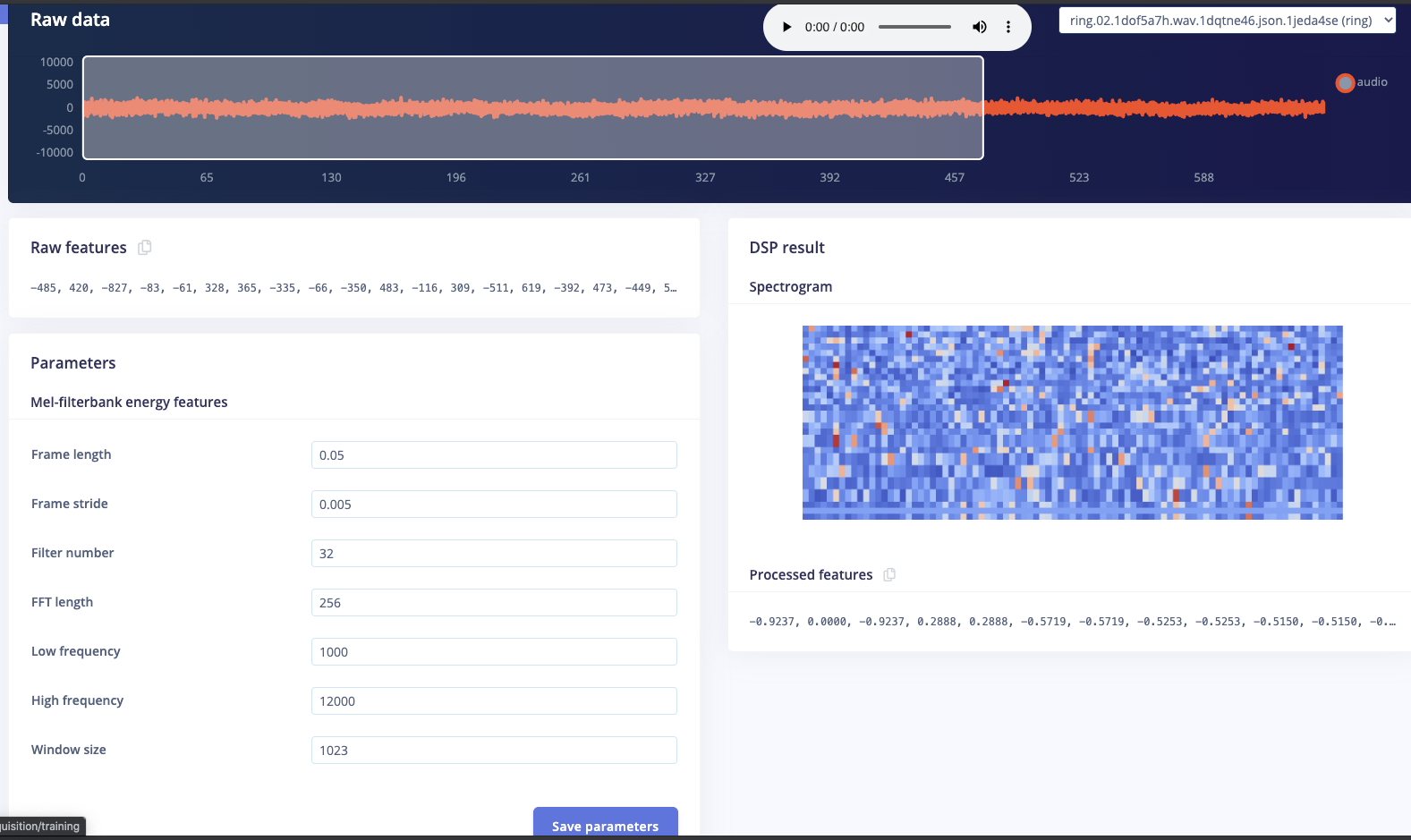
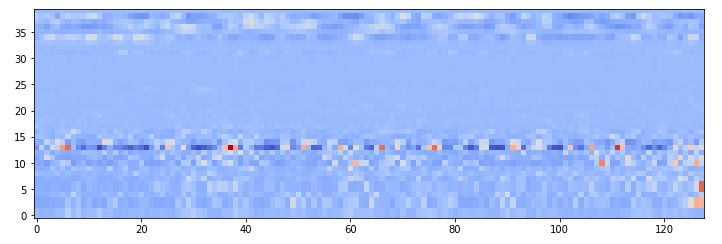
I’m wondering if it’s possible to get a pure spectrogram out of the audio processing block rather than the MFCCs. While I know the MFCCs are better for speech, I’ve had some luck (with reduced accuracy) using a 2D CNN on just a spectrogram, where I average every 3-5 bins together. I find that the DCT takes a good chunk of processing power, so I was wondering if there’s a way we can avoid using it.
Additionally, is there a way to get the audio processing block to output a 2D array? Even in the NN step, you could put a “Flatten” layer first to do (I assume) the same thing if you wanted to use a 1D CNN. I’d love to play around with 1D vs. 2D CNNs for audio processing to see if that helps with accuracy and speed at all.
If there’s not a current way to do this, I’ll call this a feature request. In the meantime, I could start learning how to make my own custom processing blocks
Hey @ShawnHymel! We’ve been thinking internally about adding a block for basic spectrograms, and your request gives this some more weight.
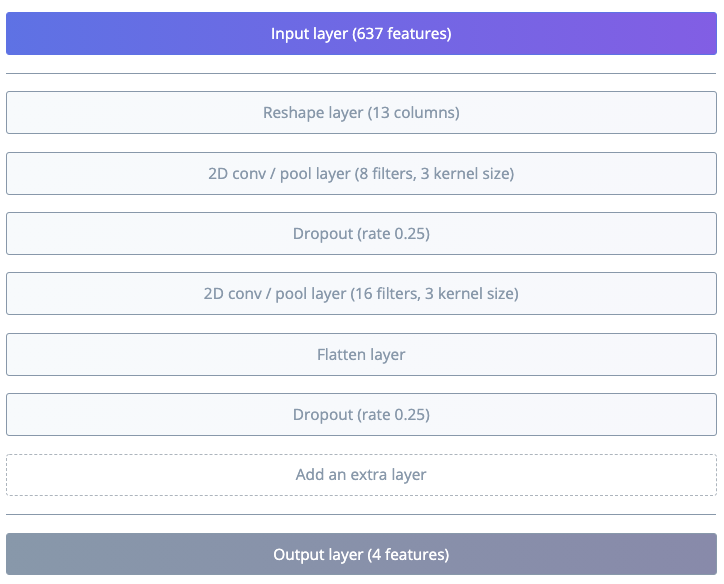
It’s super easy to reshape into 2D: just make sure there’s a reshape layer in the visual editor, and behind the scenes we’ll use the appropriate reshape for the layer that follows it. So if your layers look like this example it will work:
I’m actually working right now on a really cool feature that will make it much easier to experiment with 1D and 2D convolutional architectures. You’ll see it land in the next week or two
@aurel - Not yet–I’ll give spectral features a shot and see if they work. Without a spectrogram, I’m worried that I’m losing the time-sequence nature of the spoken word.
@dansitu and @janjongboom - that’s great news! I’m excited to try that block when it comes out. Are you able to profile feature generation on baseline hardware like you’re doing for inference? I’d love to know, for example, how many milliseconds it’s predicted to do MFCCs or calculate a spectrogram on an 80-MHz ARM.
@ShawnHymel, we don’t have it in the Studio yet, but here’s baseline numbers for a variety of models: https://docs.edgeimpulse.com/docs/inference-performance-metrics - note that you can implement continuous audio sampling which feeds small slices of audio into MFCC / spectrogram DSP code and then assembles the final DSP result again for inference, that way you can do 4 inferences a second on a typical M4F without missing any events.
Spectrogram will have similar performance to MFCC (a little faster, but you have a lot more features so the network is bigger).
@janjongboom - Good to know, thank you! I didn’t think about the tradeoff of using a larger network (as the MFCC input is smaller), so that makes sense.
@janvda we fixed this in production now. Your signal with frame length 0.01, frame stride 0.002, filter number 80, FFT length 256, low frequency 300, high frequency 0.
Using the low/high frequency fields as a bandpass filter is not really supported, these are inner parameters for the MFE calculation. Maybe we should hide them and replace with a proper bandpass filter…