Just trying what I believe is a simple test.
I’ve generated the same simple black and white 2D image object but at different scales and different rotations.
I am have labelled and trying to train so that the system will recognise
if the object is ‘pointing’ (rotated) to the north west segment, north, or north east
I have set up with what appears to be the standard flow. Image Data -> Image -> Object Detection
The feature generator on the image view yields what appears will be very good separation.
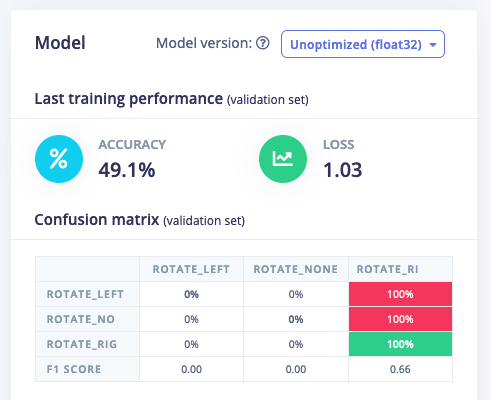
However I get poor results - 50% accuracy on 100 test units after being trained on 300 training units.
I was expecting much higher accuracy for what I thought would be a simple test case.
Data has been checked and is labelled correctly.
Just wondering if I have missed an obvious step or have made some fundamental mistake.
An example of the a training image is here.
projectid is 28319
@gjsmith My initial thought was that this would not be a good fit for any of the transfer learning blocks, as they are trained on a larger dataset of photos, and that does not translate to these abstract terms. So my guess would be to use a non-object detection flow, and select a ‘Neural network’ block instead of the transfer learning block.
However, that model does not converge either (whatever architecture I try) so I’m wondering if there’s something else here. Pinging @dansitu and @matkelcey from our ML team. F.e. result from normal image block:
Ahh facepalm. Thanks. I thought the transfer learning would work because I assumed the prior trained layers were capturing things like edges, curves and segments etc and so would be ok for transfer to my simple black and white test case. However what you are saying makes sense.
I’ll wait on comments from @dansitu and @matkelcey
Just an update:
outside of edgeimpulse framework I have managed to transfer learn the same images used here using keras/tensorflow on a VGG16 model with imagenet weights.
The results are excellent.
So I’m not sure why I cannot get the same results using the SSD model that Edge Impulse uses for this task. Something to do with the SSD model??
Sorry, sorry, I somehow missed this post from last week.
But that’s really interesting, and would love to know more if you can share it! This is the first time I’ve heard of VGG beating MobileNet so I suspect (hope?) it’s some fundamental default config difference, probably in the training loop, which is common for classification/detection on images that aren’t the “standard” ImageNet style ones…
Is your training code something easy to share? Or, if not, can you give a brief verbal description? Would like to repro both and find the gap / difference…
Hi, sorry for the delay - still experimenting with various networks etc, trying mobilenetv2 at the moment.
First, I don’t have a direct comparison to a classification - as I attempted above.
I changed to a regression problem as that more closely fits my application. I am trying to use AI to find a target pattern in the image and return the bounding box and rotation of said target.
I am getting good results by training as a regression problem that can return the bounding box and angle.
I got good results transfer learning on VGG16 trained on mobilenet data. But its way to big a network to operate on the end target - a jetson nano. Well it operates but its 5 seconds an inference!
So currently trying the exact same approach using transfer learning on mobilenetv2.
I am attaching my script (excuse the hack nature, its still a work in progress)
Also attaching a script that will generate training and test data.
I suspect that you are right and that I am getting good results probably because of the preprocessing I’m doing (in the script).
Note: this work is based off blogs from the pyimagesearch guy.
There is no way to attach files?
I will send via email
Thanks for sharing Geoff,
I see that, as you mention, you’ve simplified your case a bit to be a single detection of a single class; rather than a more general multiple instances of multiple classes; makes sense for you, and a full blown SSD might be too much.
The form of the model as you’ve described it though is still something we can run through Edge Impulse studio, you’d have to jump into Expert mode for defining and training the model, but it looks like you’d have no problem here. Let us know if you’d like help to try this…
There are a couple of things with the model you might like to consider too…
-
Do you need a pretrained model even? You might get a fair way with a subpart of one of these models
-
Are you guaranteed to have the object in every image? If not, you might need to add at a part of the output to cover P(object in image), not just the BB info.
-
MSE doesn’t always play well with a sigmoid activation (which is targeted more for probabilistic models). making that final layer a linear activation (potentially with clipping (0, 1)) might give you a better result, depending on the distribution of the location of your object.
-
you may be getting a bit of overfitting by using Flatten between the convolutional model and the classifier; you could try spatial pooling here to reduce the param count; or at the very least you may want to include dropout.
Thanks for sharing and let us know if you’re keen to port the regression form of your problem across to the studio.
Mat