Hi Eoin,
Thank you for your reply. I tried again using the python SDK but it is still not working. I am getting the following errors:
---------------------------------------------------------------------------
Exception Traceback (most recent call last)
Cell In[4], line 1
----> 1 resp_deploy = ei.model.deploy(model='model.onnx',
2 model_input_type=ei.model.input_type.OtherInput(),
3 model_output_type=ei.model.output_type.Classification(),
4 representative_data_for_quantization='validation_data.npy',
5 output_directory='.')
File ~/miniconda3/envs/torch_env/lib/python3.10/site-packages/edgeimpulse/model/_functions/deploy.py:250, in deploy(model, model_output_type, model_input_type, representative_data_for_quantization, deploy_model_type, engine, deploy_target, output_directory, api_key, timeout_sec)
248 except Exception as e:
249 logging.debug(f"Exception calling save_pretrained_model_parameters [{str(e)}]")
--> 250 raise e
252 target_names = get_project_deploy_targets(client, project_id=project_id)
253 if deploy_target not in target_names:
File ~/miniconda3/envs/torch_env/lib/python3.10/site-packages/edgeimpulse/model/_functions/deploy.py:244, in deploy(model, model_output_type, model_input_type, representative_data_for_quantization, deploy_model_type, engine, deploy_target, output_directory, api_key, timeout_sec)
240 try:
241 r = SavePretrainedModelRequest.from_dict(
242 {"input": model_input_type, "model": model_output_type}
243 )
--> 244 response = learn.save_pretrained_model_parameters(
245 project_id=project_id, save_pretrained_model_request=r
246 )
247 check_response_errors(response)
248 except Exception as e:
File ~/miniconda3/envs/torch_env/lib/python3.10/site-packages/pydantic/decorator.py:40, in pydantic.decorator.validate_arguments.validate.wrapper_function()
File ~/miniconda3/envs/torch_env/lib/python3.10/site-packages/pydantic/decorator.py:134, in pydantic.decorator.ValidatedFunction.call()
File ~/miniconda3/envs/torch_env/lib/python3.10/site-packages/pydantic/decorator.py:206, in pydantic.decorator.ValidatedFunction.execute()
File ~/miniconda3/envs/torch_env/lib/python3.10/site-packages/edgeimpulse_api/api/learn_api.py:2487, in LearnApi.save_pretrained_model_parameters(self, project_id, save_pretrained_model_request, **kwargs)
2463 """Save parameters for pretrained model
2464
2465 Save input / model configuration for a pretrained model. This overrides the current impulse. If you want to deploy a pretrained model from the API, see `startDeployPretrainedModelJob`.
(...)
2484 :rtype: GenericApiResponse
2485 """
2486 kwargs['_return_http_data_only'] = True
-> 2487 return self._save_pretrained_model_parameters_with_http_info(project_id, save_pretrained_model_request, **kwargs)
File ~/miniconda3/envs/torch_env/lib/python3.10/site-packages/pydantic/decorator.py:40, in pydantic.decorator.validate_arguments.validate.wrapper_function()
File ~/miniconda3/envs/torch_env/lib/python3.10/site-packages/pydantic/decorator.py:134, in pydantic.decorator.ValidatedFunction.call()
File ~/miniconda3/envs/torch_env/lib/python3.10/site-packages/pydantic/decorator.py:206, in pydantic.decorator.ValidatedFunction.execute()
File ~/miniconda3/envs/torch_env/lib/python3.10/site-packages/edgeimpulse_api/api/learn_api.py:2591, in LearnApi._save_pretrained_model_parameters_with_http_info(self, project_id, save_pretrained_model_request, **kwargs)
2585 _auth_settings = ['ApiKeyAuthentication', 'JWTAuthentication', 'JWTHttpHeaderAuthentication'] # noqa: E501
2587 _response_types_map = {
2588 '200': "GenericApiResponse",
2589 }
-> 2591 return self.api_client.call_api(
2592 '/api/{projectId}/pretrained-model/save', 'POST',
2593 _path_params,
2594 _query_params,
2595 _header_params,
2596 body=_body_params,
2597 post_params=_form_params,
2598 files=_files,
2599 response_types_map=_response_types_map,
2600 auth_settings=_auth_settings,
2601 async_req=_params.get('async_req'),
2602 _return_http_data_only=_params.get('_return_http_data_only'), # noqa: E501
2603 _preload_content=_params.get('_preload_content', True),
2604 _request_timeout=_params.get('_request_timeout'),
2605 collection_formats=_collection_formats,
2606 _request_auth=_params.get('_request_auth'))
File ~/miniconda3/envs/torch_env/lib/python3.10/site-packages/edgeimpulse_api/api_client.py:400, in ApiClient.call_api(self, resource_path, method, path_params, query_params, header_params, body, post_params, files, response_types_map, auth_settings, async_req, _return_http_data_only, collection_formats, _preload_content, _request_timeout, _host, _request_auth)
359 """Makes the HTTP request (synchronous) and returns deserialized data.
360
361 To make an async_req request, set the async_req parameter.
(...)
397 then the method will return the response directly.
398 """
399 if not async_req:
--> 400 return self.__call_api(resource_path, method,
401 path_params, query_params, header_params,
402 body, post_params, files,
403 response_types_map, auth_settings,
404 _return_http_data_only, collection_formats,
405 _preload_content, _request_timeout, _host,
406 _request_auth)
408 return self.pool.apply_async(self.__call_api, (resource_path,
409 method, path_params,
410 query_params,
(...)
418 _request_timeout,
419 _host, _request_auth))
File ~/miniconda3/envs/torch_env/lib/python3.10/site-packages/edgeimpulse_api/api_client.py:237, in ApiClient.__call_api(self, resource_path, method, path_params, query_params, header_params, body, post_params, files, response_types_map, auth_settings, _return_http_data_only, collection_formats, _preload_content, _request_timeout, _host, _request_auth)
234 # deserialize response data
236 if response_type:
--> 237 return_data = self.deserialize(response_data, response_type)
238 else:
239 return_data = None
File ~/miniconda3/envs/torch_env/lib/python3.10/site-packages/edgeimpulse_api/api_client.py:306, in ApiClient.deserialize(self, response, response_type)
303 data = json.loads(response.data)
305 if not data["success"]:
--> 306 raise Exception(data["error"])
308 except ValueError:
309 data = response.data
Exception: socket hang up
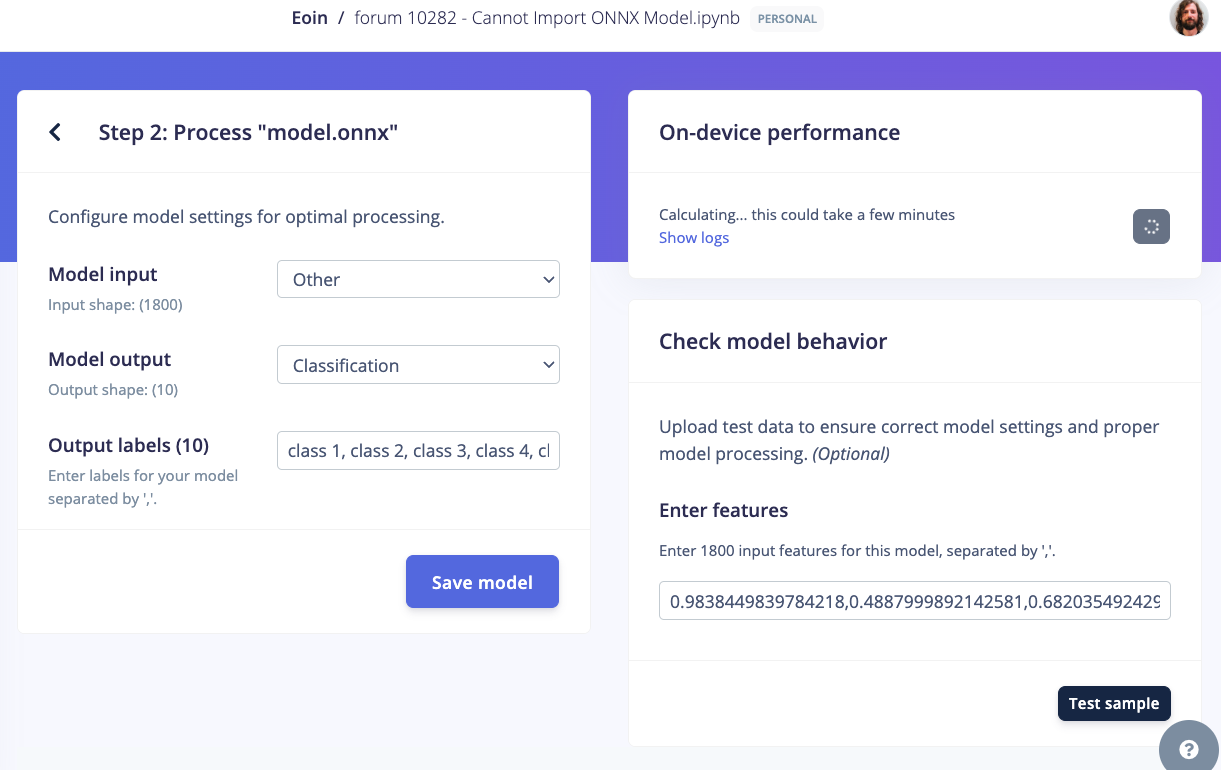
The command I am using is:
resp_deploy = ei.model.deploy(model='model.onnx',
model_input_type=ei.model.input_type.OtherInput(),
model_output_type=ei.model.output_type.Classification(),
representative_data_for_quantization='validation_data.npy',
output_directory='.')
I am also seeing this error in the EI Studio:
Failed to calculate performance
Creating job… OK (ID: 18372417) OK (ID: 18372418) Scheduling job in cluster… Scheduling job in cluster… Container image pulled! Container image pulled! Job started Job started Scheduling job in cluster… Scheduling job in cluster… Container image pulled! Job started Container image pulled! Job started Profiling model_quantized_int8_io.tflite… Profiling model_quantized_int8_io.tflite… Error converting model for EON RAM optimized mode: Calculating performance metrics… Calculating inferencing time… Aborted (core dumped) Error while calculating inferencing time: substring not found Traceback (most recent call last): File “/app/./resources/libraries/ei_tensorflow/profiling.py”, line 1159, in profile_tflite_file metadata[‘performance’] = json.loads(a[a.index(‘{’):a.index(‘}’)+1]) ValueError: substring not found Determining whether this model runs on MCU… Determining whether this model runs on MCU OK Profiling model_quantized_int8_io.tflite OK Profiling model.tflite… Error converting model for EON RAM optimized mode: Calculating performance metrics… Calculating inferencing time… Aborted (core dumped) Error while calculating inferencing time: substring not found Traceback (most recent call last): File “/app/./resources/libraries/ei_tensorflow/profiling.py”, line 1159, in profile_tflite_file metadata[‘performance’] = json.loads(a[a.index(‘{’):a.index(‘}’)+1]) ValueError: substring not found Determining whether this model runs on MCU… Determining whether this model runs on MCU OK Profiling model_quantized_int8_io.tflite OK Profiling model.tflite… Error converting model for EON RAM optimized mode: Calculating performance metrics… Calculating inferencing time… INFO: Created TensorFlow Lite XNNPACK delegate for CPU. Error converting model for EON RAM optimized mode: Calculating performance metrics… Calculating inferencing time… INFO: Created TensorFlow Lite XNNPACK delegate for CPU. Calculating inferencing time OK Determining whether this model runs on MCU… Determining whether this model runs on MCU OK Profiling float32 model (TensorFlow Lite Micro)… Calculating inferencing time OK Determining whether this model runs on MCU… Determining whether this model runs on MCU OK Profiling float32 model (TensorFlow Lite Micro)… Profiling float32 model (TensorFlow Lite Micro, HW optimizations disabled)… Profiling float32 model (TensorFlow Lite Micro, HW optimizations disabled)… Profiling float32 model (EON)… Profiling float32 model (EON)… Profiling float32 model (EON, HW optimizations disabled)… Profiling float32 model (EON, HW optimizations disabled)… Profiling model.tflite OK Profiling model.tflite OK socket hang up Job failed (see above)
Can you verify that we are uploading the same model? This is generated by netron:
I also tried a simple conv model without the skip connections, and that uploads fine. However, there are some issues with automatic quantization. The quantized model has extremely low performance (accuracy dropped from 78% to 10%). My model takes input of size (1800), so I created the npy as a 2D array or shape (B, 1800), where B is the validation dataset size. Is this the correct way of providing the representative data?