Hi @louis ,
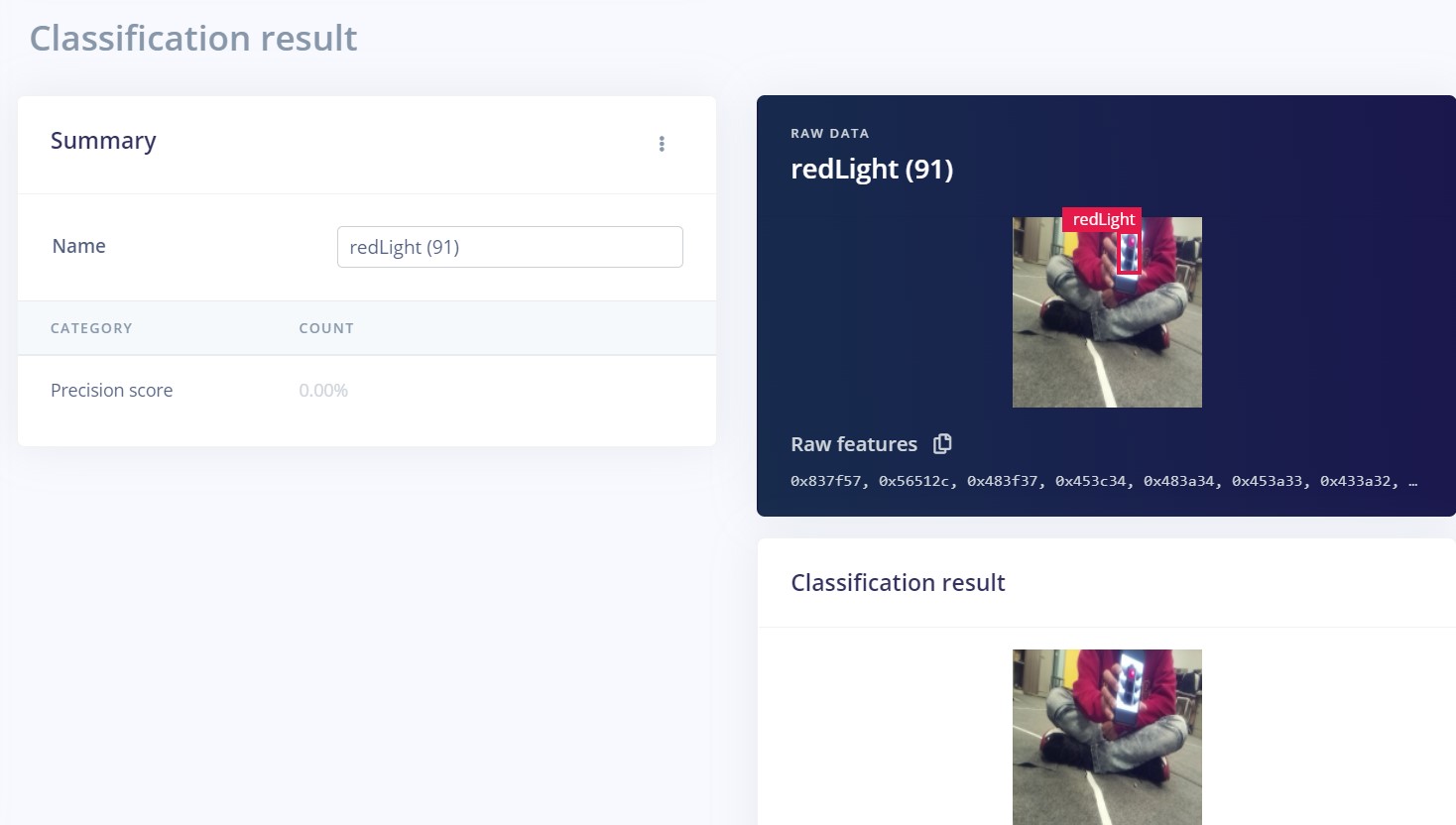
Thank you for your help! We trained our model with 50 training cycles, 0.15 learning rate, and a 20% validation size. With this, we were able to get a much higher accuracy!
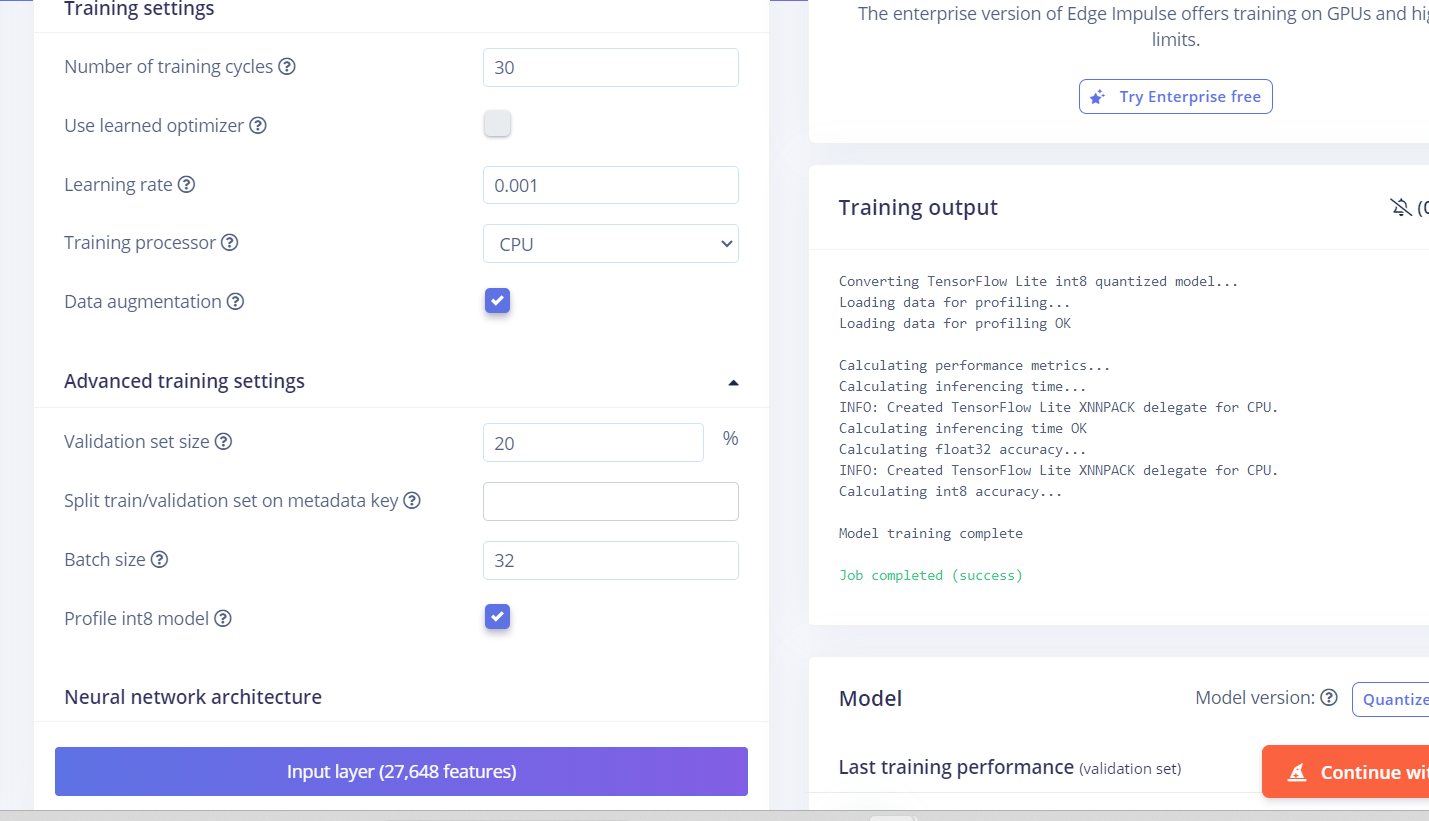
However, when we played around with the training model and lowered the learning rate to 0.13, we received these errors:
Attached to job 2841135…
Calculating performance metrics…
Calculating inferencing time…
ERROR: /app/tensorflow-2.4.1/tensorflow/lite/kernels/detection_postprocess.cc:426 ValidateBoxes(decoded_boxes, num_boxes) was not true.
ERROR: Node number 156 (TFLite_Detection_PostProcess) failed to invoke.
ERROR: /app/tensorflow-2.4.1/tensorflow/lite/kernels/detection_postprocess.cc:426 ValidateBoxes(decoded_boxes, num_boxes) was not true.
ERROR: Node number 156 (TFLite_Detection_PostProcess) failed to invoke.
ERROR: /app/tensorflow-2.4.1/tensorflow/lite/kernels/detection_postprocess.cc:426 ValidateBoxes(decoded_boxes, num_boxes) was not true.
ERROR: Node number 156 (TFLite_Detection_PostProcess) failed to invoke.
ERROR: /app/tensorflow-2.4.1/tensorflow/lite/kernels/detection_postprocess.cc:426 ValidateBoxes(decoded_boxes, num_boxes) was not true.
ERROR: Node number 156 (TFLite_Detection_PostProcess) failed to invoke.
ERROR: /app/tensorflow-2.4.1/tensorflow/lite/kernels/detection_postprocess.cc:426 ValidateBoxes(decoded_boxes, num_boxes) was not true.
ERROR: Node number 156 (TFLite_Detection_PostProcess) failed to invoke.
ERROR: /app/tensorflow-2.4.1/tensorflow/lite/kernels/detection_postprocess.cc:426 ValidateBoxes(decoded_boxes, num_boxes) was not true.
ERROR: Node number 156 (TFLite_Detection_PostProcess) failed to invoke.
ERROR: /app/tensorflow-2.4.1/tensorflow/lite/kernels/detection_postprocess.cc:426 ValidateBoxes(decoded_boxes, num_boxes) was not true.
ERROR: Node number 156 (TFLite_Detection_PostProcess) failed to invoke.
ERROR: /app/tensorflow-2.4.1/tensorflow/lite/kernels/detection_postprocess.cc:426 ValidateBoxes(decoded_boxes, num_boxes) was not true.
ERROR: Node number 156 (TFLite_Detection_PostProcess) failed to invoke.
ERROR: /app/tensorflow-2.4.1/tensorflow/lite/kernels/detection_postprocess.cc:426 ValidateBoxes(decoded_boxes, num_boxes) was not true.
ERROR: Node number 156 (TFLite_Detection_PostProcess) failed to invoke.
ERROR: /app/tensorflow-2.4.1/tensorflow/lite/kernels/detection_postprocess.cc:426 ValidateBoxes(decoded_boxes, num_boxes) was not true.
ERROR: Node number 156 (TFLite_Detection_PostProcess) failed to invoke.
Calculating inferencing time OK
Profiling float32 model…
Model training complete
Job completed
Model
Creating job… OK (ID: 2841210)
Generating features for Image…
Not generating new features: features already generated and no options or files have changed.
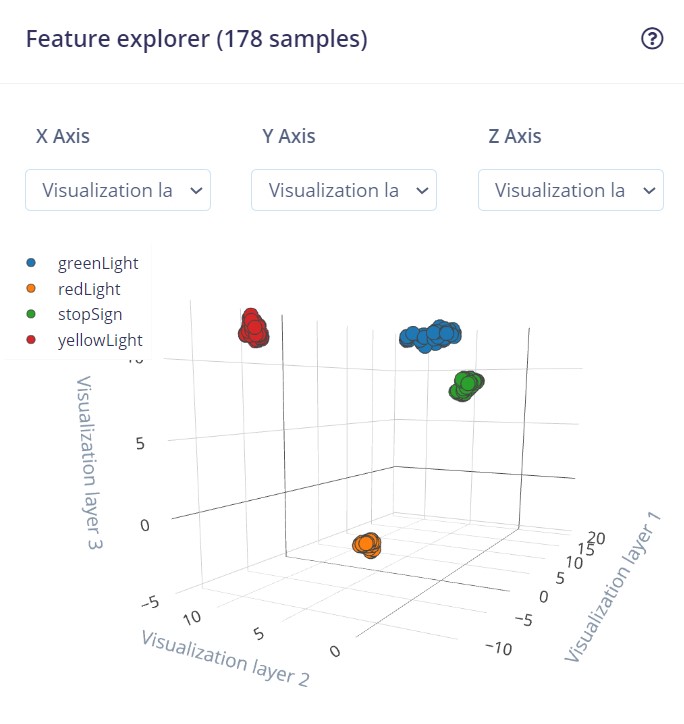
Reducing dimensions for Image…
Scheduling job in cluster…
Job started
Reducing dimensions for visualizations…
ERR: Expected 2D array, got 1D array instead:
array=[].
Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
Application exited with code 1
Could you please help us understand what caused this error and how to avoid it in the future?
Thank you again!