Hi and thanks for your reply @Eoin
Hmm. Strange. That’s exactly what i did. And i just did it again. These are the steps:
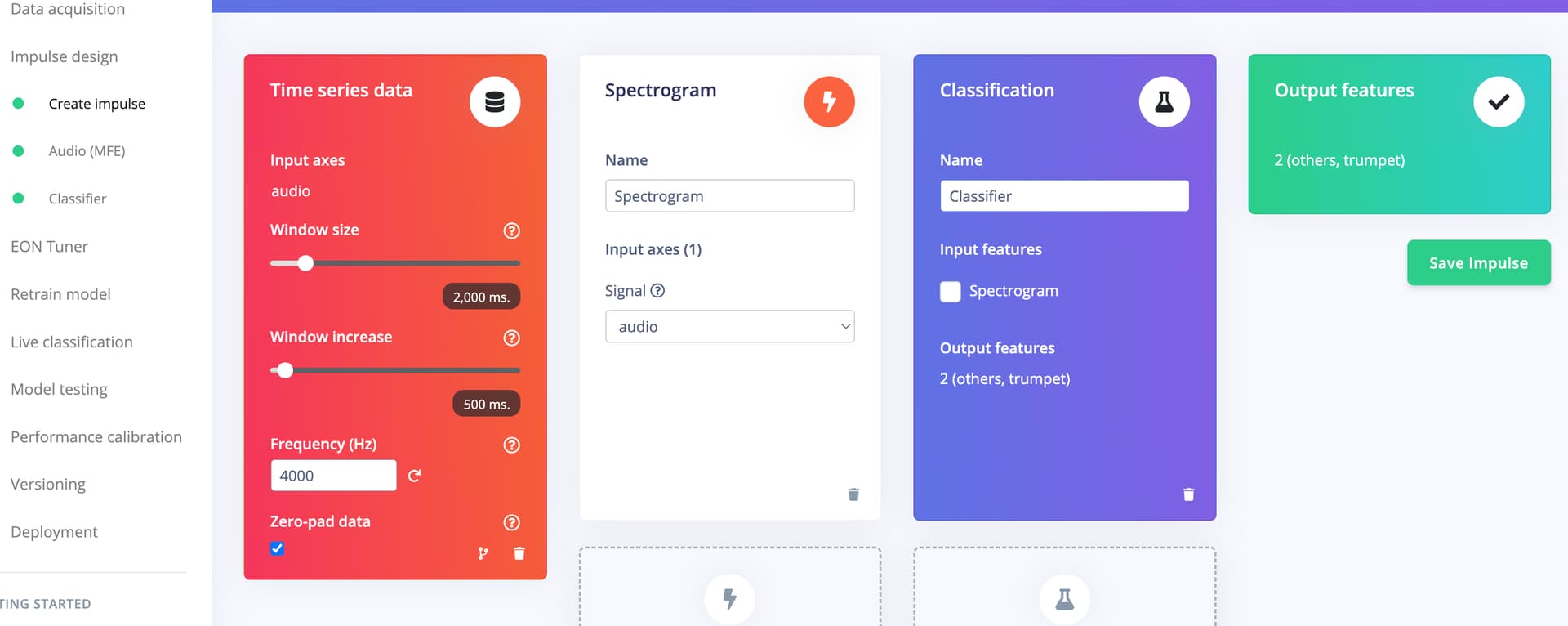
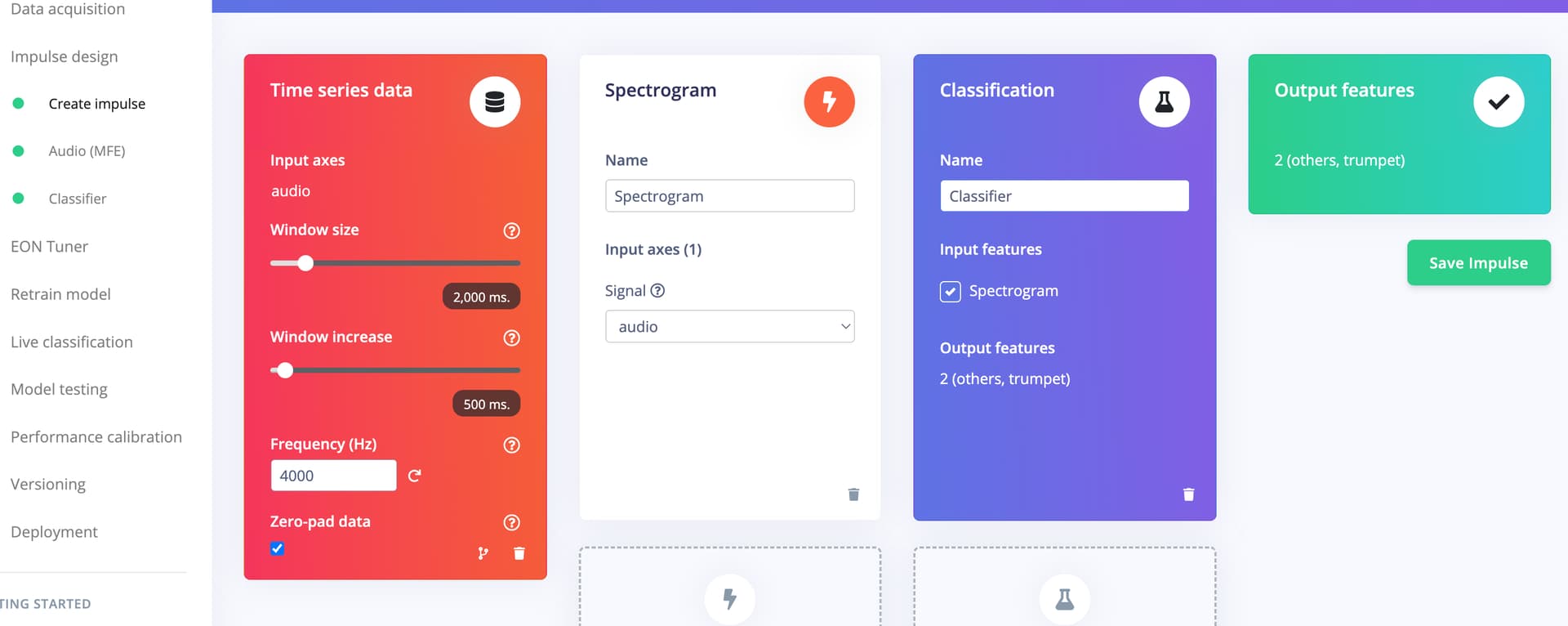
- I go to Create Impulse, remove MFE, add Spectrogram, set a hook on Spectrogram. Then Save
- I go to Spectrogram, click on Save Parameters, then Generate features
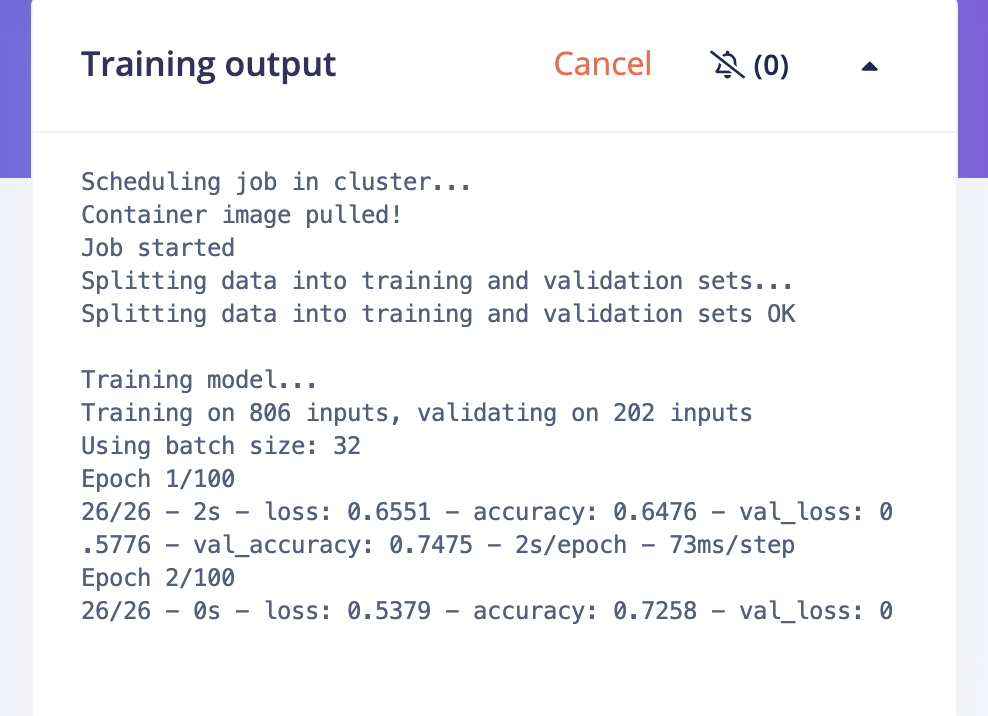
- Then go to Classifier and click on train… but get this error:
Training model...
Training on 806 inputs, validating on 202 inputs
Using batch size: 32
Epoch 1/100
Traceback (most recent call last):
File "/home/train.py", line 297, in <module>
main_function()
File "/home/train.py", line 226, in main_function
model, disable_per_channel_quantization, akida_model, akida_edge_model = train_model(train_dataset, validation_dataset,
File "/home/train.py", line 169, in train_model
model.fit(train_dataset, epochs=EPOCHS, validation_data=validation_dataset, verbose=2, callbacks=callbacks, class_weight=ei_tensorflow.training.get_class_weights(Y_train))
File "/app/keras/.venv/lib/python3.8/site-packages/keras/utils/traceback_utils.py", line 70, in error_handler
raise e.with_traceback(filtered_tb) from None
File "/tmp/__autograph_generated_fileuptkvd0k.py", line 15, in tf__train_function
retval_ = ag__.converted_call(ag__.ld(step_function), (ag__.ld(self), ag__.ld(iterator)), None, fscope)
ValueError: in user code:
File "/app/keras/.venv/lib/python3.8/site-packages/keras/engine/training.py", line 1249, in train_function *
return step_function(self, iterator)
File "/app/keras/.venv/lib/python3.8/site-packages/keras/engine/training.py", line 1233, in step_function **
outputs = model.distribute_strategy.run(run_step, args=(data,))
File "/app/keras/.venv/lib/python3.8/site-packages/keras/engine/training.py", line 1222, in run_step **
outputs = model.train_step(data)
File "/app/keras/.venv/lib/python3.8/site-packages/keras/engine/training.py", line 1023, in train_step
y_pred = self(x, training=True)
File "/app/keras/.venv/lib/python3.8/site-packages/keras/utils/traceback_utils.py", line 70, in error_handler
raise e.with_traceback(filtered_tb) from None
File "/app/keras/.venv/lib/python3.8/site-packages/keras/layers/reshaping/reshape.py", line 118, in _fix_unknown_dimension
raise ValueError(msg)
ValueError: Exception encountered when calling layer 'reshape' (type Reshape).
total size of new array must be unchanged, input_shape = [12935], output_shape = [404, 32]
Call arguments received by layer 'reshape' (type Reshape):
• inputs=tf.Tensor(shape=(None, 12935), dtype=float32)
Application exited with code 1
Job failed (see above)
Can the browser cash have something to do with it or anything else localy on my PC?