I read the article written by @janjongboom. The article mentions MFCC for human speech/voice and MFE for non-human voice. why is MFCC good for human speech and MFE good for non-human voice?Is there any research or paper that explains this?
I have run training NN, but I got the result ‘job failed’:
I have decreased the number of windows to 250ms from 500ms, but still got the same error job failed. this happened after I had EON Tuner running, and I’ve re-train the suggested NN architecture. previously with the same data, a bigger number of windows up to 1000ms running smoothly. does the error have any effect after I run the EON tuner?
on the EON tuner that I run why is there only 2D Conv? no network type 1D Conv as in the documentation?
@AlexE maybe you could elaborate a bit more on the difference between the two methods and why one applies better to human-voice?
The Deadline exceed error comes from the job’s time limit that comes with your developer account. It is set by default to 20 min. I just increased it to 60 minutes so you should not have this error again.
That’s a good question. Maybe it is because of the target you selected, the Raspberry pi. The EON tuner is trying to define the best dsp and architecture based on your constraints. @mathijs maybe you have a better explanation?
thanks for answering my question. now I can run NN training with enough time.
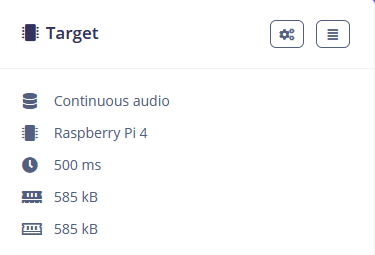
this is my EON target:
what is the difference between using time inference 500 ms and 1000 ms? I feel like there is no significant difference when I deploy to raspi4?
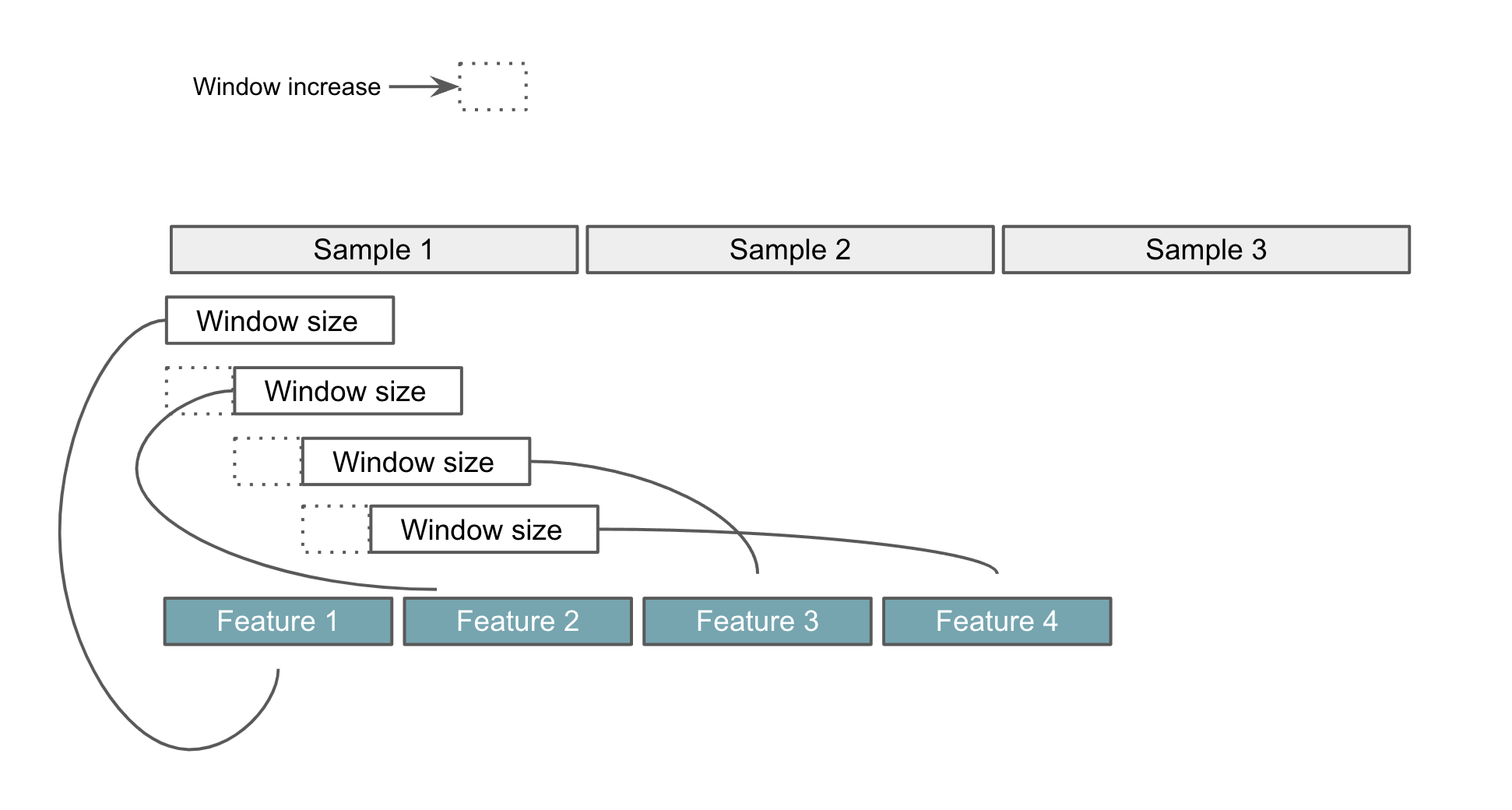
if I am using 1000ms windows size and windows increase 500ms, what is the best setting for EON?
This setting is used to define the maximum time to run the inference (DSP + NN).
I am not sure it takes into account the window size though. @mathijs might be able to answer that.
The window increase is only here to create more windows (thus more data) so the NN have more info to be trained on.
Here is small sketch I did some month ago to explain the role of the window increase some time ago. Maybe it can help you to understand.
hi @louis
the picture you provide is very easy to understand. thank you for always answering my question, really appreciated it.
one last question, I’ve got a little bit confused with the input layer for NN. for example, I am using the spectrogram extract feature, and the input layer in NN has 6500 features. how to calculate so we can get 6500 features?
here is the setting:
Frame length = 0.01
frame stride = 0.01
freq bands = 128
SR = 16khz
what is the math behind it?
Also if you want to have a look at the code, these blocks are completely open-source: GitHub - edgeimpulse/processing-blocks: Signal processing blocks
Feel free to try your own custom dsp block starting from one of those examples if you are familiar with digital signal processing.
MFCC is just an MFE with a DCT step at the end. It makes the output a "cepstrum, " which is sometimes referred to as “a spectrum of a spectrum.” To some extent, you’re looking at the rate of change of frequency vs time, which correlates well with most voice sounds (ie, not usually constant tones).
However, in the era of deep learning, some consider MFE to perform as well as MFCC even for human voice. So I always recommend to try both.
For non-voice, MFE or spectrogram is definitely the way to go, as you’re likely to have pure tones that MFCC won’t pick up as well.
hi @AlexE and @louis
thanks for the answer. I have another question:
so basically MFE is mel-spectrogram, right?
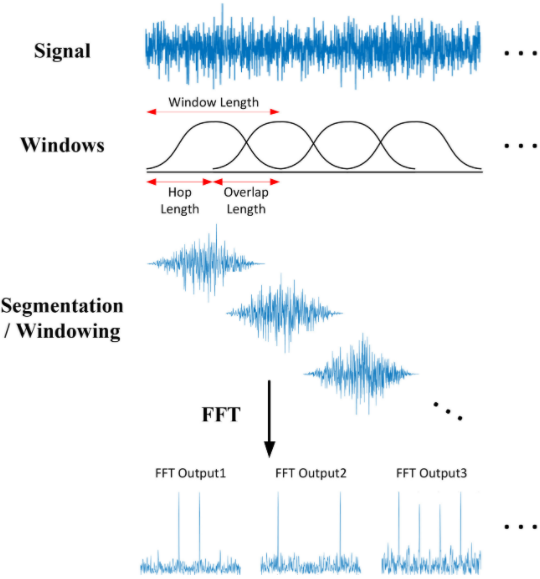
I am little bit confused, before I know edge-impulse studio, I have learn the basic audio spectrogram for example this one, in that article and other tutorial about audio spectogram is mention about hop length and overlap length, but in the documentation is mention Frame length, Frame stride, FFT size. is it Hop length = Frame length?frame stride = overlap length?
Sorry for the late reply, I’ve been on travel and PTO for a couple weeks!
1). Yes, MFE is just mel spectrogram. What this diagram calls Hop length, we actually call Frame stride. And you don’t explicitly set the overlap length, but it’s determined by the difference between frame stride and frame length. If frame length == frame stride, there’s no overlap. If frame stride < frame length, then overlap = length-stride. (and if >, then you’re jumping and leaving gaps)
2). Your diagram looks more or less correct!
Feel free to post here with more questions about the theory, settings, etc. I should be more responsive now that I’m back in office.
hi @AlexE,
thanks for your response and support that allow me to ask about the basics theory, since understanding the basics it’s really important before we make something or a project.
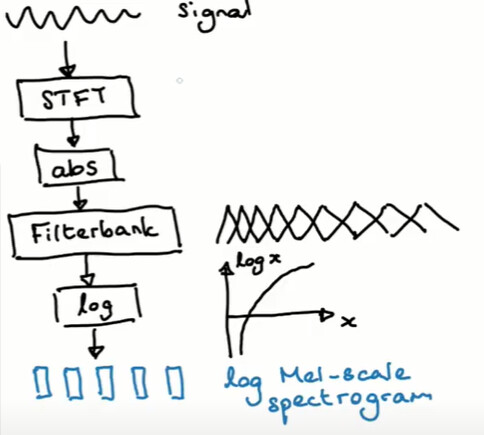
refer to my diagram before, one thing that I need to make sure of about windowing segmentation of the signal in the edge impulse studio, is whether it uses only FFT or using STFT(short-time Fourier transform)?
what is the frequency band/FFT size? in the documentation only said,
“Frequency bands: The FFT size”.
I’ve tried to google it, but all the answer is not satisfying.
tbh, I am a little bit confused in this part about FFT size, why are we must be divided by 2 plus 1?
STFT is just another name for breaking the signal into frames like we’re doing here. The underlying processing is still FFT based.
I’m going to update this document b/c this does sound a bit confusing. FFT size means just that…the size of the FFT applied to each frame. Choosing the FFT size (which should be close to the frame size) is just a trade of frequency resolution vs time resolution. I found this site which has some good example graphs at the bottom.
An FFT of a real signal (as in, not complex, in the imaginary number sense) gives redundant information in the so called “negative frequency” bins. So only the first half the FFT has non redundant information. The first bin of the 2nd half is kind of half in both worlds, so it’s usually included as well. Hence, fft_Size/2 + 1 features.