I would like to know how whether Column axis or row Axis of the confusion matrix defines the Actual class and Predicted class on edge Impulse studio.
Hey, see this:
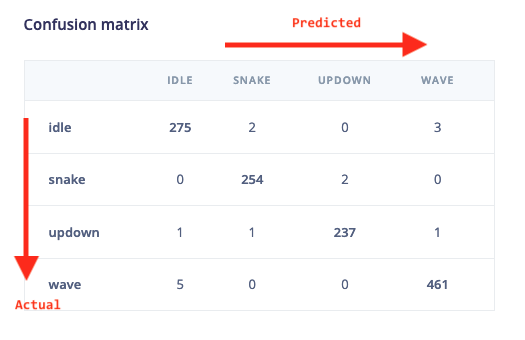
It’s a bit more clear on the Deployment page, we can add the same highlights to the neural network page as well:
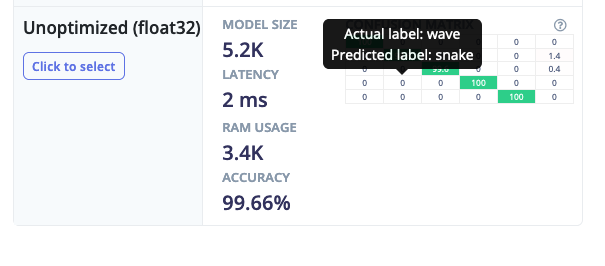
We’ll also be rolling out the tooltips on the classifier page later this week!
1 Like
When I compare the Confusion matrix between Classifier & Deployment, it is significantly different. Which one should I use?
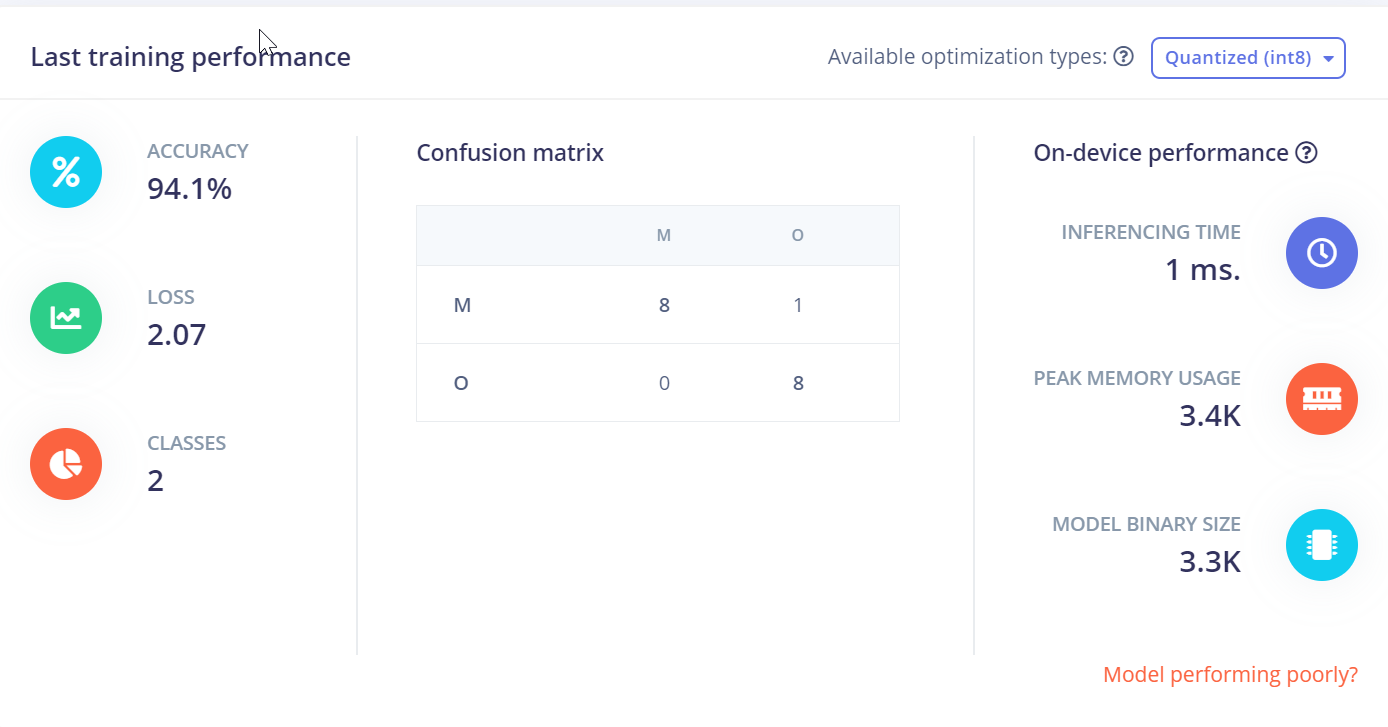
Hi, the confusion matrix on the deployment tab is against the testing set (also incorporating anomaly blocks if configured). The confusion matrix on the NN Classifier is based on your training set (split 80/20).
Looks mostly like you have too little training data, and that’s why the model generalizes worse on new testing data.
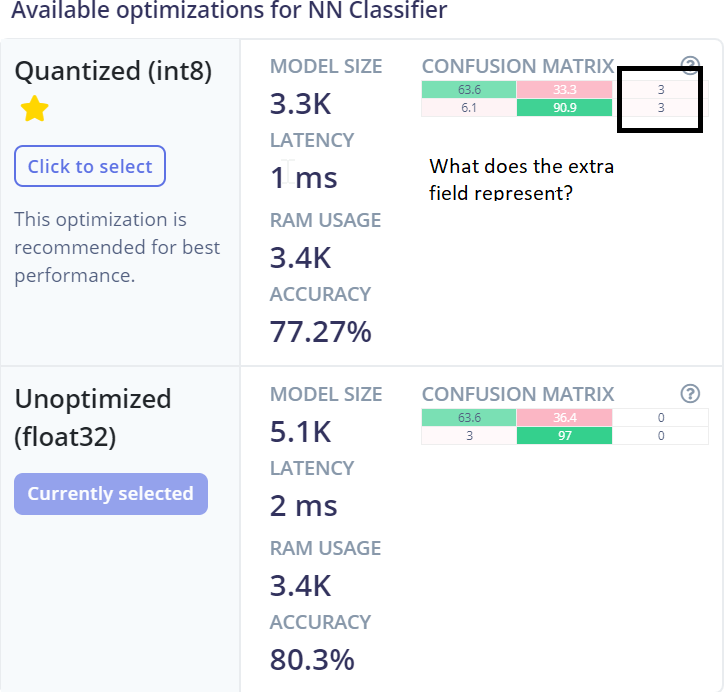
Thanks for clarifying. I have not uploaded any dataset for testing purposes. Then my understanding is that in NN Classifier, the Confusion Matrix is generated based on a smaller sample of data whereas in Deployment, the entire training data is evaluated for generating the confusin matrix. It puzzles me that in the Deployment Confusion Matrix (as marked in the image), what does the third field with label unknown represent?
Hi Paul,
When you start training a NN Classifier block, we set aside 20% of your training dataset. This subset is known as “validation” data. During training, the model is trained on the training dataset minus this validation data.
At the end of every epoch of training, the model’s performance is tested using the validation data, which is where the “val_accuracy” and “val_loss” statements in the training output come from (“val” standing for “validation”). This allows us to understand whether the model has actually learned to generalize to unseen data, or whether it has just exactly memorized the properties of its training data.
At the end of training, the validation data is classified one last time, and the results are displayed at the bottom of the page as the accuracy, loss, and confusion matrix.
Later, when you deploy your model, we calculate the accuracy and confusion matrix for your entire impulse (including anomaly detection if you are using it) on your test dataset. The “unknown” label represents windows for which no class met the accuracy probability threshold defined on the NN Classifier page, which is 0.8 by default. You can change this value depending on how confident you need your model to be of its predictions. I’m actually planning to change this so that the label is “uncertain”, which more accurately reflects what it means.
It’s standard practice to use separate validation and test datasets. The reason is that during training, as you tweak your model to try to improve its performance on the validation data, you run the risk of adjusting the model so that it happens to work great on that validation data but not necessarily on unseen data. By running a final test on a completely separate dataset, we can get a realistic understanding of our model’s performance.
Thanks for your questions in this thread—some of this stuff can be unintuitive, and I’m looking forward to refining our UI and documentation to make it clearer what is going on!
Warmly,
Dan
1 Like