@shawn_edgeimpulse
Hi. I’ve been trying to implement my funny ‘curse moneybox’ idea for some time now. I followed your guide on Coursera.com in detail. Unfortunately, I still can’t jump over the ‘buffer overrun’ problem related to microphone operation. The stm32f407 board should be more efficient than the Nucleo used on your GitHub.
The main problem is the complete lack of examples on the web using PDM2PCM, as the MEMS microphone embedded in the board takes data in PDM format. (PLEASE DONT LINK DOCUMENTATION)
I know that the microphone takes data however it is unformatted. (my attempts)
hal_res = HAL_I2S_Receive_DMA(&hi2s2, &pdmRxBuf, (I2S_BUF_LEN / ELEMENTS_PER_WORD));
PDM_Filter(&pdmRxBuf, i2s_buf, &PDM1_filter_handler);
https://drive.google.com/file/d/1t3YE93T0P7wOTxyVYIpilq2Zde3uqAbw/view?usp=sharing (includes an export from Edge Impulse containing two Polish words meaning ‘stop&run’, which were detected correctly on the smartphone)
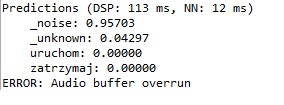
*The program uses the SWV console to display ‘printf’ through the board constraints. Because, an external UART module does not fix the problem (as does changing the slices, and other suggestions in your manual…).
Hi @handicap,
I have not implemented a PDM driver on an STM32 board (only I2S), so I don’t know how helpful I’ll be.
The run_classifier_continuous() mode can be difficult to debug. I recommend doing a few things before jumping to continuous mode:
- Create a simple application that records audio for 1 second (i.e. of you saying one of the keywords) then prints it all to a serial terminal. Turn those values into a CSV, upload it to Edge Impulse, and classify it as a test sample to see if it matches your expectation.
- Create a simple application that performs inference on a static buffer using just run_classifier(). For example, you might copy in the raw audio sample that you captured in 1. to see if it classifies correctly on your STM32 (the inference results should match the inference results in Edge Impulse Studio).
- Do a simple, looping (but non-continuous) inference programming where you record for 1 second, pass that raw sample to run_classifier(), print the results, and repeat.
- Write some code that times how long it takes to capture audio and perform inference. Use that to determine how many slices you can get done within a second.
- Update your continuous example with what you learned from 1-4. Is your audio buffer big enough? Can you meet your timing requirements to get 3 or 4 slices of audio processed in each second?
Thank you very much Mr. Shawn, I will follow your directions and report back if possible.
I would also like to ask some questions about buffers and implementation on Nucleo.
#define I2S_BUF_LEN 6400 // 8x desired size to downsample and throw out 1 ch
#define I2S_BUF_SKIP 8 // (2x L/R ch) * (2x sample rate).
#define ELEMENTS_PER_WORD 2 // Number of buffer elements per 32-bit word
How were the I2S buffers calculated? They are in different variants on github.
And what is their relation to the implementation of continuous-audio-sampling
static void audio_buffer_inference_callback(uint32_t n_samples, uint32_t offset)
{
// Copy samples from I2S buffer to inference buffer. Convert 24-bit, 32kHz
// samples to 16-bit, 16kHz
for (uint32_t i = 0; i < (n_samples / I2S_BUF_SKIP); i++) {
inference.buffers[inference.buf_select][inference.buf_count++] =
(int16_t)(i2s_buf[offset + (I2S_BUF_SKIP * i)])
if (inference.buf_count >= inference.n_samples) {
inference.buf_select ^= 1;
inference.buf_count = 0;
inference.buf_ready = 1;
}
}
}