I am a new user, I have limited experience with Arduino programming so struggling to start on this project, any guidance or advice would be greatly appreciated by myself and my bees.
I have a beehive that is monitored by an ESP32, it has an I2S microphone inserted into the beehive so can pick up sounds fairly well. This website hs a large number of wav files of beehives in different states.
I’ve attempted to classify some sounds (437848) by uploading 6 wav files but the model fails to classify. I think it’s trying to pick out features to compare but it’s the overall amplitude\frequency that’s different I think.
The recordings also come with .lab text files which contain the start\stop points of segments containing only bee sounds - Is there any way to make use of this?
By marking these pairs of moments corresponding to the beginning and end of external sound periods, we are able to get the whole recording labeled into Bee and noBee intervals. Thus in the resulting Bee intervals only pure beehive sounds, (no external sounds) should be perceived for the entirety of the segment.
The noBee intervals refer to periods where an external sound can be perceived (superimposed to the bee sounds)"
The sound files are classified as “No queen bee”, “Queen bee present”, “Pipping” and “Swarming”
One sound that caught his attention was a sort of warbling noise that varied between the notes A and C sharp; that’s 225 - 285 Hz in terms of frequency. He noticed that this sound got steadily louder, then it stopped and a day or so later a swarm took off.
Here is the sound of a queen bee piping:
Queen piping is an acoustic signal emitted by a young queen during the process of swarming (fundamental frequency of 330-430 Hz).
Has anyone done anything like this that could help?
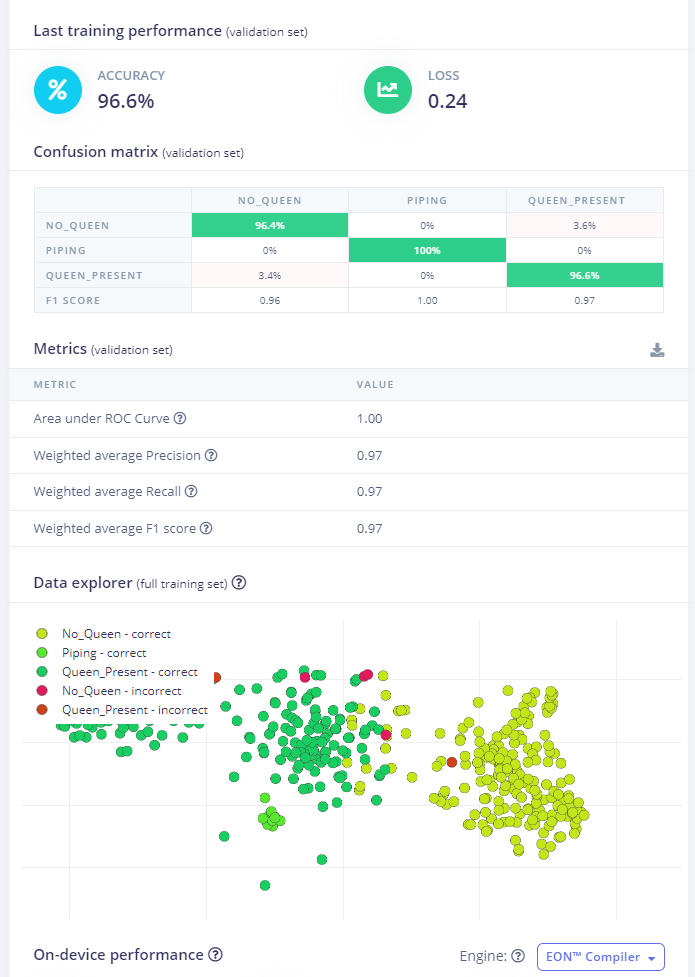
I checked your project, and it looks like you’re getting good accuracy on your classification system. Are you still running into issues getting started?
The model is very bad when running on the phone or PC microphone and playing “piping” sound samples.
Is it best to upload a large number of small 1 minute sound files or is an hour per file ok?
Is it best to mix sounds from various sample sets or stick to one (The quality is quite variable I’ve found).
Is Audio (MFE) the best option for the subtle sound differences?
The current dataset I’m uploading has over 7000 1 minute wav files, they came with a spreadsheet with other environmental data. I used powershell to prefix each sound sample with no_queen or queen before uploading so I could then label them easily. e.g:
I’ve purchased an ESP32-S3 to try and run the model on, I could also record my own sounds on the same MEMS mic that the detection will be running on so that might help?
I could also record my own sounds on the same MEMS mic that the detection will be running on so that might help?
You will often find that you get better results for your particular use case if you collect the data yourself, as a variety of factors can change the data: microphone, environment, type of bees, acoustics of the surroundings, etc. I usually suggest collecting the data with the same sensor you plan to use during inference/deployment. Off-the-shelf datasets can be a good starting point, but they usually don’t exactly model your particular use case or environment.