Hi all, Have played with EI audio classification model for water flow detection in a faucet. Used the base project as described by EI public project (Tutorial: Recognize sounds from audio - Dashboard - Edge Impulse). Augmented water flow data from various sources and recording from iPhone. Recorded noise and uploaded. Tried various different EI models Spectrogram, MFE, MFCC. Played with time series 2000ms, 1500ms, 1000ms etc. Achieved 95% and above accuracy on paper. Live classifications on EI website works well. But on testing in real-world, it doesn’t holdup. i.e. Model turns ON for loud noise. Example: vacuum cleaner, fan sounds and or loud noise. Attaching a YouTube video to illustrate this issue. Not sure what else I could do to minimize false positives. Any ideas are welcome. Thank you.
Edge Impulse Esp-Eye Audio Classify Testing to classify Water sounds:
Thank you @MMarcial. I have looked into this and tried several experiments. I have also heard from other experts that a customized solution i.e. python code based will provide more options in terms of preprocessing etc. I am not an expert in this and thought EI would provide me a baseline to start with. Will keep exploring options.
What sounds did you use to augment your dataset? If you don’t include sounds (like loud fans or vacuum cleaners), then it’s possible that the model simply trained to look for anything over a certain volume. Try including loud sounds in your training dataset, and if possible, try to record with the same microphone you are using for inference.
A custom Python solution won’t necessarily get you any further than what Edge Impulse can offer in a use case like this. I get the feeling that the low accuracy you’re seeing is a result of not enough data (or the right kind of data). However, if you do try something with custom Python code, we’d love to know if you can recommend any features that you think we’re missing!
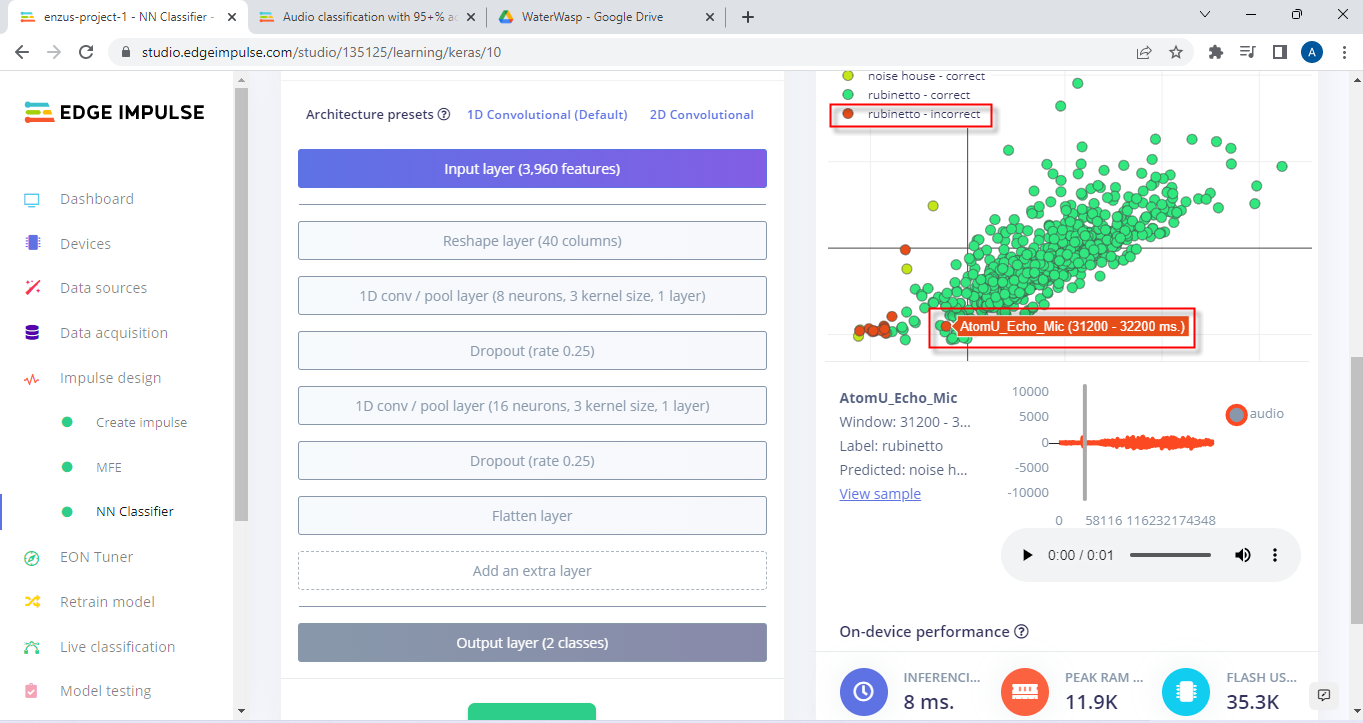
Hi thanks @shawn_edgeimpulse for your response. we went ahead and added 3 more hours of audio data and achieved almost 99% accuracy using MFCC on paper. But in real world testing, we always get positive flags for loud voice, vacuum and fans. Now, we wanted to try the MFE model instead to see if it would work any better, but getting some limitations on Edge Impulse, not sure what we are doing wrong? We put a message out on the forum but no pointers yet. Too much audio input data?. Thanks.
MFE is usually better for non-vocal data, so I imagine it will work better for your water vs. noise use case.
How did you collect the data? Was it using the ESP-EYE microphone or was it from another recording device?
When you mentioned that it works with “Live Inference,” was that using a connected ESP-EYE or using a different recording device (e.g. smartphone)?
If you’re using different microphones for data collection and inference, you might need to verify that the inference microphone is collecting acceptable sound data (i.e. do the samples sound the same when collected from the different microphones).
Thanks, we will try it. I think currently it is a combination of recording sources. i.e. iPhone voice recorder, wav files from public sites on the internet and from the device itself. Maybe it needs more homogenous wav file feeds from the actual device.
Hi @shawn_edgeimpulse, We are making some progress to record waves directly from the device storing directly to a SD card to be uploaded later to Edge Impulse to run a model. Below you will find couple of sound bites recorded using m5 stack echo board (since Esp-Eye board does not have pins to record to an external SD card). Our question now is, that the waves recorded are of a low volume (or grade). Should it needs to be amplified in your experience? Or it is the way it is since the device will listen it in this fashion therefore no amplification is needed? We are conflicted on this question. In one of the test project [Login - Edge Impulse] we tried to upload the waves from the device and run the model, but this wave was categorized as noise. Maybe because all the other wave files were recorded differently and this new wave was therefore treated as a noise.
Any pointers is appreciated very much. Thanks.
In my experience, amplification does make a difference. The FFT used in the MFCCs or MFEs calculations does not normalize amplitude. So, you have a few options:
Collect training samples that cover a wide variety of volumes
Try to ensure that the volumes your device will hear in deployment are the same as those used in training
Create an auto-gain or normalization system that attempts to normalize every sample received for training, testing, and during deployment
Great suggestions. Edge Impulse is an amazing tool to quickly test concepts and deploy for non-ML folks. We want to try the suggestions but unfortunately, the Arduino IDE libraries generated on Edge Impulse is no longer working. Unsure if there is still support for it? This used to work before effortlessly until couple of weeks ago. Others are also reporting similar issue -