Hi all,
I would like to use the ultra wide camera of a mobile phone to track sport players and ball using FOMO. I believe is a good candidate, but please clarify. The camera is going to produce an image in the order of 8 to 10MP which is quite big.
First, the centroid idea is ok for me, and don’t worry if getting the centroid only, and not the bounding box. It is more of a “counting” scenario than really analytics, so I don’t need precise tracking in the sense of missing the right player ID, just to detect both of them.
The first doubt is with occlusion, as there will be quite a bit of it. I understand FOMO if the grid is not small enough, will just collapse both centroids into one of the cells, as it gives one “detection” per cell grid, right?
Second, it suggest objects to be of similar size, which is my case in one category (players), but not with the other category - ball. I understand this is not an issue as the request is for similar size within the same category, right?
I believe FOMO also supports tracking many objects. While the number of players is limited, say 20 something at most, the image might contain other people in the frame, that I guess will be detected as players too, so I guess something like 50 or maybe even up to 100 could happen (spectators). I have seen that through some modification this is doable, and I guess the mobile phone hardware will be able to cover this considering is much more powerful than your standard embedded stuff.
Now, lets say I have the model trained, how do I deploy it in an Android phone to run it, but not using the WebAssembly, but from a native Android app (say JAVA or Kotlin). I see there are libraries to port it to Python, or Go, or C++ but for Android what is the best way to do it?
Thank you very much
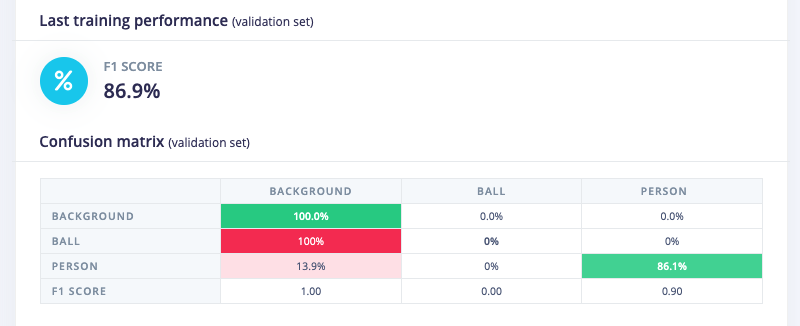
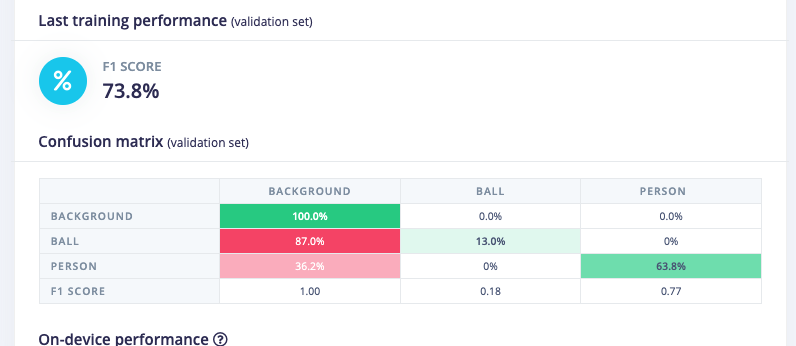
 At this moment, of the 240 images I uploaded, only 143 have the ball present (and only once per image)
At this moment, of the 240 images I uploaded, only 143 have the ball present (and only once per image)