Hello… I’m a beginner to machine learning and trying to implement a model from a paper…
I’m developing a keyword spotting application and following is the architecture i want to implement.
The architecture should contain the
Conv layer with 64 feature maps and 1 into 3 pooling size
Conv layer with 64 feature maps and 1 into 1 pooling size
Linear layer with 32 feature maps
DNN with 128 feature maps
Softmax with 4 feature maps
I’m assuming, the feature maps and number of neurons would be the same value in Edge Impulse?
Also how to set the pooling size?
What is DNN In edge impulse? I’m assuming the dense layer is the linear layer?
And how can weight matrix (m into r) be perceived from edge Impulse ?
Sorry for these basic questions but it would really help if i get answers to these…
Thanks in advance
In Edge Impulse, the number of “filters” in a convolutional layer is the number of neurons, which is also equal to the number of feature maps that are output from that layer.
The pooling size is set to 2 by default. You have to go into Expert Mode to change the pooling size.
Yes, DNN stands for “dense neural network.” I’m not sure what you mean by “linear layer,” as most dense layers have non-linear activations (e.g. ReLU or Softmax if it’s the final layer of a classification model).
I’m not sure what you mean by “weight matrix (m into r).” Could you provide an example of this?
Also, for keyword spotting with CNNs, I might recommend checking out the videos in the course here: https://www.coursera.org/learn/introduction-to-embedded-machine-learning. It’s free to take the course (Coursera will pester you to pay for a certificate, but it’s not necessary). We briefly cover DNNs, CNNs, and how to make a keyword spotting system in the final week.
hi @shawn_edgeimpulse, since this thread talk about CNN architecture, can I ask a question about it?
I have project about sound classification, and hardly to understand,
what is the reasonable behind, why EI use CNN on audio classification task?
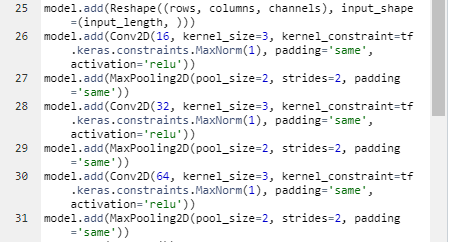
this is the setting default CNN architecture on Edge Impulse, what is the mean and the function of
“kernel_constraint=tf.keras.constraints.MaxNorm(1)”? what will happen if I change the number?
CNNs are useful in audio classification tasks when you perform feature extraction first that results in something that looks like an image. In Edge Impulse, you can (be default) use spectrograms, MFEs, or MFCCs for features for most audio classification tasks. The output of these processing blocks is a 2D array, which looks much like an image. As a result, image classification techniques (e.g. CNNs) work well here.
thanks for the answer. since you talk about Spectrogram and MFE and I’ve watch your video on coursera, it is great tutorial, but I have several question.
in the documentation MFE have parameter like in this pic:
my question is:
because I found little information about it in the documentation. what is FFT size?
Since it might have connection with frame length, what FFT size would you recommend if I have continuous sound data (e.g. horn, drill or siren) with frame length between 20 ms to 40 ms and sample frequency of 16000 hz?
in some examples in EI, why is the default value of low freq is 300?
before we fed to neural network, Is the signal normalized ?
what kind of window function is applied each frame signal?hamming or hann?
You’re right that asking frame size and fft size is a little redundant. If FFT size is bigger than frame size (when converted to samples), then the fft is zero padded. Vice versa, then the frame is clipped. Recommend nearest power of 2 to your frame in samples. Ex: 20 ms * 16000 = 320, so 256 (a little clipping generally doesn’t hurt) or 512
That was a default we inherited from an open source library, and honestly, I can’t find any articles or rationale for that choice. I think I will change the default to 0. I recommend you use that as well
No, but the MFE block tends to output values between 0-1 due to some scaling in the MFE algo itself, so you’ll generally be fine not normalizing
We just use rectangular to save processing. At some point, we’d like to investigate what impact, if any, a window like hamming or hann would have
what is the mean “nearest power of 2 to your frame in samples.”? * What values should be in the power of 2? 320^2 or 20ms^2?
in the documentation of MFE it said:
“The last step is to perform a local mean normalization of the signal, applying the Noise floor value to the power spectrum.”
what does the local mean normalization?I have a little trouble understanding it. also Is the output of MFE also subjected to log() operation? Is there an equation used?
I hope we can the near future we can use another popular hann or hamming window sampling,
Hi @dexvils , sorry for missing this earlier, we had a technical snag where I didn’t get the notification for this message.
1- for example, 20 mS frame size (or 0.020 s) at 1000 Hz. That would be 20 samples. The next power of 2 is 32 (b/c 16 < 20) (2^5=32)
2 - Sorry, I’ve cleared up the doc. It should read: The last step clips the MFE output for noise reduction. Any sample below Noise floor is set to zero instead. And yes, we take log(power) before this step
Good feedback, thanks! You can also try making a custom DSP block and use a window like that. Our DSP blocks are available on github