I’m trying to classify baby cry audio aka what is the reason for crying.
The project can be found here: cry_classifciation_with_only_donateacry_community_ver
I found an open dataset of labelled baby cries that I’m using.
The goal is to later use Arduino Nano BLE 33 sense to detect reason’s for when a baby is crying. I also added some ambient sound collected through the Nano and the data forwarder.
I first want to see, how this dataset can be used increase accuracy while classifying in Edge impulse training mode. Later on the idea is to
I am not an ML engineer, so I’m trying out various combinations.
In the impulse design I have set the window size to be 3 secs as the wave files are 7 secs long.
In the impulse design I’ve used an MFE block.
And, also used a classifier block.
MFE Block parameters are as below that I used to generate features:
Mel-filterbank energy features
Frame length: 0.02
Frame stride: 0.01
Filter number: 40
FFT length: 256
Low frequency: 80
High frequency: 0
Normalization
Noise floor (dB): -78
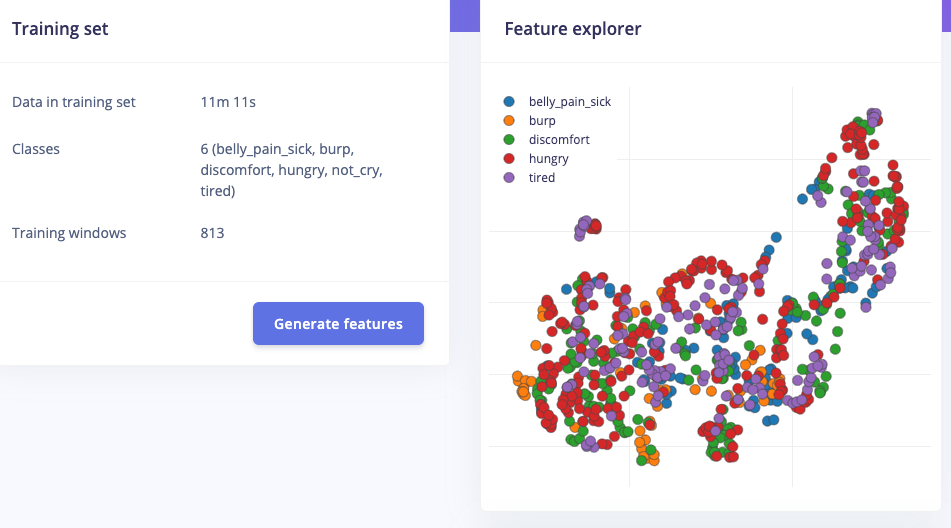
The features are not very unique as you can see below (Baby cries are almost all the same and the dataset is not a compete, I guess no dataset is complete, but I’m lucky that it exists):
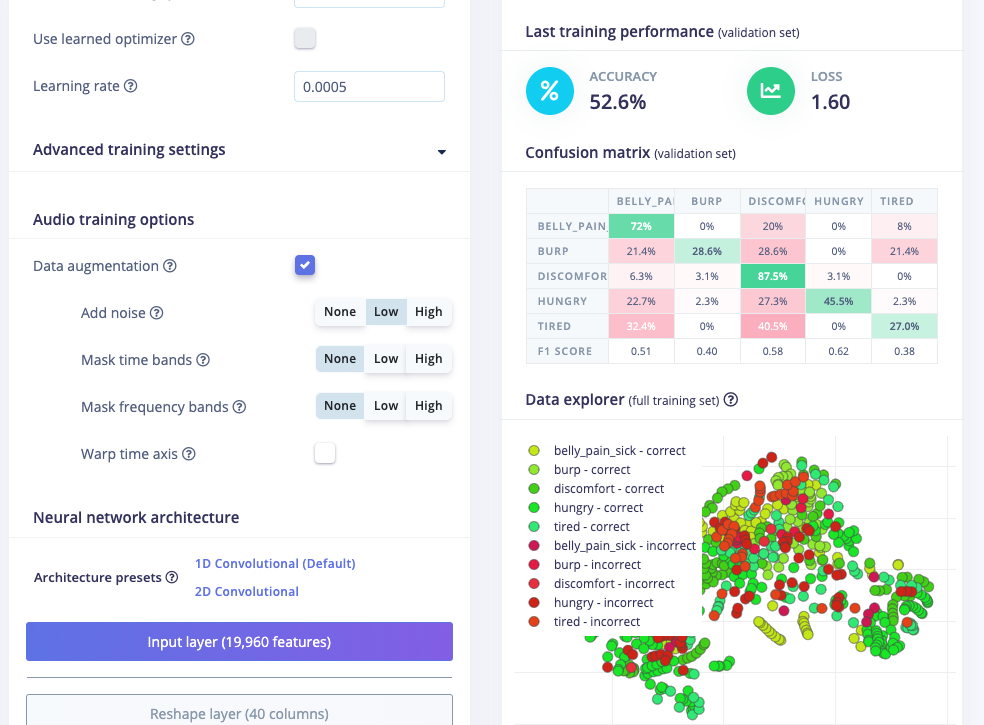
After few trial and error, with a training cycle of 400 and learning rate of 0.0005, with some added noise through data augmentation (enabled), and a 1D conv NN (Default one) I was able to achieve an accuracy of: 50-55% approximately with a loss of 0.6-1.2.
Before I move ahead, I wanted to ask the experts, if some one has expertise with these kind of audio data and has some ideas on how to increase the accuracy, essentially improving training strategy.
All help is sincerely appreciated.
@davidtischler_edgeim maybe you have seen some projects like this and can offer some advice?
Did you want to productise this or is it just for experimentation @dattasaurabh82? If so we could look at some enterprise features, and try get a trial set up so you can see if it can improve the results.
Hi @Eoin ,
So right now I’m trying both the community version and enterprise trial (only 2-3 days left).
Anyways, with both the same impulse settings and the MFE blocks and the default 1D conv nn arch in place, it produces similar results in all 3 instances (comm version and the ent version)
If, you would require the enterprise hosted project instances, I can share those links here too.
For now, I’m exploring if it would be possible to do this at all through nano BLE 33 sense, for an open source POC. We do not know at this moment if we will have a client consider this to be some sort of a product in the future. This is just me tinkering in my workshop
Hi @dattasaurabh82 - I have seen baby cry detection projects, but not any classification projects. This is definitely interesting, and something I have not come across previously. Hope you get it working well!
Yes I’m still trying. We found another dataset: https://data.mendeley.com/datasets/hbppd883sd/1
Has mostly “hungry” and “discomfort” data. So pulled those in and added some ambient sound. The data is a bit skewed (we have more diverse hungry and discomfort data points) now but I don’t know if that would affect the process.
Hello again,
Sorry for the radio silence. I was busy getting some decent data.
The new project can be found here (Many vers for many tests )
For 5 labels, including one for “background noise”, I have achieved more than 90% accuracy and in “model testing”, more than 85%. You can see the settings there at the moment.
if then I export the Arduino lib (my target is Arduino Nano 33 BLE sense rev2) or the binary for nano, and try to cont audio example or run the edge-impulse-run-impulse , I get:
Starting inferencing in 2 seconds...
Recording...
Recording done
ERR: failed to allocate tensor arena
Failed to initialize the model (error code 1)
ERR: Failed to run classifier (-6)
If I then do the EON Tuner (latency set to 2000 ms, same as my “window”) for “Keyword Spotting”, the best setup I get is for MFE based setup whose efficiency gets reduced to 75%.
And then if I export a binary for nano or the Arduino lib and try to run the cont audio example without any modifications, I get:
Inferencing settings:
Interval: 0.12 ms.
Frame size: 48000
Sample length: 3000 ms.
No. of classes: 5
ERR: Could not allocate audio buffer (size 48000), this could be due to the window length of your model
After testing and tweaking I got it to work.
Now the accuracy in 95%, in test it is 85% (more than enough for my POC).
Export to Arduino Library is also working.