Hello, I noticed that you can modify a model in Edge Impulse by using Expert view. Is it also possible to change the depth multiplier parameter or can you only use the ones present in model selection brackets. Thanks in advance.
Hi @peterpis ,
Depth multiplier is kept constant at 1. The one in the model selection is the Width multiplier (alpha) which can be configured in the expert mode by changing the value of alpha.
Let me know if this helps.
Thanks,
Clinton
1 Like
Hi,
thank you for your reply, I have found the alpha parameter, but I am a little confused, aren’t Width and Depth multiplier the same parameters?
Hi @peterpis ,
Taking this as a refference, Depth_multiplier and Width multiplier (alpha) are different and are both input arguments for the MobileNet model. You might want to read more here MobileNet, MobileNetV2, and MobileNetV3 .
Thanks,
Clinton
1 Like
Hi,
thank you for your reply. It seems like when the alpha parameter is changed with an existing mobilenetV1 architecture, there is a mismatch in dimension between my model and existing model in WEIGHTS_PATH, because the error I get is:
ValueError: Cannot assign value to variable ’ conv1/kernel:0’: Shape mismatch.The variable shape (3, 3, 1, 4), and the assigned value shape (3, 1, 3, 3) are incompatible.
Is there a way to test different alpha parameters on existing architectures in EdgeImpulse or do you need to do it without existing weights path?
Hi @peterpis ,
I am tagging along @matkelcey & @dansitu for some more insights and detailed explanation on this.
Clinton
Hi Peterpis,
Yes, we only have pretrained weights for a fixed combination of input channels and mobile_net alphas, you can see the combination list in the train method in expert mode.
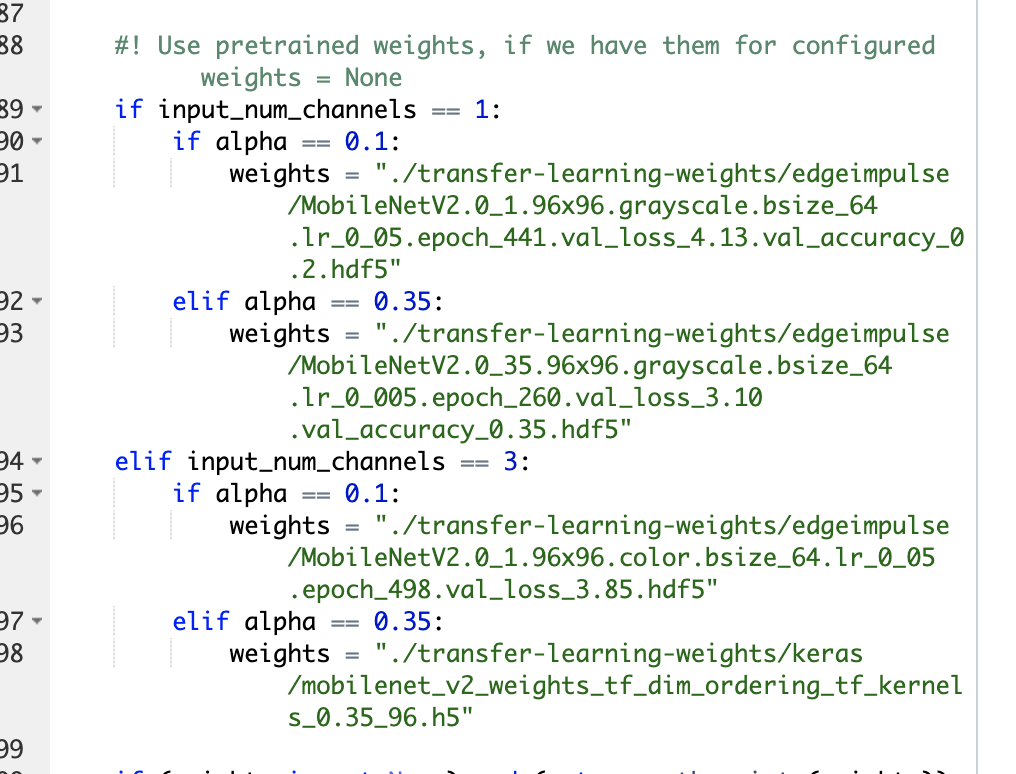
Since we are dealing with such low input resolutions, and we are only using a subset of the head of MobileNet, there are a couple of combos that end up not making sense (with the model trying to do spatial reduction down past 1 pixel; which I think is what we’re seeing here with the (3, 3, 1, 4) kernel)
What size input and mobilenet alpha etc are you interested in trying? If you can share your project with me I’m happy to jump in and give some recommendations
Cheers, Mat
Hi,
thank you for your reply. The combination I tried is with MobileNetV1:
WEIGHTS_PATH = ‘./transfer-learning-weights/edgeimpulse/MobileNetV1.0_1.96x96.grayscale.bsize_96.lr_0_05.epoch_363.val_accuracy_0.14.hdf5’
INPUT_SHAPE = (96, 96, 1)
base_model = tf.keras.applications.MobileNet(
input_shape = INPUT_SHAPE,
weights = WEIGHTS_PATH,
alpha = 0.15
)
I kept everything the same as default, but changed alpha to 0.15. Is that possible if the transfer learning model was trained with alpha 0.1?
yes, that’s it. the WEIGHTS_PATH you list here is for an alpha of 0.1 (…MobileNetV1.0_1.96x96…) and can’t be mixed with alpha=0.15 when specifying the keras.applications.MobileNet sorry 
also note that we only take “the top” of the mobile net architecture; you’ll see this in expert mode as the cut_point …

… this bit of code is mobile net v2 specific; so if you want to try out mobile net v1 you’ll need to change this to the v1 naming; which for this spatial reduction would be the layer conv_pw_5_relu
also note, that for mobile net v2, the head of the network we take ends up being the same for alpha=0.1 and 0.15, but for mobile net v1 they are different.
let me know how you get on…
mat
Hi, thank you for your reply. I am looking at the expert view of the mobile net v2 model and I can’t seem to find the part of the code that you pasted in your reply about cut_point. Which model did you open in expert mode?

oh, depending on how long ago you made this project you are potentially seeing something different; if you can’t see it can you start a new project and see if it’s there? if so you can either switch to the new project or we can help port your old one if there’s specific stuff there you want to keep
Hi, it seems like the cut_point is present in object detection, but I am working on classifying images. Is anything similar possible for classification?
Oh, apologies, I thought we were talking about detection! No sorry, there is no equivalent for classification yet, but it is something in works right now! Cheers, Mat