Question/Issue:
I have noticed that when using raw data I can control better the hyperparameters (the structure of the model) why is it different when using images? While using images I can only play with the version of the model, the amount of neurons and the dropout rate. Why?
What is the recommended ratio for features vs neurons?
Project ID:
216037
Context/Use case: I’m trying to build a ML model that identifies the defects on the surface of 3D printed parts for my thesis Therefore, I have a few question that I would be very gratefull if could be answered!
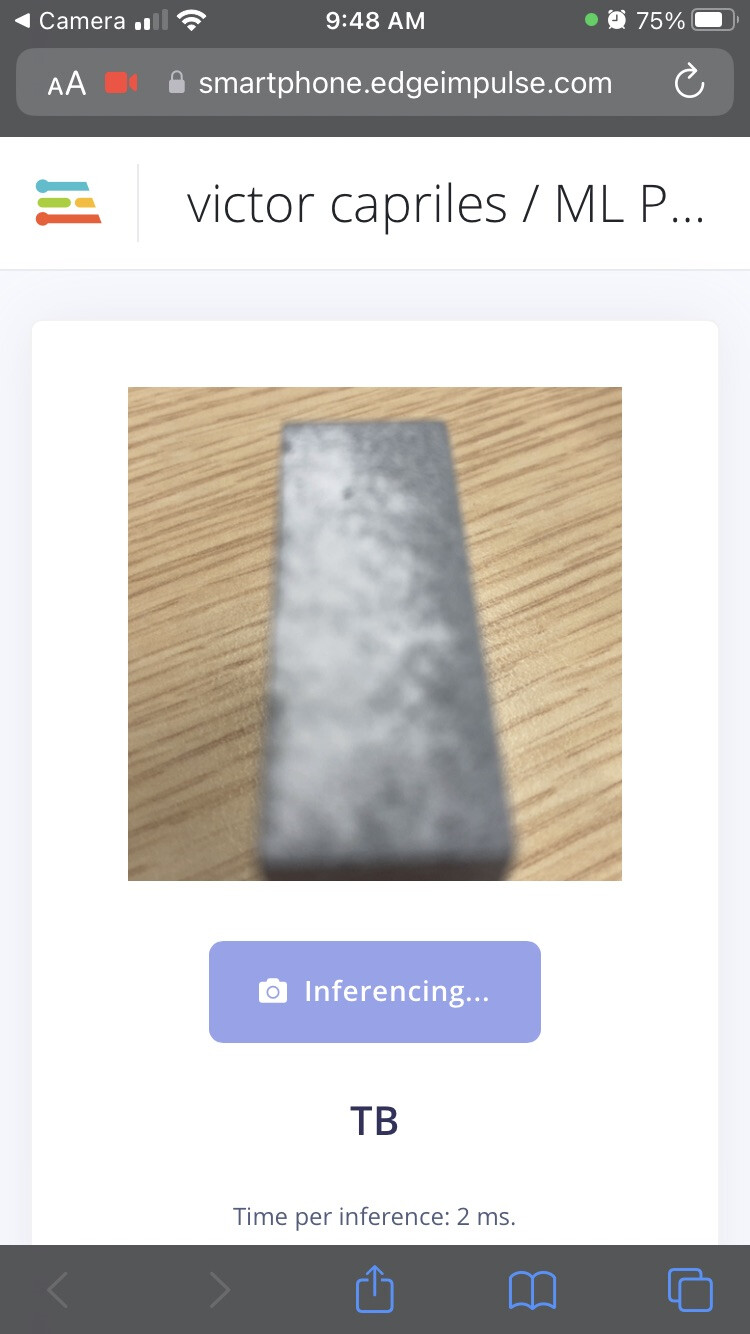
ATM I’m using the mobilenetv2 96x96 0.35 (final layer: 50 neurons, 0.2 dropout rate) which landed me a whopping 93% on the validation test. With the 16 neurons on default it was 50% accurate. Both of them in the final layer.
I’ve looked at your project, the images are being cropped to 96x96 so you can first try increasing this size. See the transfer learning doc for some suggested settings to follow:
See also the public project on cloud classification useing mobilenetv2 transfer learning:
Hello @Eoin, how are you? Thanks for the prompt answer!
I will try increasing the size to 160x160. Also I would like to point out that maybe because I trained it without any background when I put the 3D printed parts on the table it confuses it?
When I close up the distance it kinda predicts correctly but the lens of the camera loses focus.
I would recommend keeping the same for the test as the training. Including the lighting and distance. The lighting and shadows in the two images above can also cause problems. Once you get a good controlled example working then you can extend your dataset to include variations on lighting and distance.
Thanks for the advice, I will look into it! Sorry I couldn’t answer earlier.
Maybe my earlier explanation was confusing. What I meant is, I will build 2 separate ML models. One trained with pictures with only the surfaces of the 3D printed part and no background. And the other with the 3D printed part and the background (in this one i will also add a class for the background)
Thank you very much! I could probably use this tool to increase the data set size. Although, I will have to train the model locally (can’t exceed the 20mins).
Hello! @louis@Eoin
I would like to train locally the model so I don’t have the limitation of the 20mins. Is it possible to copy&paste the code provided from the expert mode on edge impulse and paste it on google collab (for example). Because I would like to use the same hyperparameters and the CNN.