Hi guys!
I have a sound file that contains say 15 minutes of data that I would like to analyse for the different sounds it contains, to later train a model that can recognize the different sounds.
I would need to cut up the file in chunks of 1 second and then label each chunk. I was hoping to use cluster analysis to at least be able to distinguish the seconds with nothing but white noise. Then i was hoping to also find clusters of comparable sounds that i could go trough to label - but my workload would be much decreased.
Can this be done through edge impulse? Or would I have to go through python, which would require me to create the spectorgrams there which has caused me many issues in the passed. Issues that I try to avoid from now on.
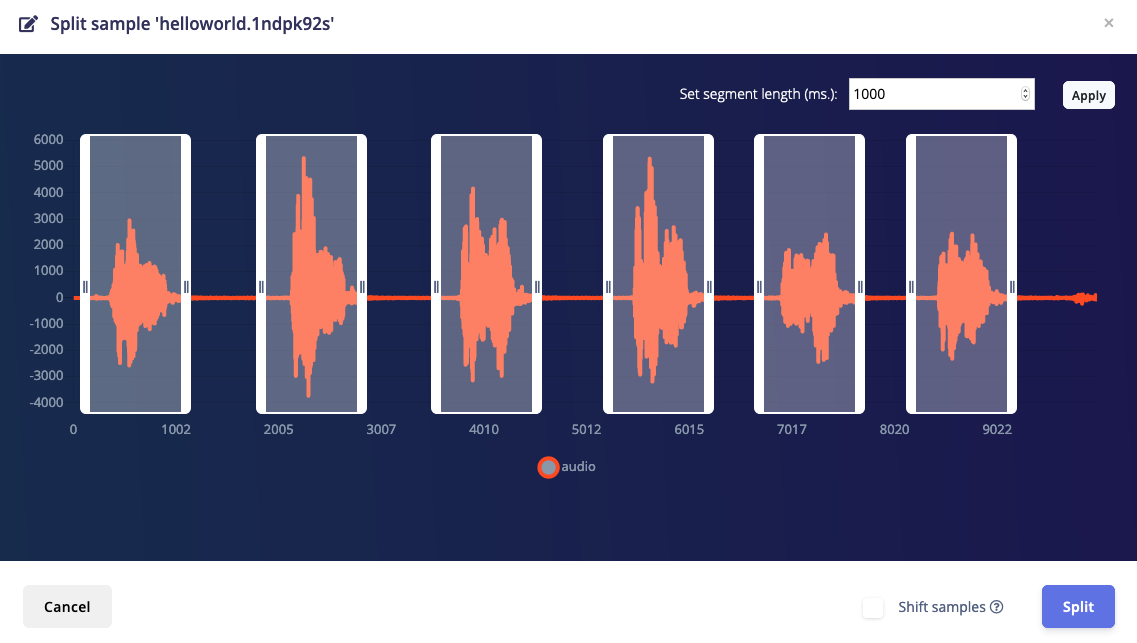
If click the ⋮ menu next to an audio sample in Edge Impulse Studio and select “Split sample,” Edge Impulse will automatically detect areas of sound for you (which you can adjust) and split those sections into individual samples. You can read more about this feature here: Responding to your voice - Edge Impulse Documentation
Hi shawn, super. I have to admit that if it is this easy i should have figured it out myself.
I will try it out!!
Interesting, a guy i work with is now cutting up the file in 2 sec samples but i guess that wont be necessary anymore.
Just out of curiosity - i would guess that edge impulse would also be able to deal with those files if they are already cut up? I am sure my colleague will appreciate his work but having been in vain
Yes, Edge Impulse will work with files that have already been sliced up. You just need to set the “window size” to be the same as your slices (e.g. 1000 ms for 1 second slices).
I was wondering, after i cut up the sound file in samples, can i run an unsupervised cluster analysis on those samples, to help me labelling the data? I would like to find a way to efficiently go through the sound files and grouping sounds that “look alike” could really help…