Hi, I was trying to inference an audio KWS project on XIAO ESP-S3 with Sense HAT. The device was working fine on the previous audio project, only facing issues with this particular project. Thanks in Advance.
ERR: Failed to run classifier (-3)
Arena size is too small for all buffers. Needed 15280 but only 12160 was available.
AllocateTensors() failed
ERR: Failed to run classifier (-3)
Edge Impulse Inferencing Demo
Inferencing settings:
Interval: 0.062500 ms.
Frame size: 16000
Sample length: 1000 ms.
No. of classes: 2
@shawn_edgeimpulse Thanks, but unfortunately I was not able to solve it after reducing the bit depth and reducing the sample rate. And the EON is not supported by the XIAO ESP32-S3 now.
Also, what is your window size? If that’s too big, you will run out of memory quickly. I generally find that a window size of 1 sec is the most you will be able to use for MCU KWS projects.
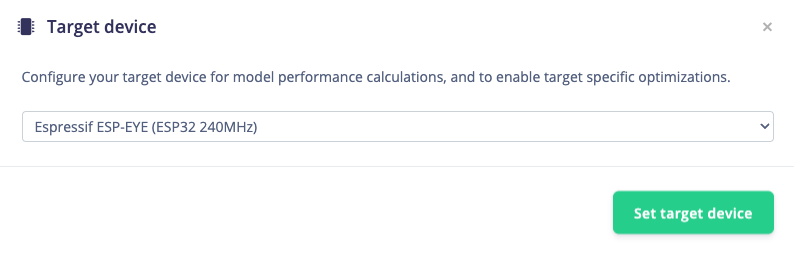
As @MMarcial mentioned, you can use the profiler to get an estimate of the RAM usage. You can use the Python SDK, but it’s not necessary. You can also view RAM/ROM estimations in Studio. Go to the Deployment page. Under Model Optimizations, click Change target and select the Espressif ESP-EYE (the closest board we have to the ESP32-S3).
What’s weird is that your ESP32 is reporting that only ~12 kB is available for the arena size. That doesn’t seem right, considering the ESP32-S3 has something like 512kB of RAM. Paging @AIWintermuteAI – any thoughts on this one?
From @AIWintermuteAI: ESP32-S3 optimized kernel support is in the works. Something you might want to try: swap the Edge Impulse C++ kernel with an ESP-NN kernel to support faster/efficient computations on the ESP32-S3. This is a bit of a hack, but it might be worth a shot: TinyML Made Easy: Image Classification - Hackster.io. Note that it will not work with a library created with the EON Compiler enabled.
Thanks and Yes, I tried to use the ESP-NN lib compiled by @AIWintermuteAI. I’ve been using a small Yes/No project with XIAO-ESP32-S3 with the NN lib swapped and it’s working fine, but here I’m trying to build a running faucet demo with Edge Impulse provided running faucet dataset.
“ESP32-S3 optimized kernel support is in the works.”
Great to hear - we are just working on a sound recognition solution on ESP32-S3 - can u give a rough idea of schedule?
Also we could do a beta testing if helpful.
Hey, I am still facing the same issues. Was anyone able to resolve them. I am getting the error on xiao esp32s3 sense board.
00:21:33.692 > AllocateTensors() failedERR: Failed to run classifier (-3)
Edit - To anyone facing the issue - I was able to get it to work by choosing MobileNetV1 0.1 model in edge impluse rather than MobileNetV2 0.35 as it is much smaller.
@nischalj10@salmanfarisvp Hey! I dont know if you need this info now, but I think I have fixed this problem.
The reason is the tflite arena size which is smaller than model len.
I dont know why Edge Impulse sometimes calculate wrong arena size and sometimes everything is good. But if you change this number on a larger one - everything will work.
You can change that in your arduino library folder \ src \ tflite-model and model-parametrs.
tflite_learn_564938_5_arena_size and EI_CLASSIFIER_TFLITE_LARGEST_ARENA_SIZE
I recently ran into the exact same AllocateTensors() failed (-3) issue on my ESP32-S3 audio project. While increasing the arena size in the headers (as mentioned above) definitely works, I wanted to share a few deep-dive findings that might help others accurately optimize their memory without blindly guessing the numbers.
Here is what I found:
1. The “Hidden” ESP-NN Scratch Buffer Cost
In my case, the Edge Impulse dashboard estimated an arena size of around 22KB (21683). However, due to the ESP-NN optimization for ESP32-S3, the hardware required a massive scratch buffer for operations. It actually needed around 84KB (a ~62KB difference!). This explains why a small padding wasn’t enough to prevent the crash.
2. How to profile the exact memory required
Instead of guessing how much to add, you can print the exact peak memory consumed by the TFLite interpreter.
Open src/edge-impulse-sdk/classifier/inferencing_engines/tflite_micro.h (or tflite_eon.h if EON is enabled), find interpreter->AllocateTensors(), and add this debug print right after the success check:
ei_printf("DEBUG: TFLite Arena used bytes: %d\n", (int)interpreter->arena_used_bytes());
This prints the exact memory used on the first inference. You can then set EI_CLASSIFIER_TFLITE_LARGEST_ARENA_SIZE and .arena_size to this exact number + a small 2KB margin, achieving a perfectly optimized RAM footprint.
3. Crucial gotcha: Arduino IDE Cache
If you modify model_metadata.h and model_variables.h but still get the error, it’s likely due to the Arduino IDE’s cache. The IDE caches library headers aggressively. Make sure to add a blank line (or a white space) to your main .ino sketch and save it to force a clean recompile; otherwise, your new sizes will be ignored by the compiler.
Hope this helps anyone dealing with tight RAM constraints on the ESP32-S3!