I am currently running Edge Impulse Linux SDK on my Raspberry Pi classifying sounds. My task is to save classified sounds as .wav files however I cannot find anywhere how to do so and what parameters were used by the model on capturing the sound from microphone.
AudioImpulseRunner returns audio as bytes, then I try to save it using the following code:
However, my next problem is that it returns very short sound files, the duration of these files is only 64 milliseconds. On Edge Impulse ML model configuration, I have set the window size to 1000 milliseconds which is how long I expected the file duration going to be.
Thank you for sharing your code. I have reproduced the same issue on my side and we are currently looking into it. we will keep you posted on further developments on the issue ASAP.
To save your full .WAV sample, you would want to use the extracted features to be classified and convert them to WAV rather than using the audio itself. To do that, go to the classifier function on the audio.py file in the edge_impulse_linux directory and return features instead of audio as shown below:
classifier(self, device_id = None):
with Microphone(self.sampling_rate, CHUNK_SIZE, device_id=device_id) as mic:
generator = mic.generator()
features = np.array([], dtype=np.int16)
while not self.closed:
for audio in generator:
data = np.frombuffer(audio, dtype=np.int16)
features = np.concatenate((features, data), axis=0)
while len(features) >= self.window_size:
begin = now()
res = self.classify(features[:self.window_size].tolist())
features = features[int(self.window_size * OVERLAP):]
yield res, features
After that you can write your wav file using scipy in the AudioImpulseRunner(modelfile) of the classify.py as shown below:
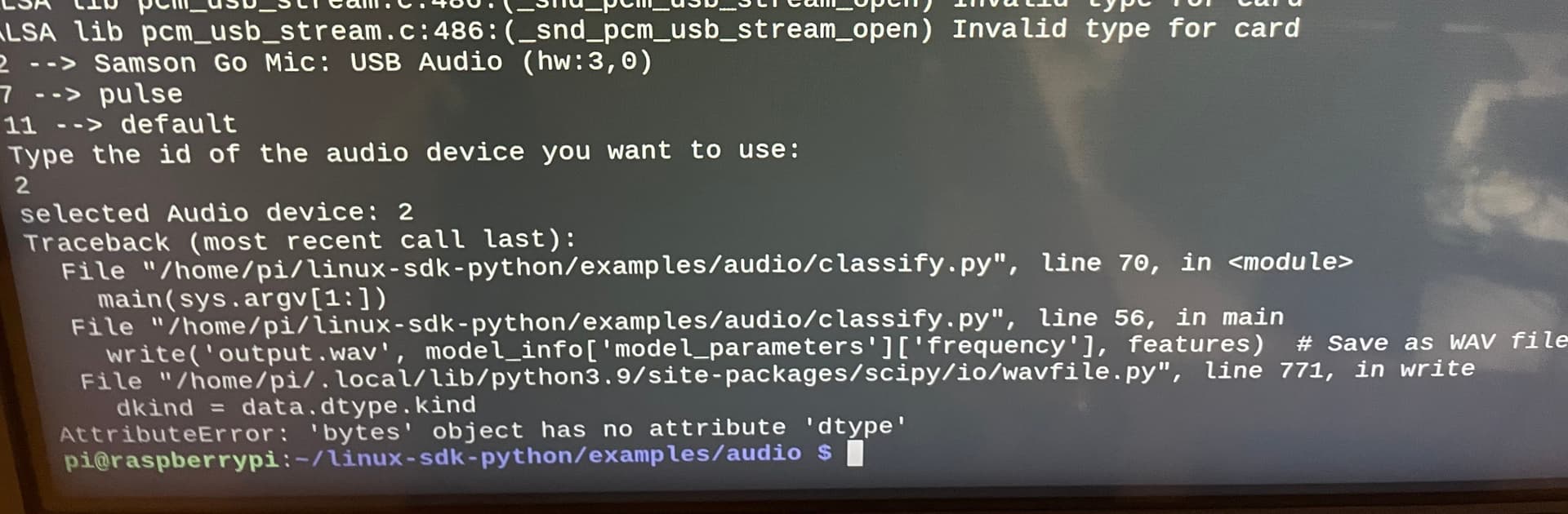
for res, features in runner.classifier(device_id=selected_device_id):
write('output.wav', model_info['model_parameters']['frequency'], features) # Save as WAV file
print('Result (%d ms.) ' % (res['timing']['dsp'] + res['timing']['classification']), end='')
for label in labels:
score = res['result']['classification'][label]
print('%s: %.2f\t' % (label, score), end='')
print('', flush=True)
Note that you must first install scipy using pip then then import it using
The message kind of explains it, your code indentations are a mix of spaces and tabs. This is not supported at least in some editors. I’m assuming you are using Python.
Replace your tabs with spaces, also check your editor preferences what happens when you use the Tab-key.