Question/Issue: Currently creating a project with some friends that uses Edge Impulse and a Raspberry Pi 4. We currently have the model, all data samples, and everything running when we type the command: “edge-impulse-linux-runner,” however, we want to be able to adjust how the output looks once the code is ran from our project. We cannot figure it out for the life of us. It just continuously shows the loop of voice data, with spikes in accuracy whenever we say a keyword. I want the terminal to provide a clearer interface whenever the person (there are three of us) speaks the key phrase which in our instance is the word “access.” What should we do? We are so lost.
Thank you @shawn_edgeimpulse ! By any chance does this work this vocal stuff? The project I’m doing deals with voice recognition and not images unfortunately. I may have seen that tutorial about webcam usage and how it can be ported over with .eim but I don’t know how to do the same via voice.
@shawn_edgeimpulse I forget to include this in my previous reply, but the link of GitHub that goes to examples of static features is invalid, and will not open up on my end.
I will try this out once I’m back home from work. You said that the GitHub file includes audio detection using the runner, is that for the link that you just gave me, or from the original post?
Hi @shawn_edgeimpulse,
For the use of this code, would I just plug it straight into my Raspberry Pi’s terminal? I don’t know where to really allocate any of the SDK stuff using edge impulse beyond the edge-impulse-linux-runner command
Will I have to change much beyond the code given given? I’m currently uploading this code onto the terminal of the pi. All I really want to access is the ability to get the key word that my group and I have audio samples of, and then when received to the pi terminal, I just want it to run and then say who is currently talking.
The UI on the terminal now looks a lot cleaner than previously. If I want the terminal to display a message whenever the user speaks and the model recognizes it, how would I go along doing so?
My apologies for the string of questions, but we are so confused since there aren’t many tutorials using a raspberry pi 4.
for res, audio in runner.classifier(device_id=selected_device_id):
print('Result (%d ms.) ' % (res['timing']['dsp'] + res['timing']['classification']), end='')
for label in labels:
score = res['result']['classification'][label]
print('%s: %.2f\t' % (label, score), end='')
print('', flush=True)
Change that to something like the following (note that I have not tested it):
target_label = "access" # Or whatever label you want to look for
threshold = 0.6
for res, audio in runner.classifier(device_id=selected_device_id):
score = res['result']['classification'][target_label]
if score > threshold:
print(f"Heard {target_label} with confidence {score}")
print("", flush=True)
Oh okay, @shawn_edgeimpulse, that makes some sense. Would I change target_label to a name within my project, or does this classify it as it’s own variable?
@shawn_edgeimpulse Hi, I’m also one of the members working on this project. So, for target_label there is no label called access within our samples. We just want that as soon as we say the word access then it performs the commands in the lines after it.
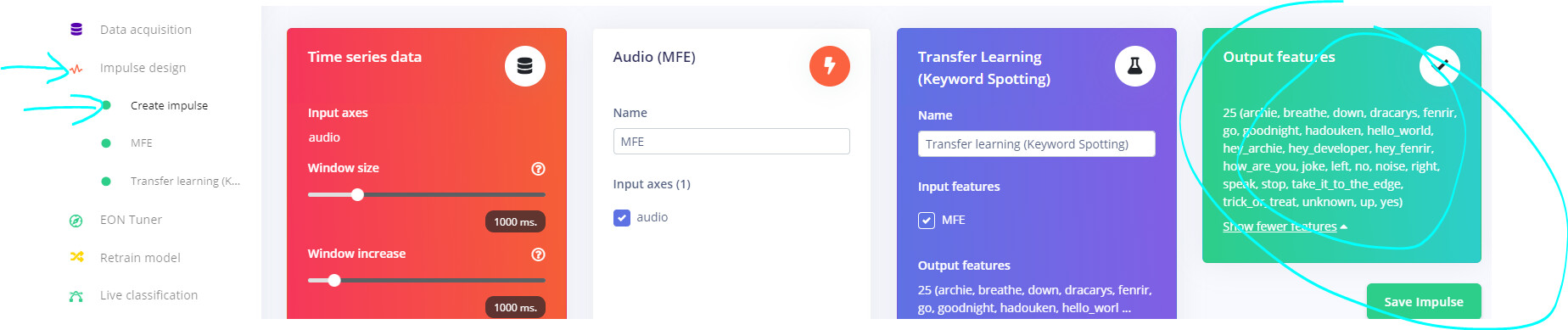
Oh okay, that makes sense. I currently have disabled the noise and unknowns from my project, would I just redownload the modelfile.eim to implement the changes? @shawn_edgeimpulse@MMarcial
Just redownload the modelfile.eim to implement the changes AFTER:
executing all the sections in the Impulse Design Section and then
goto the Deployment page and build the Linux (AARCH64) ready-to-go binary.
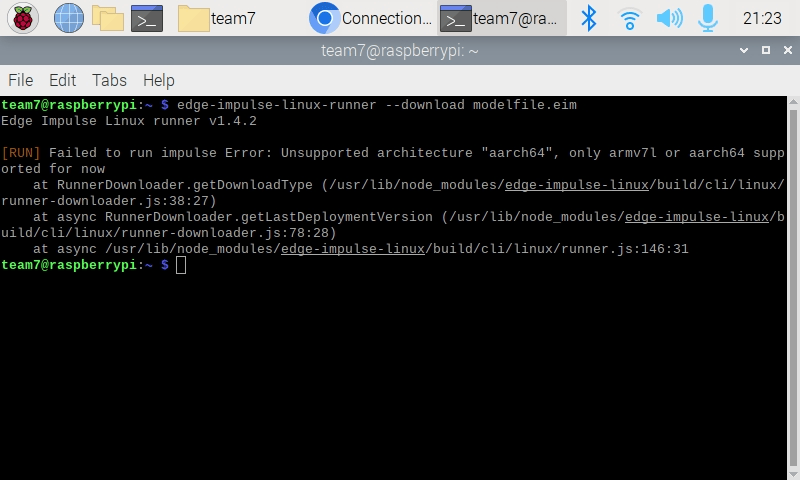
Assuming you re-built the Impulse and Built the binary and are now getting unsupported aarch64, then something else must have changed besides just the EIM file. My advice is to check you engineering logbook you are using to document this task (a very important task if you are ever going to file for a patent). Then start rolling back changes until you get to a working version, then start moving forward carefully documenting changes.
Perhaps a capture of the screen with the unsupported aarch64 error might help.