is it possible to create with Edge Impulse an AI capable of finding a 22x22 pixel object in a 2500x3500 pixel scan?
Yes,
We have refined our model… which you can find on Edge Impulse in: “Berny /Varroa counting”.
Finally, we got a first draft under Linux x86_64: count-de-varroas-linux-x86_64-v7.eim
that we are trying to run with the following python:
import cv2
import numpy as np
import matplotlib.pyplot as plt
from edge_impulse_linux.image import ImageImpulseRunner
def my_resize(image,size):
width = int(image.shape[1] * size / 100)
height = int(image.shape[0] * height / 100)
dsize = (width, height)
output = cv2.resize(image, dsize)
return output
Loading the input image
input_image_path = “./Claude_1.jpg”
input_image = cv2.imread(input_image_path)
(‘Dimensions of the starting image:’, image.shape)
cv2.imwrite(‘final_blank_image.jpg’,blank_image) # write the file to disk
output= my_resize(input_image,25) # resize the page to 25%
cv2.imshow(‘image’,output) # print the page on the screen
plt.show() # show all images present
cv2.waitKey(0) # stop execution
Resizing the image to the size required by the template
input_image_resized = cv2.resize(input_image, (2500, 3500))
Convert image to numpy array and normalize values
input_data = np.array(input_image_resized, dtype=np.float32) / 255.0
Loading Edge Impulse template # C:\Users\berna\Documents\Jody\varroa\Edge_Impulse
model = ImageImpulseRunner(“./varroa-count-linux-x86_64-v7.eim”)
Perform inference on the image
model.start_background()
Wait for inference to complete
while not model.is_exited():
pass
Retrieving inference results
results = model. get_results()
Count of the number of detected objects
num_objects = len(results[“predictions”])
Display of the number of detected objects
print(f"Number of detected objects: {num_objects}")
++++++++++++++++++++++++++++++++++++++
unfortunately we have an error: model.start_background()
^^^^^^^^^^^^^^^^^^^^^^
AttributeError: ‘ImageImpulseRunner’ object has no attribute ‘start_background’
Where did you get the code from that is referencing model.start_background()?
The EdgeImpulse Linux SDK for Python does not use model.start_background().
See this example that shows how to classify an image using the EdgeImpulse Linux SDK for Python.
- The classification takes place via
runner.classify(features).
Hum… ChatGpt !!
if you ask : “peux-tu ecrire un script python qui prenne un fichier image en entrée, charge un modèle edge impulse et sorte le nombre d’objet trouvés”
sometime he say :
import cv2
import numpy as np
from edge_impulse_linux.image import ImageImpulseRunner
Chargement de l’image en entrée
input_image_path = “chemin/vers/votre/image.jpg”
input_image = cv2.imread(input_image_path)
Redimensionnement de l’image à la taille requise par le modèle
input_image_resized = cv2.resize(input_image, (224, 224))
Conversion de l’image en tableau numpy et normalisation des valeurs
input_data = np.array(input_image_resized, dtype=np.float32) / 255.0
Chargement du modèle Edge Impulse
model = ImageImpulseRunner(“/chemin/vers/votre/modèle.eim”)
Exécution de l’inférence sur l’image
model.start_background()
Attente de la fin de l’inférence
while not model.is_exited():
pass
Récupération des résultats de l’inférence
results = model.get_results()
Comptage du nombre d’objets détectés
num_objects = len(results[“predictions”])
Affichage du nombre d’objets détectés
print(f"Nombre d’objets détectés : {num_objects}")
ChatGPT is coming close. But like any code you get from anywhere you need to peer review it for accuracy. The EdgeImpulse example code I mentioned in my last post in this thread should solve your original mission.
Feel free to adopt this non EI code to solve your mission if your requirements force you to use start_background.sh.
Otherwise, if you desire to execute an EI solution there are copious solutions with example code at the EI Github Repository and at the EI authoritative man.
I tried your example with success, well almost, the job works but the results are not there.
I’ll send you something by zip to try.
I don’t understand: I render an image in 2500x3500 pixels and an eim made with 900 true objects and 72
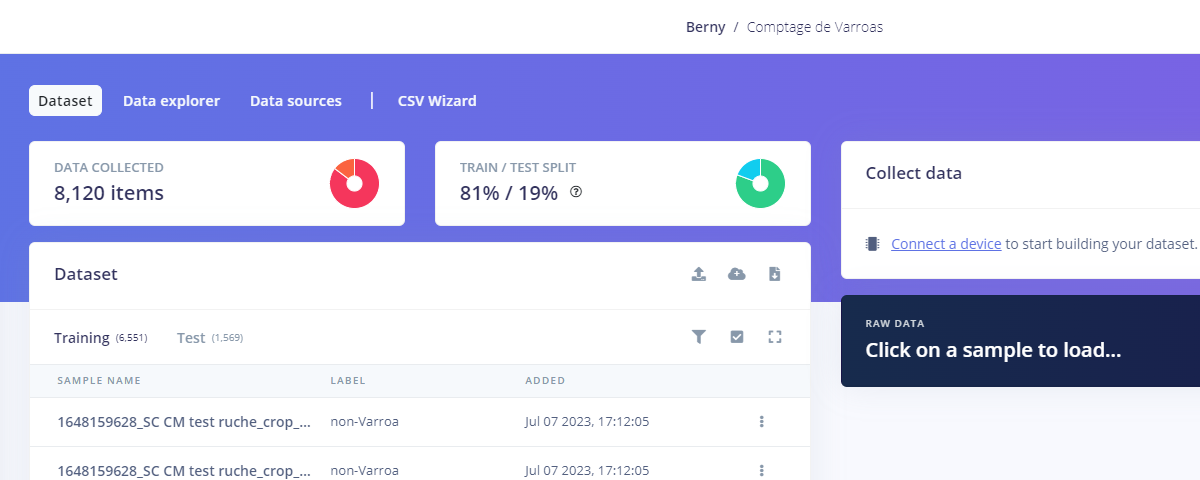
00 false objects in images of 32x32 pixels (in fact stretched 22x22x) and the debug result is a 32x32 image in not 2500x3500?
And the result is a little disappointing: only 1 “non-varroa” is detected while the base image contains a lot of “varroa” and “non-varroa”.
(sorry, I can’t find a way to send you a zip)
![]()
“debug.jpg”
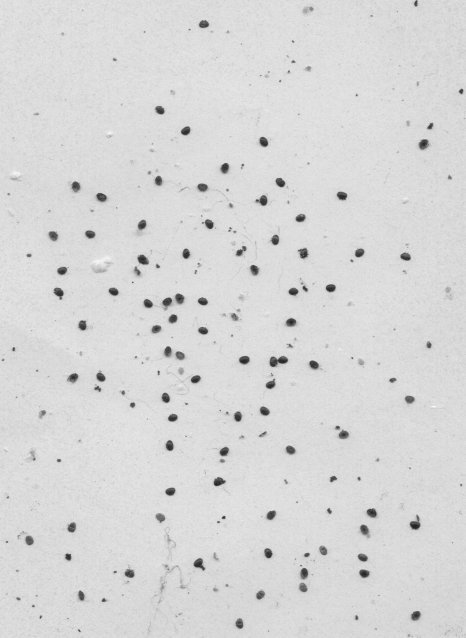
“L61.jpg” original
the job :
#!/usr/bin/env python
import cv2
import os
import sys, getopt
import numpy as np
from edge_impulse_linux.image import ImageImpulseRunner
runner = ImageImpulseRunner(“./comptage-de-varroas-linux-x86_64-v11.eim”)
model_info = runner.init()
print(‘Loaded runner for "’ + model_info[‘project’][‘owner’] + ’ / ’ + model_info[‘project’][‘name’] + ‘"’)
labels = model_info[‘model_parameters’][‘labels’]
img = cv2.imread(“./L61.jpg”)
if img is None:
print(‘Failed to load image’, “./L61.jpg”)
exit(1)
imread returns images in BGR format, so we need to convert to RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
get_features_from_image also takes a crop direction arguments in case you don’t have square images
features, cropped = runner.get_features_from_image(img)
res = runner.classify(features)
if “classification” in res[“result”].keys():
print(‘Result (%d ms.) ’ % (res[‘timing’][‘dsp’] + res[‘timing’][‘classification’]), end=’‘)
for label in labels:
score = res[‘result’][‘classification’][label]
print(’%s: %.2f\t’ % (label, score), end=‘’)
print(‘’, flush=True)
elif “bounding_boxes” in res[“result”].keys():
print(‘Found %d bounding boxes (%d ms.)’ % (len(res[“result”][“bounding_boxes”]), res[‘timing’][‘dsp’] + res[‘timing’][‘classification’]))
for bb in res[“result”][“bounding_boxes”]:
print(‘\t%s (%.2f): x=%d y=%d w=%d h=%d’ % (bb[‘label’], bb[‘value’], bb[‘x’], bb[‘y’], bb[‘width’], bb[‘height’]))
cropped = cv2.rectangle(cropped, (bb[‘x’], bb[‘y’]), (bb[‘x’] + bb[‘width’], bb[‘y’] + bb[‘height’]), (255, 0, 0), 1)
the image will be resized and cropped, save a copy of the picture here
so you can see what’s being passed into the classifier
cv2.imwrite(‘debug.jpg’, cv2.cvtColor(cropped, cv2.COLOR_RGB2BGR))
result:
ubuntu@vps-16be9656:~/essai_edge$ python3 edge_exemple_1.py
Loaded runner for “Berny / Comptage de Varroas”
Result (8 ms.) Varroa: 0.00 non-Varroa: 1.00
ubuntu@vps-16be9656:~/essai_edge$
I’d like to experiment with your project. If you can publish your EdgeImpulse (EI) Studio project by making it public. The make public button is on the EI Studio Dashboard.
Thank you for your interest in this study, which I will be happy to share with you when I get back to my computer next Monday.
I put on another post all the data: photos, program and results except the eim unfortunately.
It seems that the initial 2500x3500 photo is expanded to a square format and then reduced to the size of the original 32x32 crop!!! Would you have a complete example with initial photo and counting and documentation?
Thank you again for your work and your site which makes AI accessible to neophytes.
So, I am op !
here is the address of the published project :
h.ttps://smartphone.edgeimpulse.com/classifier.html?publicProjectId=255594
What intrigues me this photo in return ??? Why does it have to be square? How big should the original photo be?
Yes, I just (finally) did it:
h.ttps://smartphone.edgeimpulse.com/classifier.html?publicProjectId=255594
Do you have an idea of the size of the starting photo?
The approach to the problem is not correct. My advice is to start a new project and use the EdgeImpulse FOMO feature to build your model. You do not want to crop out all the Varroa into separate images. You want to draw bounding boxes around each Varroa and train on that labeled data.
FOMO will find objects within an image. FOMO divides an image into meaningful and semantically coherent regions or segments. Instead of classifying the entire image, it aims to assign a label or category to each region within the image.
Your current model is trained to classify the whole image and is called Image Classification and is classifying images into predefined classes or categories, aka, Varroa and ‘non-Varroa’.
The problem with the current approach is:
The current model expects a Varroa to look like this:

When you feed the model something like this:
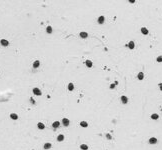
it will classify the image as non-Varroa.
So even a mere human can easily say those 2 images are very different.
ok !
There !
I made a new eim from 38 scans resized 1024x1024 and 38 Yolo.txt files,
it is called: Langes complets avec varroas et non varroas
i got an error in my job :
#!/usr/bin/env python
import cv2
import os
import sys, getopt
import numpy as np
from edge_impulse_linux.image import ImageImpulseRunner
runner = ImageImpulseRunner(“./langes-complets-avec-varroas-et-non-varroas-linux-x86_64-v2.eim”) # C:\Users\berna\Documents\Tensorflow\Edge_Impulse
model_info = runner.init()
print(‘Loaded runner for "’ + model_info[‘project’][‘owner’] + ’ / ’ + model_info[‘project’][‘name’] + ‘"’)
labels = model_info[‘model_parameters’][‘labels’]
img = cv2.imread(“./L61.jpg”)
if img is None:
print(‘Failed to load image’, “./L61.jpg”)
exit(1)
resize img en 1024 x 1024
width = int(1024/img.shape[1])
height = int(1024/img.shape[0])
dsize = (width,height)
img1024 = cv2.resize(img, dsize)
imread returns images in BGR format, so we need to convert to RGB
img = cv2.cvtColor(img1024, cv2.COLOR_BGR2GRAY) # COLOR_BGR2GRAY COLOR_BGR2RGB
get_features_from_image also takes a crop direction arguments in case you don’t have square images
features, cropped = runner.get_features_from_image(img)
res = runner.classify(features)
if “classification” in res[“result”].keys():
print(‘Result (%d ms.) ’ % (res[‘timing’][‘dsp’] + res[‘timing’][‘classification’]), end=’‘)
for label in labels:
score = res[‘result’][‘classification’][label]
print(’%s: %.2f\t’ % (label, score), end=‘’)
print(‘’, flush=True)
elif “bounding_boxes” in res[“result”].keys():
print(‘Found %d bounding boxes (%d ms.)’ % (len(res[“result”][“bounding_boxes”]), res[‘timing’][‘dsp’] + res[‘timing’][‘classification’]))
for bb in res[“result”][“bounding_boxes”]:
print(‘\t%s (%.2f): x=%d y=%d w=%d h=%d’ % (bb[‘label’], bb[‘value’], bb[‘x’], bb[‘y’], bb[‘width’], bb[‘height’]))
cropped = cv2.rectangle(cropped, (bb[‘x’], bb[‘y’]), (bb[‘x’] + bb[‘width’], bb[‘y’] + bb[‘height’]), (255, 0, 0), 1)
the image will be resized and cropped, save a copy of the picture here
so you can see what’s being passed into the classifier
cv2.imwrite(‘debug.jpg’, cv2.cvtColor(cropped, cv2.COLOR_BGR2GRAY)) # COLOR_BGR2GRAY COLOR_BGR2RGB
+++++++++++++ python3 edge_exemple_1_2.py +++++++++++++
ubuntu@vps-16be9656:~/essai_edge$ python3 edge_exemple_1_2.py
Loaded runner for “Berny / Langes complets avec varroas et non varroas”
Traceback (most recent call last):
File “/home/ubuntu/essai_edge/edge_exemple_1_2.py”, line 26, in
features, cropped = runner.get_features_from_image(img)
File “/home/ubuntu/.local/lib/python3.10/site-packages/edge_impulse_linux/image.py”, line 126, in get_features_from_image
g = pixels[ix + 1]
IndexError: list index out of range
ubuntu@vps-16be9656:~/essai_edge$
What can i do ?
Check what is being stored in width and height. I think both are being set to zero.
width = int(1024/3500) = 0
height = int(1024/2500) = 0
just a note; recall that FOMO runs fully convolutionally so can be trained at a resolution that is different to inference time, you just need to make sure that the pixel scale doesn’t change.
i.e. start with the (2500, 3500) data, sample from that a collection of (160, 160) patches. (160 being the resolution that after the 1/8th reduction is (20, 20) ~= the detection size of interest )
after training this (160, 160) → (20, 20) model it can be run with an input of (2500, 3500) which will output ~= (312, 437). note: if you want to be super strict you’d center crop the input to (2496, 3496) to ensure there’s no boundary artefacts ( i.e. 2496=312*8 )
one main reason to do this is it’ll help the stability of training ( since when we feed in large images we are effectively running with a larger batch size )
cheers,
mat
p.s. have considered doing this patching as a default thing during FOMO training, but also have been working on some large batch size optimisation which hopefully makes the problem redundant.
@MMarcial :
yes, you are right, “width = int(1024/3500) = 0” , it’s a mistake !
So I change and I live the original dimension :
// no resize img en 1024 x 1024
print('Original Dimensions : ',img.shape)
// imread returns images in BGR format, so we need to convert to RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # COLOR_BGR2GRAY COLOR_BGR2RGB
but i have the same error :
ubuntu@vps-16be9656:~/essai_edge$ python3 edge_exemple_1_2.py Loaded runner for “Berny / Langes complets avec varroas et non varroas”
Original Dimensions : (2106, 1530, 3)
Traceback (most recent call last):
File “/home/ubuntu/essai_edge/edge_exemple_1_2.py”, line 25, in
features, cropped = runner.get_features_from_image(img)
File “/home/ubuntu/.local/lib/python3.10/site-packages/edge_impulse_linux/image.py”, line 126, in get_features_from_image
g = pixels[ix + 1]
IndexError: list index out of range
@matkelcey :
I will rely on your experience with these numbers and here is my strategy:
-1- I will make a hundred test scans in 2500x3500 from a white sheet on which I will randomly throw a random number of only real varroa mites (between 0 and 20 for example), no “non-varroa”, and notify in Yolo format.
-2- I will follow your path and create an impulse with “image data” = 160 x 160 in “squash”
I should then have an impulse with good results in the “Model testing” phase on 2500x3500 scans.
Then I try on real scans.
What do you think ?
-
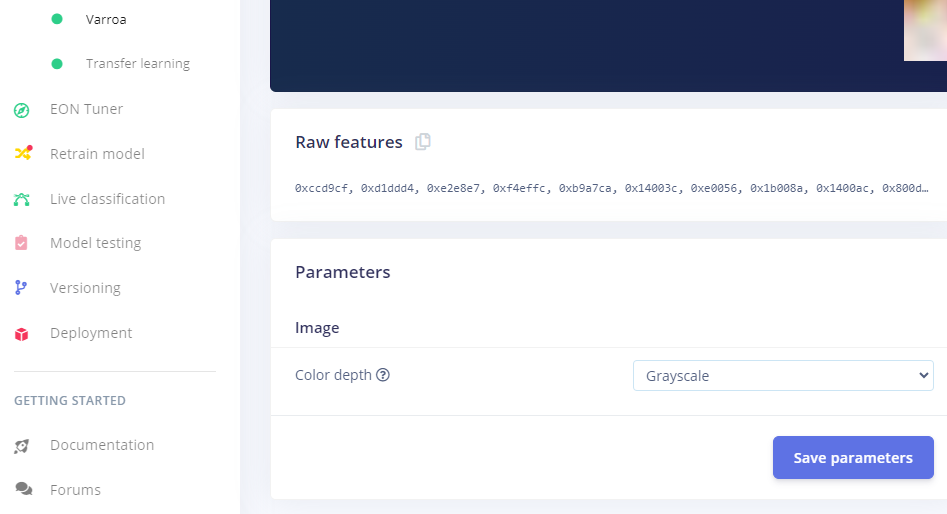
The error in
image.pyis because it thinks the model is RGB. -
Make sure the Impulse Design is set to Grayscale:
-
Then re-deploy the EIM.
For clarification you are say that we should cut up the raw image for training, correct?
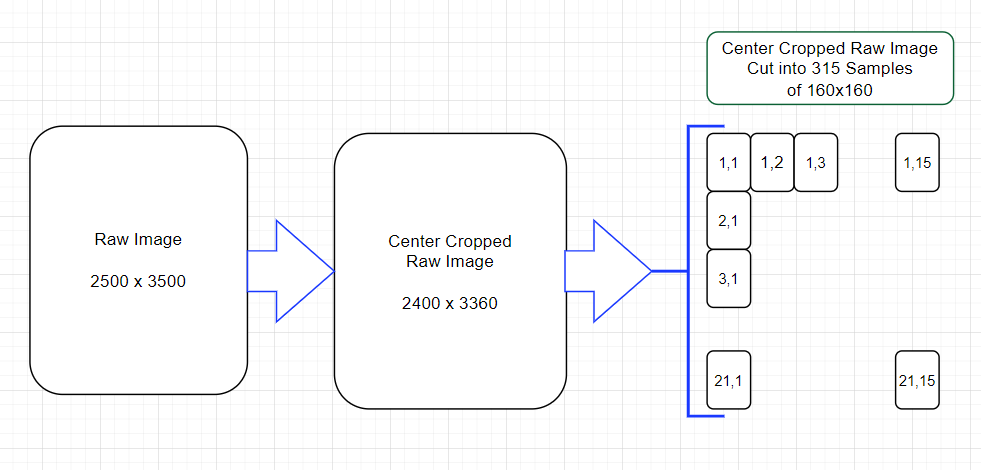
Then does the Impulse design continues to use?:
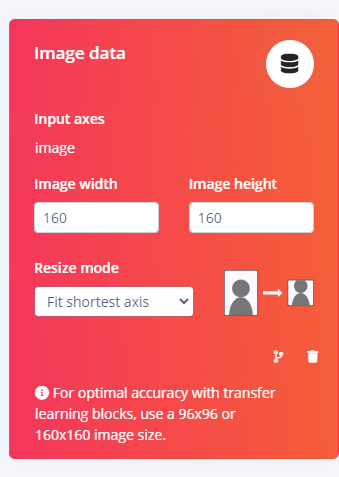
I arbitrarily centered cropped the raw image so I could get an even number of 160x160 Samples (of course there are other ways to handle this since we might be throwing away data).