Hello, I have improvement idea for Edge Impulse data collection for ML training.
I have very limited amount of event data (10 minutes) and I want to pair that up with 10 minutes of as diverse noise as possible.
I have hours of noise, but most of it is very similar (background hum etc.)
If I want to make my noise as diverse as possible, I must manually comb through the samples as remove the similar ones to make room for more diverse noise.
If I didn’t remove redundant samples I would have 90% noise and 10% event, which will make the model training impossible
Edge Impulse already has a nice data explorer feature (data clustering):
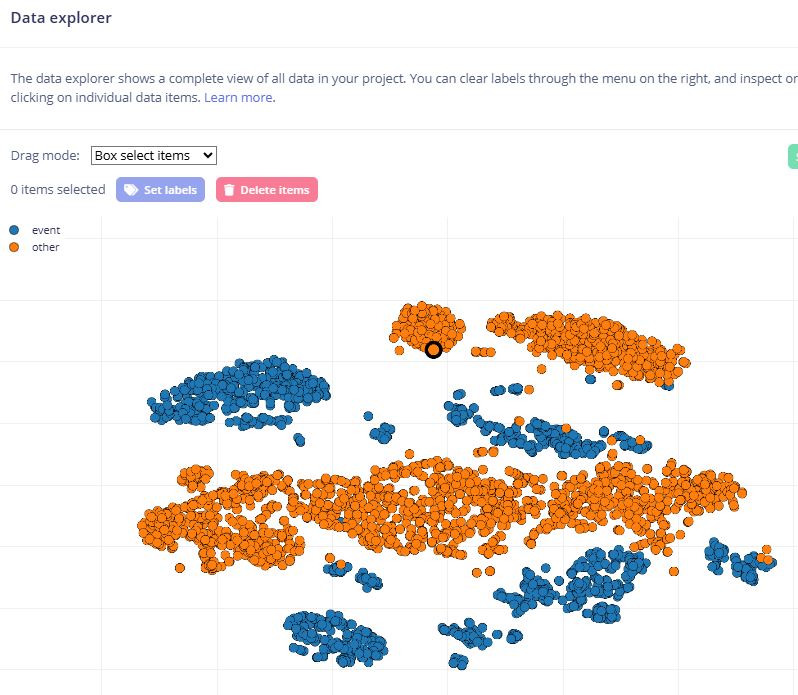
My idea is to add automated “data filtering” to impulse pipeline! This would automatically prune redundant samples from each cluster evenly. User could adjust how much they want to prune from each cluster (0-100%)
Another way to achieve this is cluster sampling, and there might be other methods too. Any method is fine, as long as end goal is satisfied.
End goal: Automated diversification of collected data
When “data filtering” phase is in impulse, you can add more different strategies to filter data for different use cases. Lets make edge impulse the best tool for ML.
Thank you!