I’m testing out a part detection model out on edge impulse on a Raspberry PI 3b. I’ve tested a primitive model from edge impulse on the raspberry pi and runs fine. I’m now trying to optimize the model to detect when a part has been created on a manufacturing machine. To do this im reading the power the machine is using while creating the part, a successful part will look like the picture below, 2 sets of 4 peaks evenly spaced out.
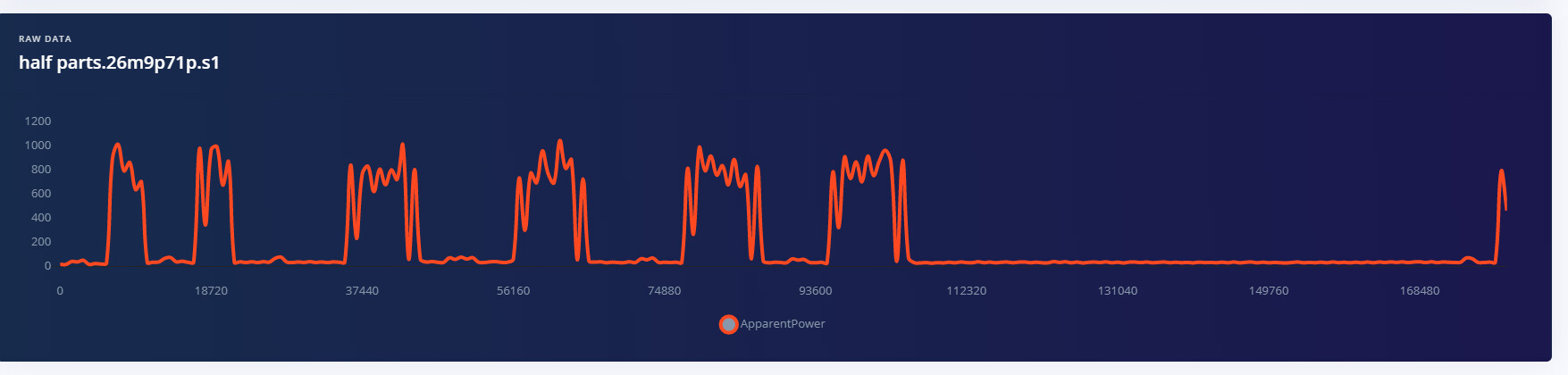
im having issues detecting full parts over half parts. The reason im feeding half parts into the training algorithm is train the model to exclude anything that isn’t a full part. An example of a half part is below, just 5 peaks rather than 2 sets of 4 peaks.
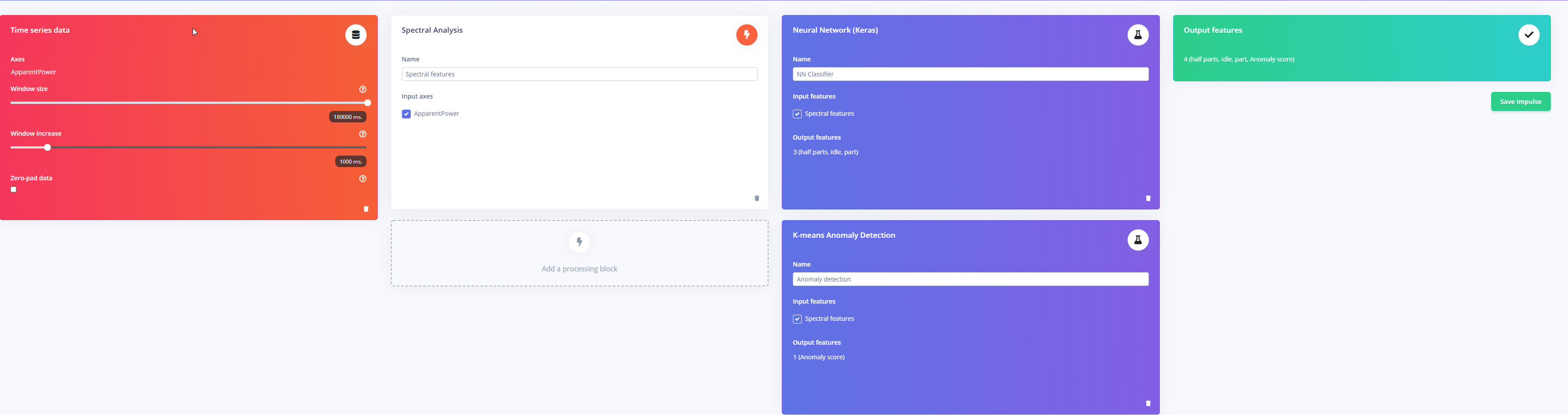
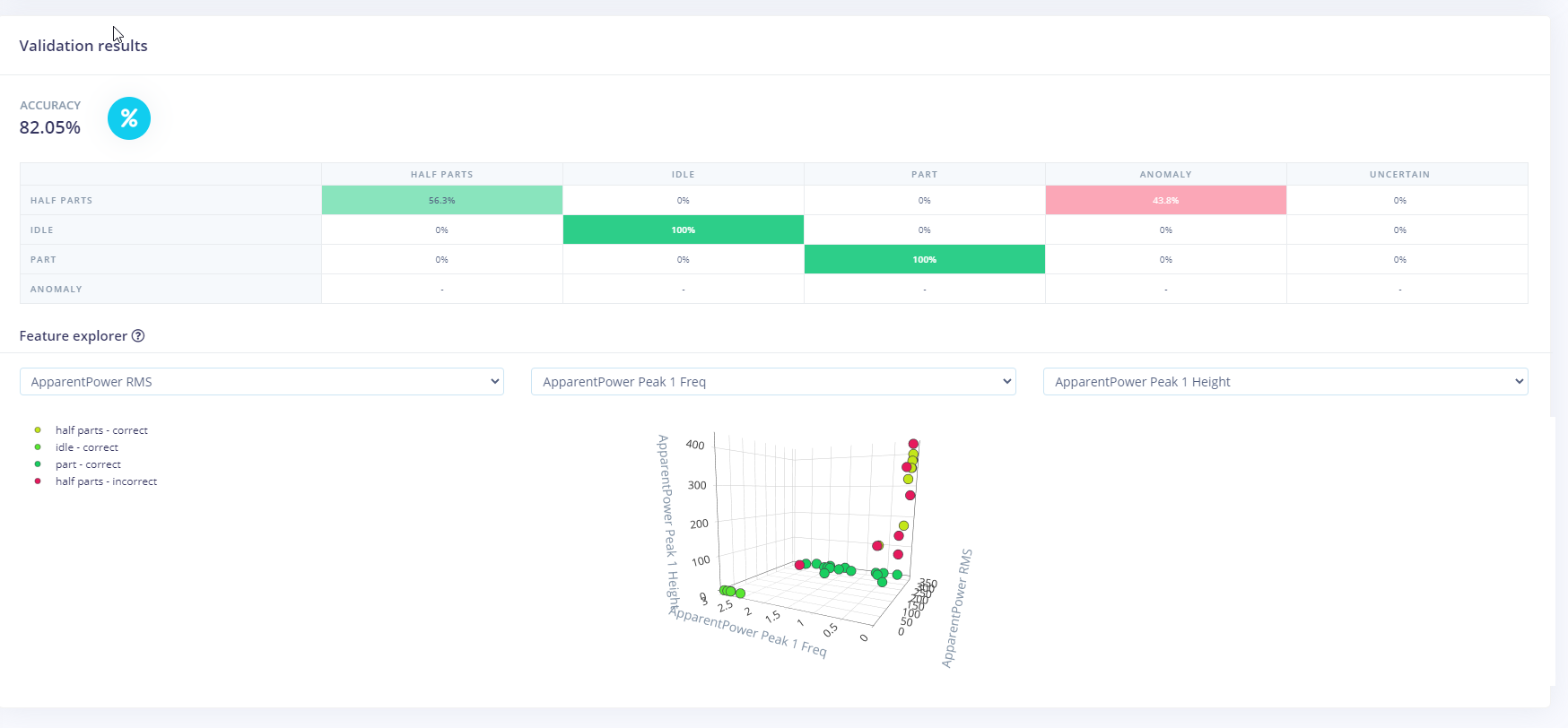
I’m not sure which algorithms would be best suited to this type of Job, so far I’ve gone for Spectral Analysis, neural network and also K-means Anomaly Detection. I was hoping the k means would help pick up any outliers as shown in the pic, maybe it will be better with additional tweaks.
The other weird thing is on the neural network, the quantized 8bit predictions are really low but on the 32bit its high. Its not a problem, because im running it on a 32bit raspberry pi processor, just thought it was worth pointing out.
After looking at your dataset, I was keen on using spectrogram instead of spectral analysis as you would get more distinct features between the different classes. I created another public project so you could see what I’ve done: https://studio.edgeimpulse.com/public/33615/latest. If you look then at the generate features tab, you will see that there appears to be some better separation in the data for the difference classes. It looks like for a full part there are normally 8 pulses, and for half parts there are 5 pulses. However, I have seen in your dataset for half parts that they are not always the same, and so then this becomes a bit of a challenge to represent half parts with a specific signature that the model is supposed to look for. It would be ideal if the half parts waveform was always front loaded with the 5 pulses first and then no activity, but then you have some other samples with pulses at the end with no activity in betweeen, etc. Hope this helps.
@yodaimpulse I’ll take a look in abit, thanks. Just out on a run. For the half parts I’ve probably not labeled them up with the best name, they are incomplete parts. For The implemented algorithm, I’m using a sliding window technique and looking out for a confidence say of above 90 that it’s a full part. The window could be passing a incomplete part which I would just keeping sliding through until a full part is predicted. Hope that makes sense, I not sure if this is the best method but it’s where I’m at the moment. Happy to here thoughts.
Also, if you are using the CLI to run your inference, by default on the Raspberry Pi, it uses the unoptimised version (the float 32) so it shouldn’t be an issue in your real life application.
Feel free to check the help:
$> edge-impulse-linux-runner --help
Usage: edge-impulse-linux-runner [options]
Edge Impulse Linux runner 1.2.5
Options:
-V, --version output the version number
--model-file <file> Specify model file, if not provided the model will be fetched from Edge Impulse
--api-key <key> API key to authenticate with Edge Impulse (overrides current credentials)
--download <file> Just download the model and store it on the file system
--clean Clear credentials
--silent Run in silent mode, don't prompt for credentials
--quantized Download int8 quantized neural networks, rather than the float32 neural networks. These might run
faster on some architectures, but have reduced accuracy.
--enable-camera Always enable the camera. This flag needs to be used to get data from the microphone on some USB
webcams.
--dev List development servers, alternatively you can use the EI_HOST environmental variable to specify the
Edge Impulse instance.
--verbose Enable debug logs
-h, --help output usage information
Probably not I was using some live data set to see what is possible with edge impulse to get familiar with the product.
I’ve already got a implementation in scipys using signal.savgol_filter to smooth the peaks and signal.find_peaks to count the 8 peaks. I thought the deep learning and signal processing might detect incomplete parts to a higher accuracy?
Ah, now I see the 5 peaks vs 2 x 4 peaks. Interesting. Maybe for this try a raw data block with a small convolutional neural network and see what it says. Anyway, if you can easily reason about data and conclusion, just writing it out typically is a lot less hassle