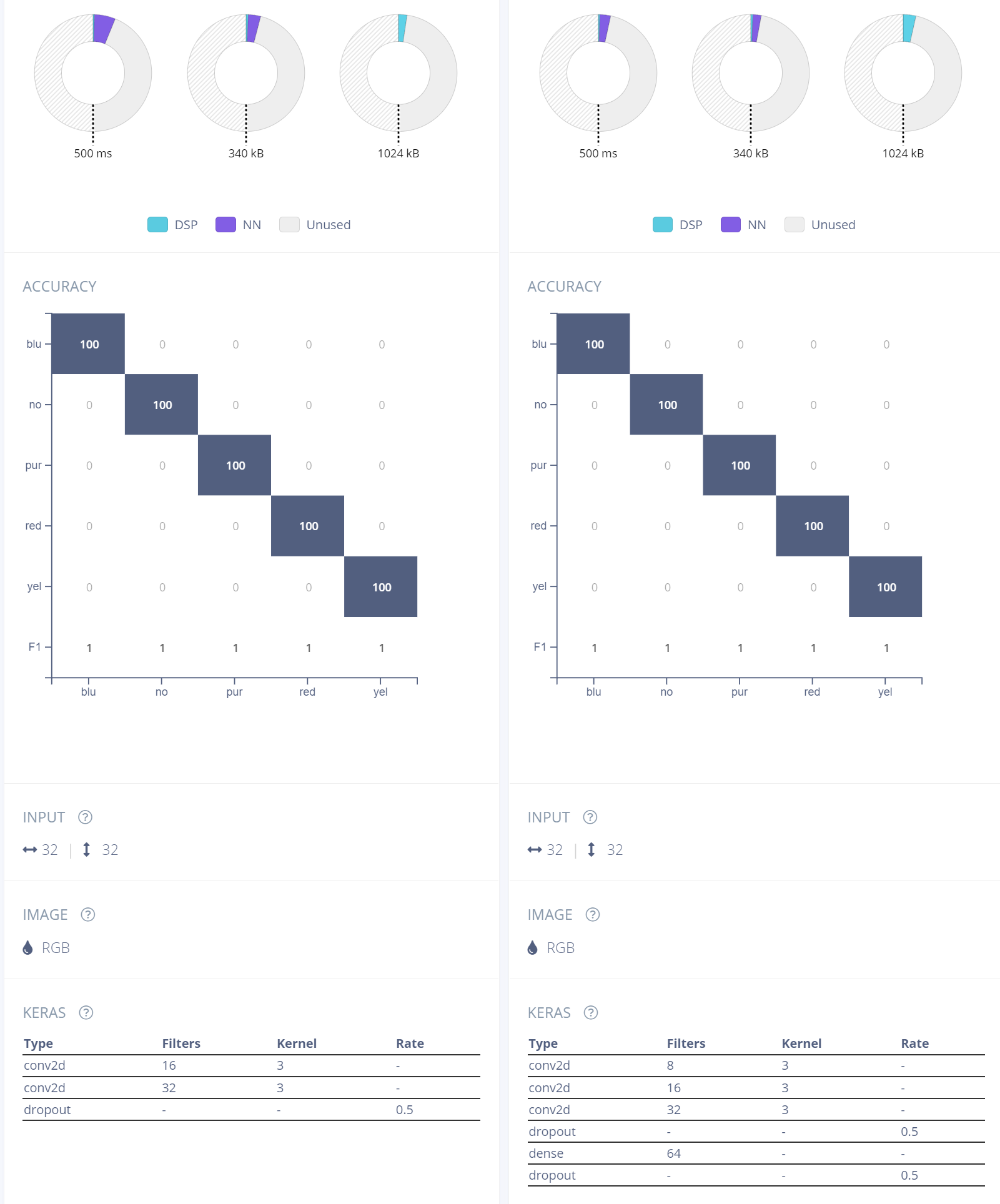
As you can see, both the models are of input size 32X32 and RGB.
The model on the left has only 2 conv layers which shows inferencing time of 58ms.
But the model on the right has 3 conv layers and a dense layer which shows inferencing time of 30ms.
The model with less layers should be faster right? Why is this different? Am I missing something?
I guess that because of the extra convolutional layers the fully-connected layer is quicker to be calculated. If I look at the estimated MACCs it’s ~800K for the model with 3 layers, and ~1.6M for the model with two layers. A bit counterintuitive indeed
Note that we’re switching to benchmarking the actual model, but this is not implemented for the Cortex-M7 216MHz target yet so it falls back to MACC calculation.
@janjongboom, thanks for the referring the blog. Do you have any script or something to check MACC calculation for various model or is it just manual calculation?
What do you mean by benchmarking the actual model? how would it differ from MACC calculation?
Hi @Ramson! Regarding compute time—as @janjongboom says, it’s not just the number of layers, it’s what’s going on inside them that makes a difference. The two-layer network ends up doing more work than the three layer one. The number of filters in the first layer is higher in the two-layer network, and these extra dimensions propagate on through the model, creating more inputs to be convolved through.
In terms of benchmarking—MACCs give us a theoretical measure of compute, but the time taken to perform different operations can vary between targets and optimizations. For example, on Arm devices there are vector extensions available that will speed up the Conv2D op—but only for certain filter and input sizes. One model may have fewer MACCs than another, but if it has differing support in optimizations on a certain target it may end up running slower.
This is why EON Tuner is so cool—it can automatically take all of this into account when designing a model!
Hi @dansitu,
Thanks for you explanation, now I understand it clearly.
And yes EON Tuner is really cool. I could experiment with different model architectures.
Waiting for EON tuner support for object detection problem as well.