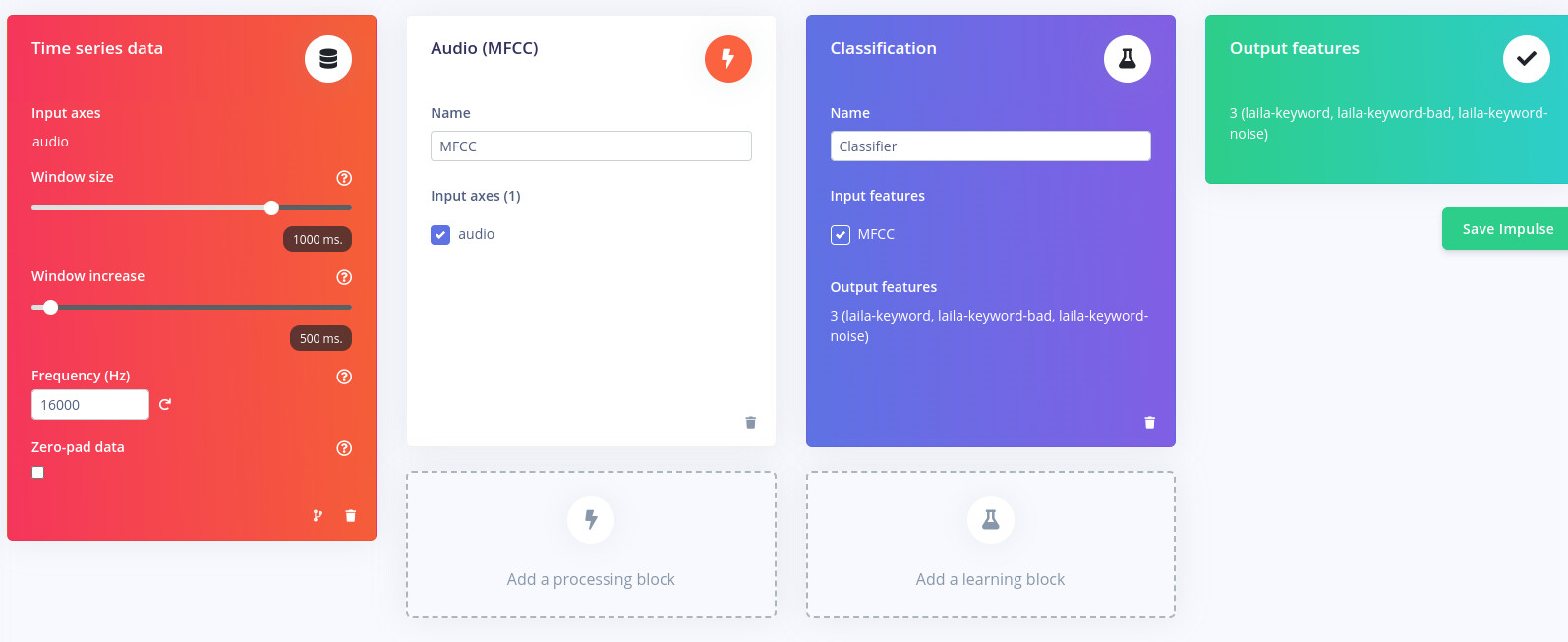
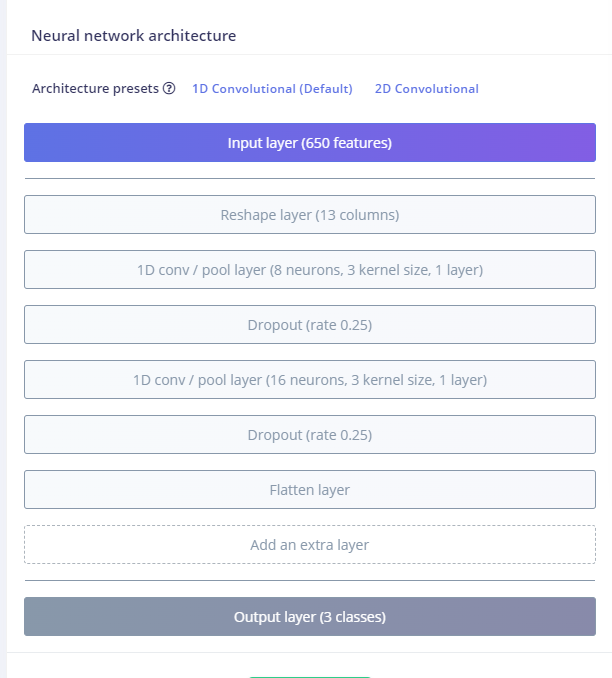
Im trying to make a wakeup model for GitHub - OpenVoiceOS/precise_lite_runner
and keep getting
“self._interpreter.SetTensor(tensor_index, value)
ValueError: Cannot set tensor: Dimension mismatch. Got 3 but expected 2 for input 0.”
looking around i still cant find where i the setting to fix this problem.
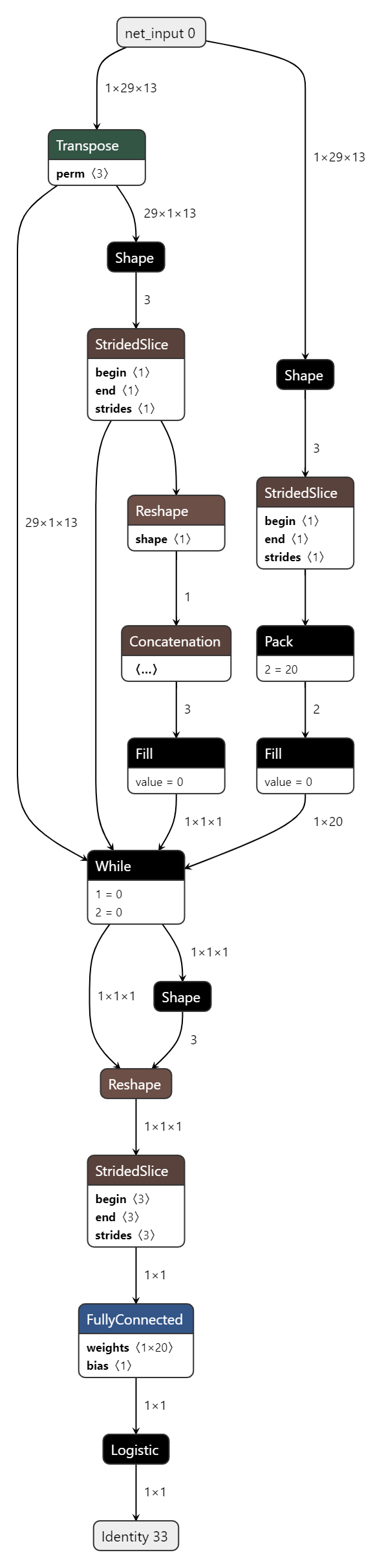
I’m assuming that you downloaded just the TFLite model file from your Edge Impulse project. If you upload it to netron.app, you can see that it expects a 1D input of your features. Those features then get reshaped (via Keras layer) to a 2D array.
For example, your MFCCs (based on the MFCC parameters) might output something like a 61x40 array. However, your model expects a 1D array, so those features get flattened to a 2440-element 1D array before they are sent to the TFLite model.
From this, it looks like you need to flatten your feature array. Try numpy.flatten() or numpy.reshape() to get your feature array into a (1, n) array (where 1 is number of samples (1) and ‘n’ is the total number of features).
The demo model that you posted shows that the input dimension is (1, 29, 13) whereas the second model you posted shows an expected input dimension of (1, 7085). Edge Impulse flattens all of the inputs for all models, hence why it is only 2 dimensions. You will need to modify precise_lite_runner/runner.py if you want it to accept 2-dimensional inputs to models.
As @shawn_edgeimpulse mentioned the model in- and output do not match. This EI audio classifier models expects 1D input and outputs 1D output while your demo model expects 2D input and outputs 1D.
I’m not familiar with the repo you referenced but I took a look at it and made some changes in my fork to fit this Responding to your voice project. Try it by running example.py.
The main changes were setting the in- and output to the right shapes:
output_data = np.ndarray(self.output_details[0]['shape'], dtype=np.float32)
...
...
current = np.array([input]).astype(np.float32).reshape(self.input_details[0]['shape'])
I also disabled calling theshold_decoder.decode(raw_output) as this looked like it tried to convert the raw_output to a probability. Note that demo model outputs a single value while EI models outputs ‘probabilities’ for each label (in my case 3 labels). So it’s also import which index you reference here:
def run(self, inp: np.ndarray) -> float:
return self.predict(inp[np.newaxis])[0][0] # helloworld label is at index 0
In my case, the helloworld index is at 0 so I didn’t have to change anything.
Again, I’m not sure what the application should do and whether the params were correct or disabling the decoder was the right thing to do. But the changes were enough to get the right input shape and output shape. I hope this helps or gives some direction.
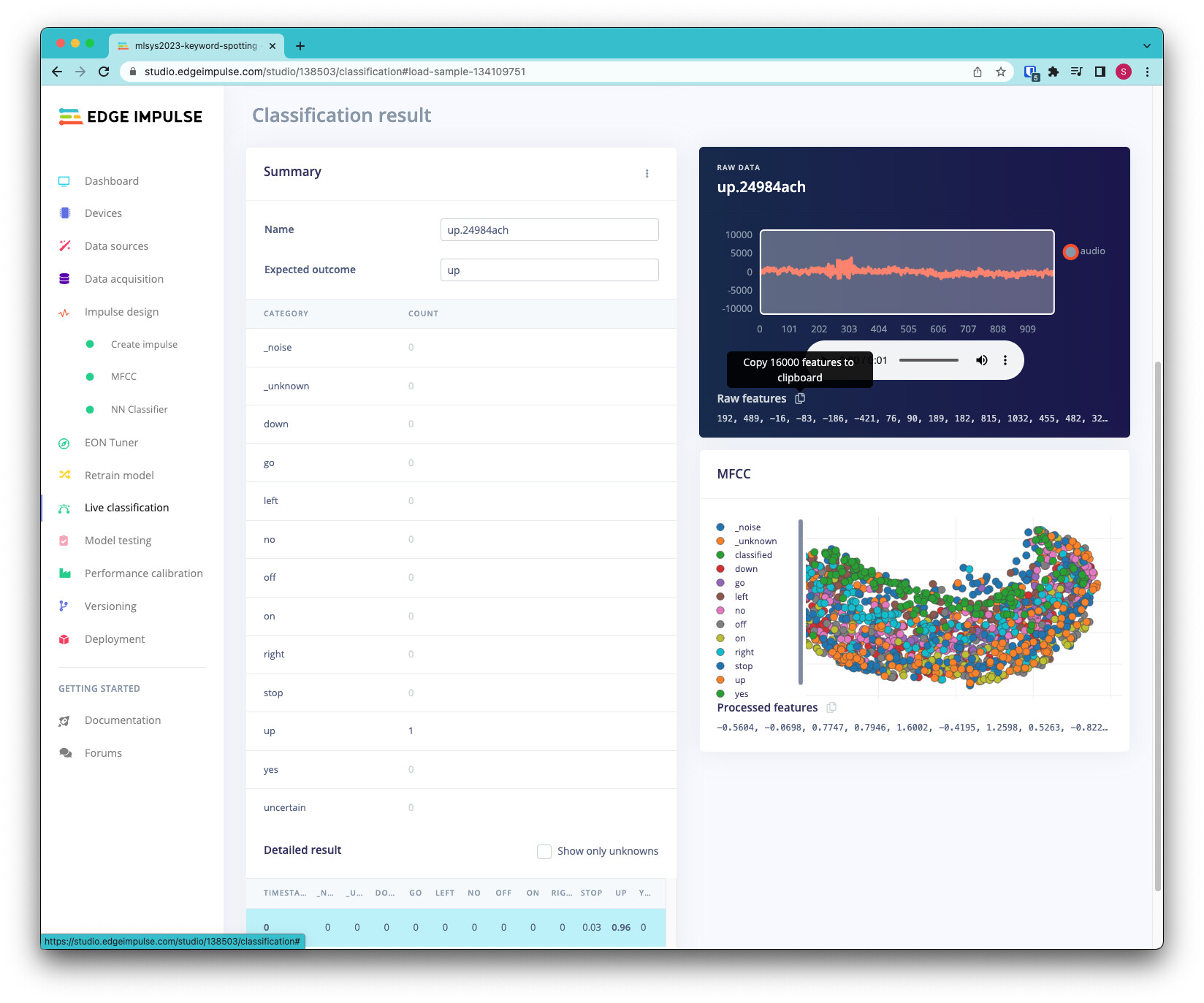
I highly recommend copying the “raw features” from one of your test samples in Edge Impulse and sending that to your model (performing inference with a static set of features) to see if the inference results from your OpenVoiceOS output match up with what you expect (i.e. the inference results in the detailed results of the test page–you can see that “up” should be 93% in the screenshot).
The live classification works excellently, but " return self.predict(inp[np.newaxis])[0][0] " and " return self.predict(inp[np.newaxis])[0][1] " both only respond to white noise (i removed irrelevant voice data from the training data, and left the noise and the keyword )
ouput notes: output data shape: (1, 2) inputS length: 1
This may be due to the input handling of the buffers and the expected model input which is fundamentally different than our model we export. To get this application to work I’m afraid will be too much hacking which will make the application totally different than what it was meant to do.
If you’d like an out-of-the-box example with Python take a look at this audio example from our Linux Python SDK
If in the future you still plan to make the changes. Take a look out how we handle windows, frames and input to the classifer here. And think once this has been handle in your script you’d be good to go.