Issue:
The current model accuracy is too low, only about 70%, while I need at least 95% accuracy to avoid false triggers. A 30% misclassification rate will negatively affect the user experience. I would like suggestions on how to improve the model accuracy to 95% or higher.
Project ID: 770116
Context / Use Case:
This model is used in a baby room for detecting infant crying, which triggers a light to turn on.I currently have 11,000 crying samples and 19,000 noise samples, all in 1-second windows.It’s important to note that every crying sample was manually inspected by listening through headphones to ensure it is indeed a baby cry before labeling.
First off, you’re trying the right approach in systematically changing settings to see what improves your model, but I’ve seen you haven’t tried using our EON tuner yet- this allows you to set up experiments over any parameters in the platform to see what yields the best results- running up to 10 simultaneously without needing to click through all the menus:EON Tuner - Edge Impulse Documentation
You can use the defaults if you like, or use one of your existing “Experiments” as a starting point.
Secondly I’d look at the following:
Your cry samples look “continuous” rather than discrete, and currently you have some samples which are slightly less that 1000ms long, with “Zero-Pad Data” set in your impulse design this means the samples less than 1000ms will be padded with 0s at the end until they are long enough before training, for datasets which are “continuous” rather than discrete events this can cause accuracy issues in the real world as the model learns a pattern of there being silence after a cry when there isn’t. My reccomendation would be to set your window size to the shortest sample length you have, and to turn off zero padding
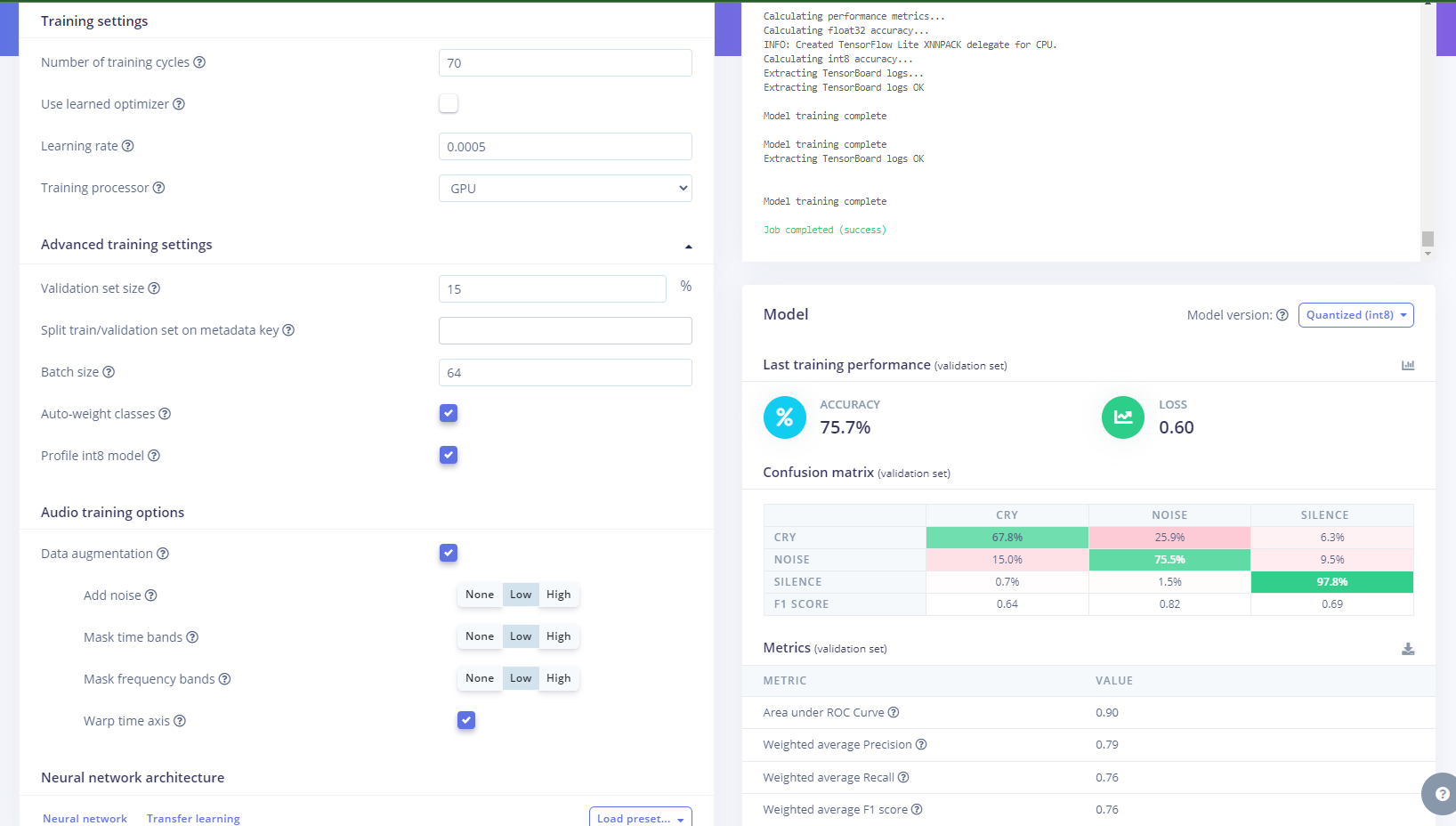
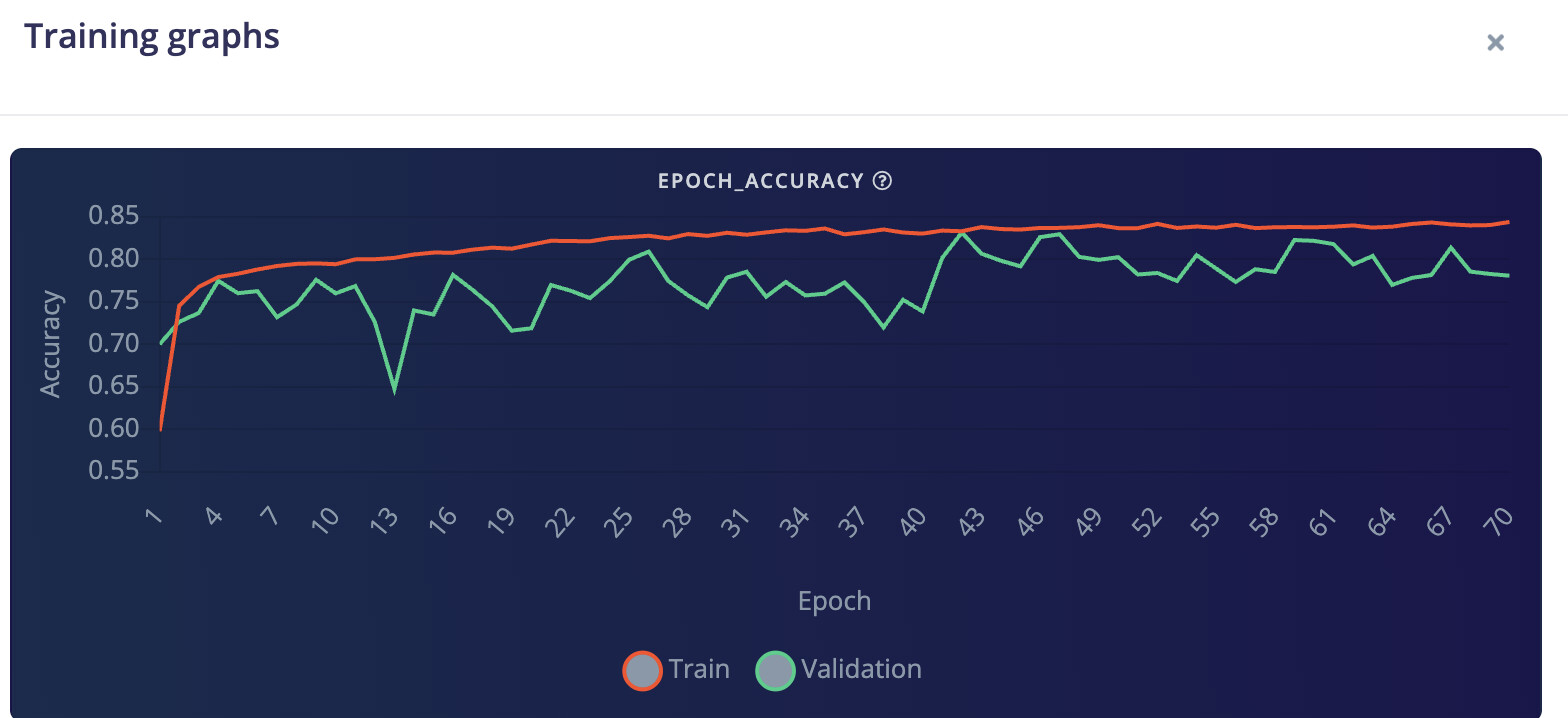
There’s a new useful feature for looking at how your model is training, in your learning block screen on the “Model” card there’s a little icon just under the quantization button which brings up Training Graphs so you can see whether your model accuracy is reaching a plateau and if your validation set accuracy matches this. If it doesn’t you may need to adjust training cycles or increase learning rate as you may be overfitting:
Try using the “Learned Optimizer” option- it may yield better results without needing to play with the learning rate yourself, as it optimizes the learning rate for you.
Try a few different processing blocks- the MFCC might work quite well as crying is a human voice noice, Spectrogram and Spectral Analysis are simpler and may yield results too.
In your processing block have you tried using the “Autotune Parameters” button to tune the DSP settings to your data? This may help.