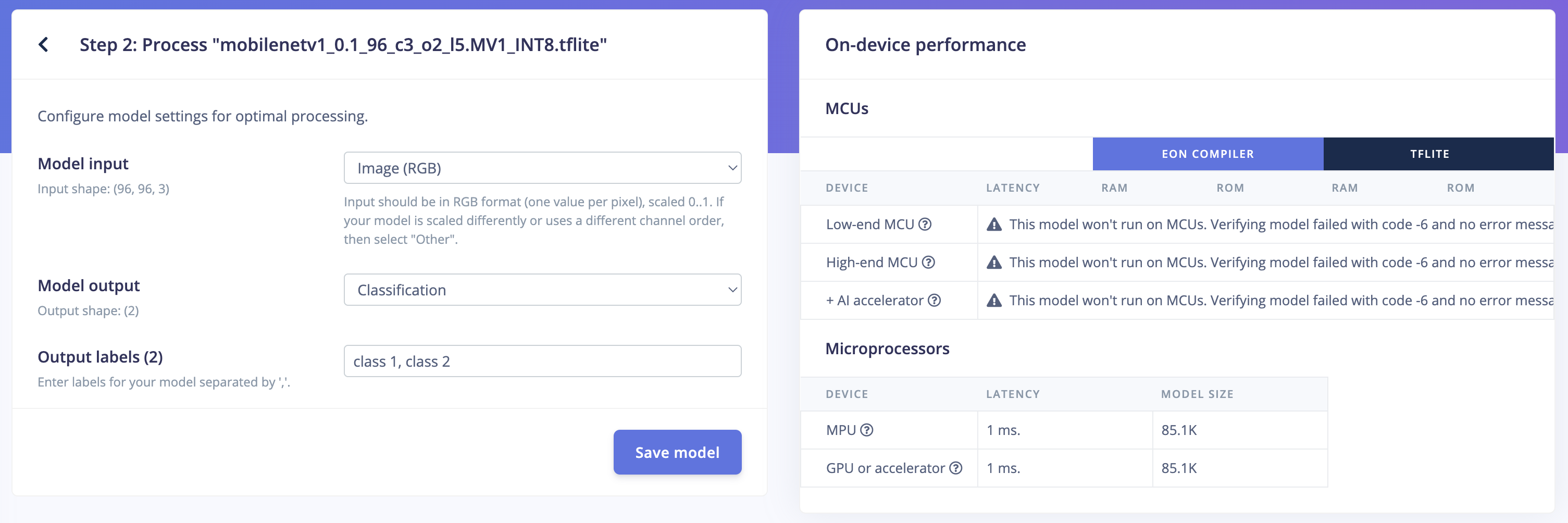
I am trying to profile my first own models on ‘cortex-m7-216mhz’ and run into the following error message: mcuSupportError: Verifying model failed with code -6 and no error message
Where can I find an overview of the error codes?
I am also noticing unexpected behavior when I profile the same model in unquantized and quantized (8 INT) version. The unquantized version works fine, but the quantized version is throwing the above error. I have been profiling the same models with STM32Cube.AI runtime without any issues on STM32F746G-Disco.
That’s an error thrown by the EON compiler when validating the model.
Could you share your model with me so our core engineering team can have a look?
You can email me at louis@edgeimpulse.com if needed.
Random weights is fine.
'edge-impulse-sdk/tensorflow/lite/micro/kernels/quantize.cc:68 input->type == kTfLiteFloat32 || input->type == kTfLiteInt16 || input->type == kTfLiteInt8 was not true[.\r\r\nNode](https://vscode-remote+wsl-002bubuntu-002d20-002e04.vscode-resource.vscode-cdn.net/mnt/c/tiny_mlc/tiny_cnn/r/r/nNode) QUANTIZE (number 0f) failed to prepare with status 1
@dansitu had a quick look today.
Would it be possible to share the code that you used to convert the model to tflite as well?
It seems that your model is taking uint8 inputs then quantizing them again before output? Not entirely sure though.
Hi @louis and @dansitu,
here is the code used to convert to TFLite INT8:
repr_ds = test_ds.unbatch()
def representative_data_gen():
for i_value, o_value in repr_ds.batch(1).take(48):
yield [i_value]
converter_opt = tf.lite.TFLiteConverter.from_keras_model(model)
# set the optimization flag
converter_opt.optimizations = [tf.lite.Optimize.DEFAULT]
# enforce integer only quantization
converter_opt.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# https://github.com/tensorflow/tensorflow/issues/53293: uint is no longer supported!
#converter_opt.inference_input_type = tf.uint8
#converter_opt.inference_output_type = tf.uint8
converter_opt.inference_input_type = tf.int8
converter_opt.inference_output_type = tf.int8
# provide a representative dataset for quantization
converter_opt.representative_dataset = representative_data_gen
tflite_model_opt = converter_opt.convert()
# Save the model.
with open(models_tflite_opt_path, 'wb') as f:
f.write(tflite_model_opt)
models_tflite_opt_path
Thank you for sharing, and sorry you’re having trouble.
The tflite model file you shared with @louis expects uint8 inputs and outputs. I see the line converter_opt.inference_input_type = tf.uint8 is commented in the code you provided. Is there any chance the tflite model file you are using was produced with an earlier version of the code before the uint8 lines were commented?
I believe the issue is that your model expects uint8 inputs but is then attempting to quantize them using the quantize operator. We use TFLite 2.4 during profiling, and its quantize operator does not support a uint8 input and int8 output, so it’s failing.
Does your original model (before quantization) accept uint8 inputs? If so, a workaround could be to use float inputs during training instead of uint8. That way, quantization would work normally.
I just double checked by reconverting the model with tf.int8 input and output but the problem persists. The original training data is float32. Tensorflow version 2.10.0 on Win 10.
“This model won’t run on MCUs. Verifying model failed with code -6 and no error message”.
Peak memory of this model is less than 56kB so this should not be an issue.
Thanks for your reply. Since the original training data is float32 it sounds likely that something is going wrong during the quantization process.
Edge Impulse should be able to do the quantization for you if you provide a numpy array with representative data (a few dozen samples of your training data that cover the range of values you’re expecting to see in normal use). There’s instructions on how to do this in our SDK here, in the “Quantization” section:
The items in the array should have the same shape as the input tensor of your model.
I recommend giving this a try: it should at least help us understand if the issue is with the quantization code.
@subrockmann The model is hitting an assert when preparing the softmax kernel as it takes the wrong code path. Will debug.
update #1: So the interesting bit is that this hits an assert in both latest TFLM and in TensorFlow Lite w/ reference kernels (but not w/ optimized kernels). It hits PreprocessSoftmaxScaling, then goes to QuantizeMultiplierGreaterThanOne but input_beta_real_multiplier is <1 so it asserts (assertion is for >1.0f).
@subrockmann every example image that I throw through your model yields [0, 0] (raw output) / [0.5, 0.5] (after dequantization) as probabilities when running the model in TensorFlow 2.11 (via Python, both your f32 and i8 version); do you have an example input that yields something else so I can verify that any change we make in our SDK is actually correct? You can either add it to the project or email me directly at jan@edgeimpulse.com
I’ll also open up a PR against TensorFlow once we have this fixed.