I’m running a keyword spotter on an nRF5340. In the past I’ve gotten it to work, although it always involved adding seemingly magical gain values to the signal that I never understood. In the latest build I can’t get it to work at all, even when running a canned sample through.
class ClassifierTest
{
public:
static ReturnCode RunDiagnostic()
{
signal_t signal;
signal.total_length = 16000;
signal.get_data = &GetAudio;
ei_impulse_result_t result = {0};
const bool useAveraging = false;
auto err = run_classifier_continuous(&signal, &result, false, useAveraging);
if (err != EI_IMPULSE_OK)
{
return ReturnCode::InvalidData;
}
if (result.classification[0].value < 0.9)
{
return ReturnCode::InvalidData;
}
return ReturnCode::Success;
}
private:
static float Convert(int16_t value)
{
return (float) value / 32768.0f;
}
static int GetAudio(size_t offset, size_t length, float *audio)
{
Span sample(Sample);
auto source = sample.Skip(offset).Take(length);
Span target(audio, length);
auto rc = source.CopyTo(target, Convert);
return rc == ReturnCode::Success ? 0 : -1;
}
static constexpr int16_t Sample[] = { /* 16000 values taken from the MFE "Raw Features" */ }
}
I realize not all the guts of the supporting classes are here but they are all thoroughly unit tested and I’ve stepped through everything to verify that it is working as expected. I’ve tried changing “total_length” to different lengths such as the slice size, etc. but the classifier always detects the sample incorrectly. I get the same behavior if I run our device and use the microphone. In the past I’ve multiplied by 64.0 to get it to work but no idea why that should be necessary.
This is for project 64474.
EDIT: I didn’t realize pre-emphasis was doing the int16 → float scaling “for me”. This isn’t really clear from your examples, which seem to include a divide by (1 << 15), at least in the ingest. Removing the scaling solves the problem.
EDIT 2: In general pre-emphasis just seems to wreak havoc with my model. Can someone explain what the point of it is and why it doesn’t seem to work? Without it I need to amplify the input but with it I get nothing.
Sorry you’re having trouble. The first step we always take in debugging is to find a sample from Studio and run it on device, comparing the results. Can you do something on device similar to this tutorial : On your desktop computer | Edge Impulse Documentation
Sorry, I’m not following. Per my post I believe I’ve already done that and identified the problem. Please go back and read my post including the edits.
Great, appreciate you looking into it! If you’re able to give me any info on the bug it would help me assess whether it’s the specific condition I’m experiencing.
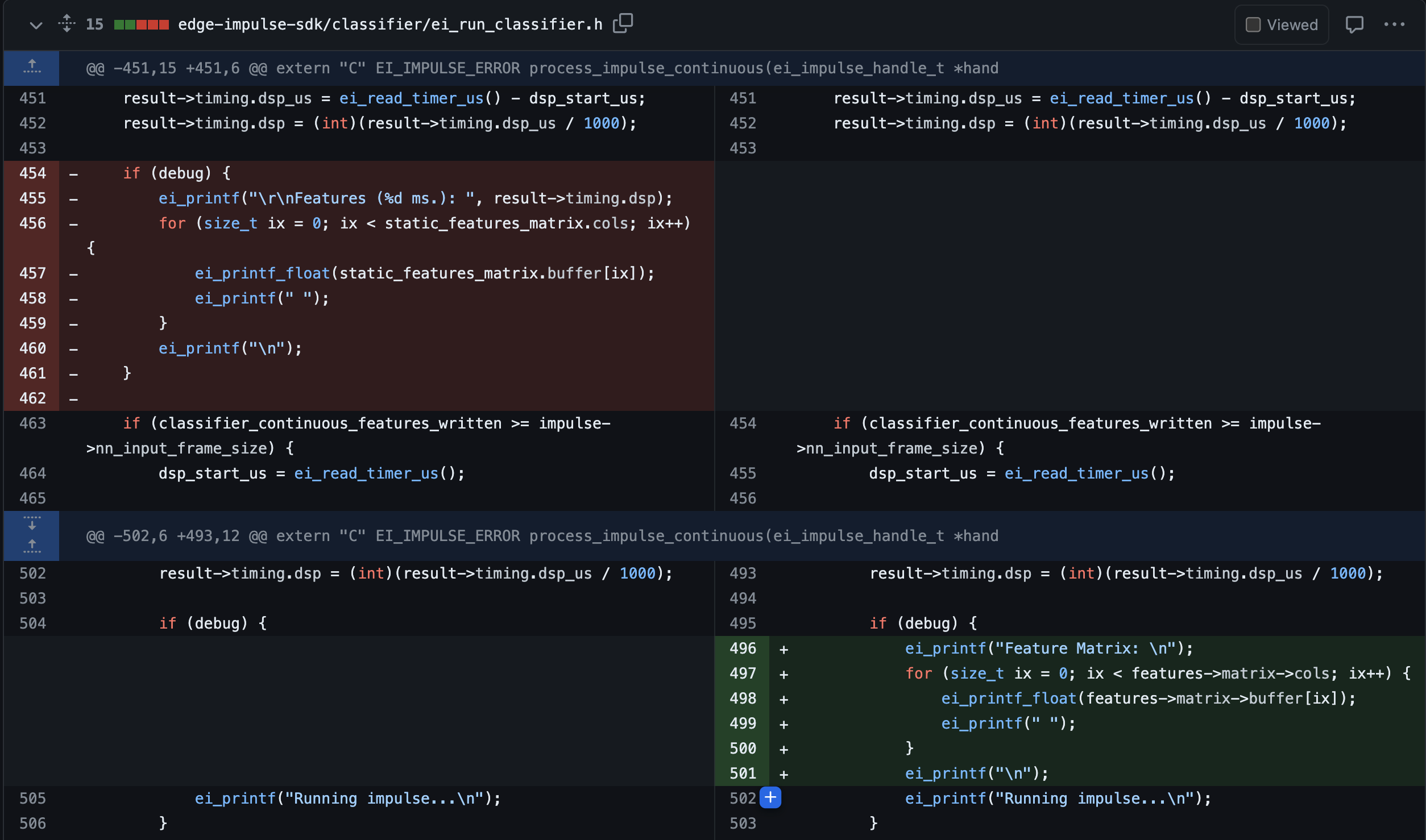
What we realized is that the correct features were being passed into the classifier, just that the debug mode was printing the DSP output at the wrong point inside the code. A fix should land on production in a couple hours, and then the debug output showing DSP results should match Studio (for the samples we’ve tested at least…if you find a sample with a mismatch, please pass it along!) Or if you’re eager to get started, it’s an easy patch to apply, I’m attached the diff of where the debug print needs to be more from and to.
Please let us know if you see any other samples that don’t look like they’re being processed correctly! Since you’re reporting that on device inference isn’t looking as good, it may be that this fix is necessary but not sufficient?
Yeah, I’m not using the classifier debug flag, I’m just not getting good results. I can make it work by commenting out the pre-emphasis stage and increasing the gain on the samples.
If nothing else, can you explain this line in the pre-emphasis stage?
if (_rescale) {
matrix_t scale_matrix(length, 1, out_buffer);
ret = numpy::scale(&scale_matrix, 1.0f / 32768.0f);
if (ret != 0) {
EIDSP_ERR(ret);
}
}
I realize this code is taken from speechpy, but EI is passing “true” to rescale here, so the signal is being multiplied by 1 / 32768. Since we’re already converting from int16_t to float before passing into the classifier, this is basically taking the final amplitude to zero. It feels like this was not what was intended but maybe I’m missing something?
Alternatively, if this was intended, can you show an example of doing classification from a microphone on something (nRF would be ideal but I’ll take anything)?. All the code I’ve seen is for ingest, not classification and that code is somewhat incongruent with this, since the ingest code is also dividing by 32768 and therefore suffers from the same problem.
The reason the scaling takes place is similar to how most ML engineers normalize their features before running training or inference…there are under the hood training reasons to do this.
The reason we do the scaling “for you” is that the input range always must match what you trained on. If you look in studio, your samples are in the range ± 32K, so we rescale to ±1 for both training and inference. I agree this can be a bit confusing b/c it feels natural to just scale it yourself, but we always want to make sure any sample you copy out of studio and run locally will behave exactly the same. Thus, you must run with samples in the range ±32K
We also have examples for thingy 53, thingy 91, have a look in that github org, edgeimpulse for repos starting with “firmware-nordic-*”
If you find a sample where the output in studio and on device is a mismatch, definitely send that our way and we’ll fix it! Otherwise, I’m thinking you have an issue with sampling, scaling etc.
One thing that can help is to dump samples to the serial port, to log, during runtime. Then you can feed those samples back into studio and see if the results match, and if you’re not getting a good result, you can get some indication wise, and possibly broaden your training data to better represent your real world operating environment.
Sorry if I’m missing it, but where is the microphone example in the repo you linked? I only see continuous motion recognition, which doesn’t include the same type of int16_t → float scaling.
Hi @jefffhaynes,
I think this is what you are looking for. The ei_microphone_inference_get_data function is being used in the signal during the inference process, and in the get_data function you can find the code to convert int16_t to float.
As you can see, we are using arm_q15_to_float from the CMSIS library.
Thanks for that - so hopefully you can see my confusion. That function divides by 32768 in order to complete the conversion. Therefore, the int16_t is divided by 32768 in this method and then divided by 32768 again in the pre-emphasis processor, for a total of 1073741824. This is far too much to then expect the signal to process to anything meaningful. Again, sorry if I’m missing something here.
Thanks for pointing this out. That is indeed confusing. Most of our examples have switched to this function for conversion:
static int int16_to_float(const EIDSP_i16 *input, float *output, size_t length) {
for (size_t ix = 0; ix < length; ix++) {
output[ix] = static_cast<float>((input[ix]));
}
return EIDSP_OK;
}
But indeed arm_q15_to_float does a divide. Use of this function is a bug and will be corrected. (At one time, we tried to detect if a user had already divided down input, and would skip the scaling in that case, but this caused too many issues if a user had a range like 10 to -10.)
Please feed numbers in the range of ±32767 to run_classifier_continuous, just like they appear in Studio. You can cast directly from int to float, or you can call the function int16_to_float, which is in our SDK.
Ok, thanks for the clarification. Unfortunately I have already tried eliminating the scaling from my own code and I’m still not getting good results. The reason I opened this topic was that the presence of the bug in Edge Impulse’s example would seem to suggest that this feature has possibly not been tested. Once the bug is resolved, would you be able to try an actual microphone classification model and see what happens with pre-emphasis enabled?
EDIT: to clarify, pre-emphasis is always enabled so simply trying a classification model should do it.
We’ll certainly have a look @jefffhaynes , but the aforementioned use of arm_q15 only affects a handful of example repos, not our core SDK. We test our SDK thoroughly, including use cases that use pre emphasis.
Again, I recommend you classify some samples on device while logging the raw data. If you see a sample that classifies in a way you don’t expect, upload that sample to Studio, and see if you get the same result. That’s the only way we can help you. And it’s not to be difficult. This is the only way I debug a model on device personally. You have to split out the two domains…the signal handling domain (interrupts, buffer management, etc), and the algorithmic domain (does my model work?) Logging raw data allows you to split these two domains and debug them separately, which is the only path to success.
Can you point me to one of your repos that includes a audio classification (not ingestion, which is addressed in your core SDK)? I have done extensive testing and debugging with my own code including tracing out everything I can think of. This is not an issue with one sample but with all samples. Thanks.
Have you tried deploying onto your phone and using that for live testing? That could also give you an indication if you have an issue with your nordic device, or your model?
Additionally, do you have a Linux or Mac computer? You could also run there…either using the language of your choice, or you can run from the command line using an attached or built in microphone
@jefffhaynes the two aforementioned issues would not have affected your performance on device. One was a printing issue, the other was in the example repo, not the SDK
I will be more than happy to report back if I find something over the next couple weeks. But without a sample array that shows an erroneous output, I have nothing to test / debug / fix.