I’m trying to play with the parameters of the spectrogram but I’m only able to view files of the “noise” label instead of the label containing the actual events. That is the label I uploaded first.
inspecting the dom ‘select#dsp-select-sample option’ seems like there is a hard limitation of 1000 samples? I collected ~30min of audio data. The limitation to 1000 samples doesn’t seem very practical to me.
I really like the connection from clustering visualization to samples. but without a way to tune features on all potential samples it’s not as useful as it could be.
It would still be very nice to somhow be able to filter the samples in the feature generator. maybe some checkboxes like in the samples view? I mean additionally to the select box. Or a fancy dropdown with filtering included
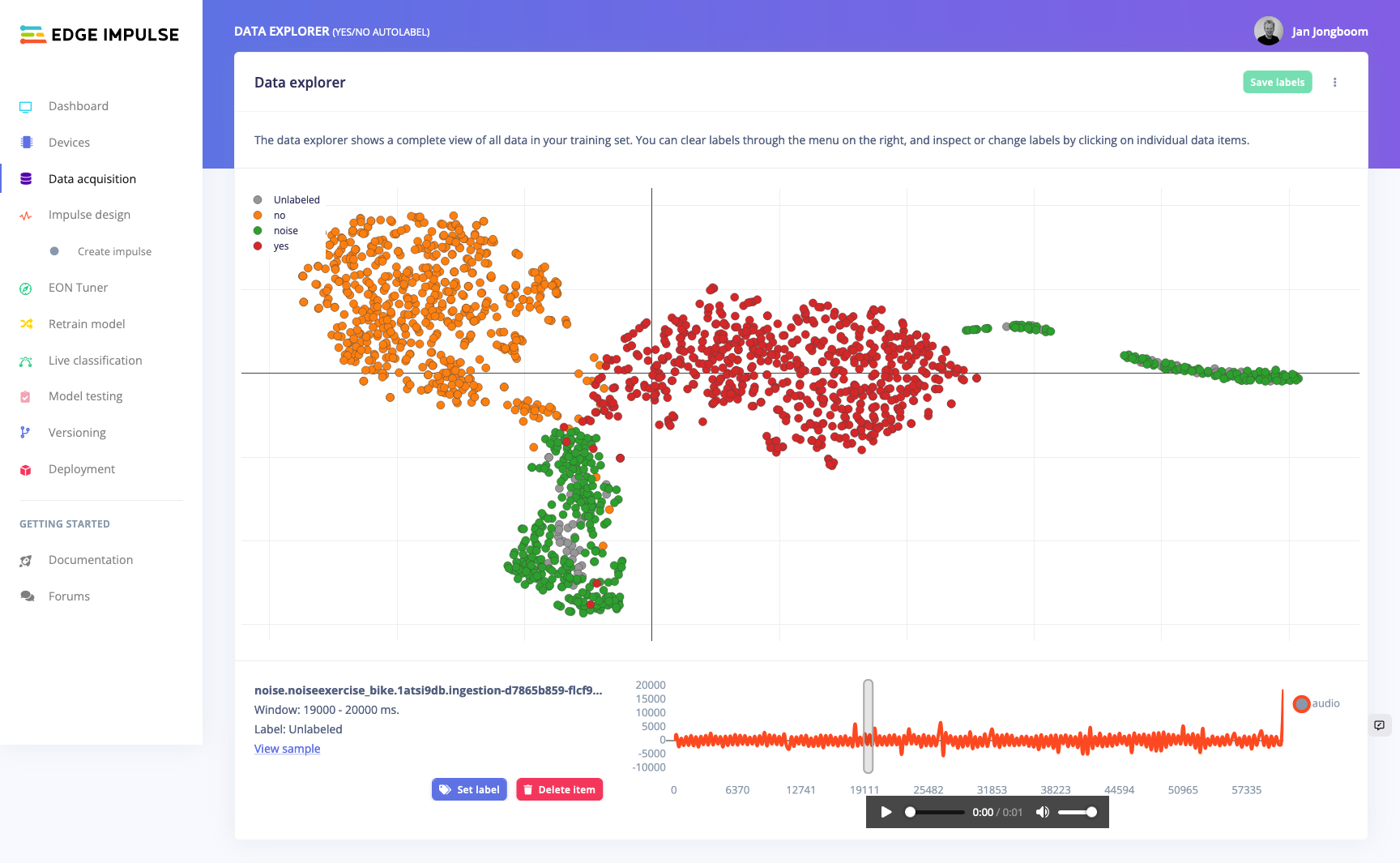
@adiibi it’s interesting though because it should select 1,000 samples at random, not the first 1,000 or something… Anyway, we are working on something cool that can do help you explore data more visually (which doesn’t have the 1K limit):
@janjongboom As far as I can tell there was no randomness to the 1000 samples in the dropdown. It looked like a sorted list of the first 1000 samples in the “first” label to me. Not sure about the ordering of labels, assume it’s the first uploaded?
Data explorer looks very interesting! What does the screen show exactly? I mean is this after feature generation on many separate samples or some kind of “generic” clustering after importing larger junks of data? I’m asking because I see a longer timeline bottom right and a number of indications like “Label: Unlabeled” or “Save labels”. It seems as the data explorer assists with labeling? How does it interact with the parameters / feature generation?
Relevant usecases for me would be large collections of mostly unlabeled audio data and also unlabeled sensor data (eg. hearbeat, pressure, thorso circumference, imu )