I have some errors with my projectct.
Currently I’m using Arduino Nano RP2040. I’ve read the possible issues regarding to this board.
Let me give you some examples of my errors.
1) Setting window size over 2000 MS will give me following error when I compile in Arduino IDE.
ERR: Failed to run DSP process (-1002)
ERR: Failed to run classifier (-5)
It seems like the code is ending here :
run_classifier_init();
if (microphone_inference_start(EI_CLASSIFIER_SLICE_SIZE) == false) {
ei_printf("ERR: Could not allocate audio buffer (size %d), this could be due to the window length of your model\r\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT);
return;
}
}
2) When I change the parameters in create impulse to 1000 ms and winow increase to 1000 ms (this has recently given me the best overall results) I get following warning:
ERR: Failed to record audio...
run_classifier returned: 0
Timing: DSP 862 ms, inference 132 ms, anomaly 0 ms
Predictions:
Araripemanakin: 0.25000
EasternBristle: 0.25000
Noise_birds: 0.25000
ThickbilledP: 0.25000
Error sample buffer overrun. Decrease the number of slices per model window EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW is currently set to 3
ERR: Failed to record audio...
Error sample buffer overrun. Decrease the number of slices per model window EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW is currently set to 3
ERR: Failed to record audio...
Error sample buffer overrun. Decrease the number of slices per model window EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW is currently set to 3
ERR: Failed to record audio...
run_classifier returned: 0
So it doesent matters how I change the parameters in create impulse, I always get this error message in output. Setting the slice_window to 1 will not run my code at all. Setting window slice from 2-4 will give med error messages buffer overrun depending on the number i provide. For exm if i type window_slice to 3, the error message in seen three times. Then i t reloads and the data is printing out. So the model is “working” but i want to erase all the errors. This is a project that needs to finish this week. I would appriciate help and workarounds.
I need some help to solve this issues and need also to know what the maximum buffer/data I can put in this model.
I you want to check the project id it is:
218036
217898
Can you try to run the non-continuous sketch example to see if it works?
I’d start by using:
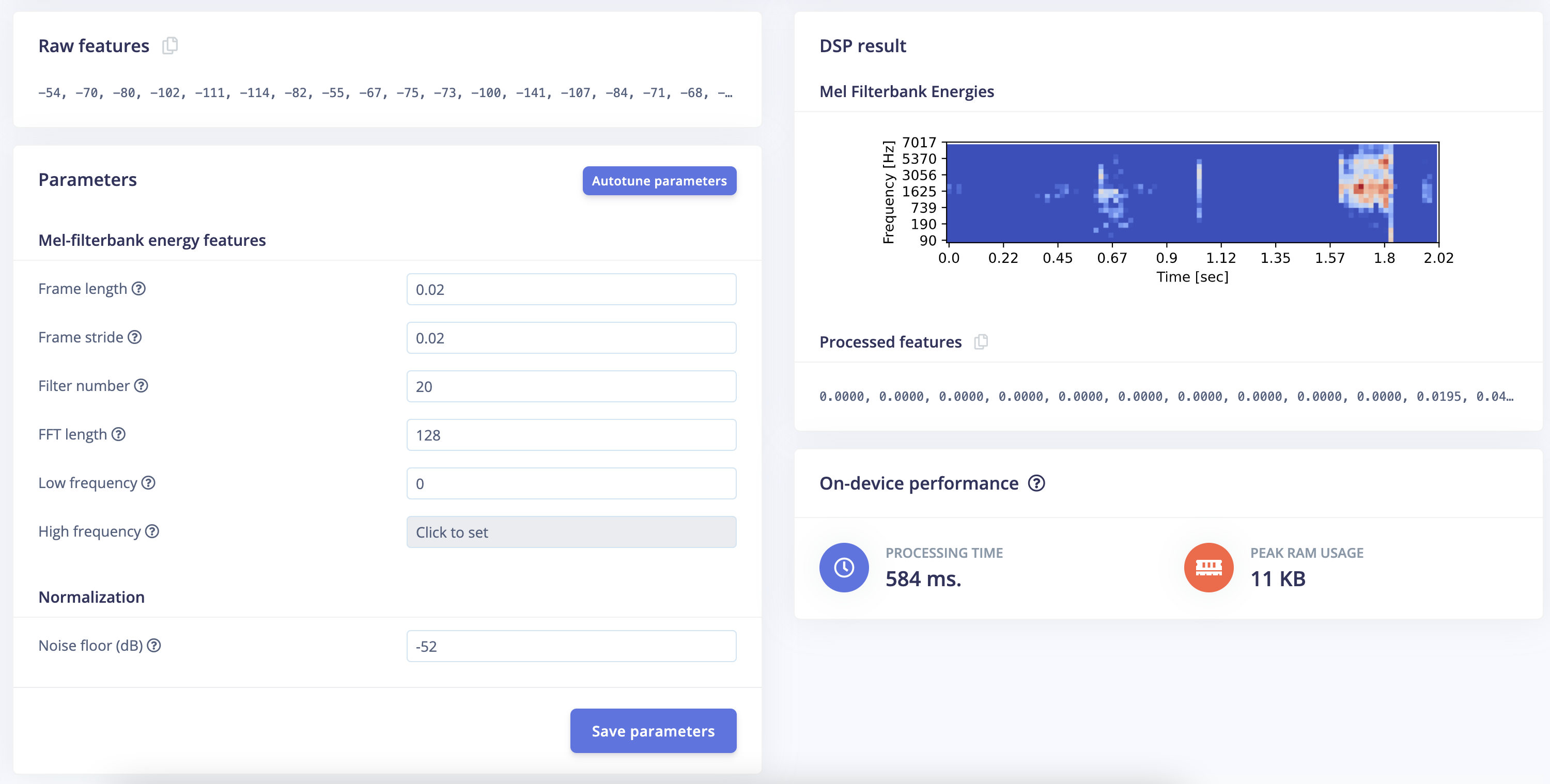
1000ms window size (window increase won’t change your model size so you can use something like 500 or 333ms).
Change your DSP parameters to use less resources. I would start with something like that, make sure it can run on the target and then modify it again to increase your accuracy:
Thank you! It seems that the buffer overrun disappears when i run the non-continuous model. Please explain for me the main differences between these two more than delaying? And I which situation it the continuous to prefer?
The parameters that you suggested gives me very bad predictions and unwanted correlations. This is due that some of the files has just noise for some seconds before the animal sound.
Therefore, using 2000 ms works a lot better.
When I used the performance calibrator and saved the config, all data in the output was always showing 0.00000 … I don’t know why because this should improve the overall results?
Thanks for using Edge Impulse! I took a look at your project and have some thoughts.
The samples in your dataset contain a mixture of silence/background noise and animal sounds. As you noted, this is why you are forced to use a longer window: you need to ensure that every window contains at least some of the animal sound that matches the label, otherwise a given window may contain only silence/background noise.
Performance calibration is designed to calibrate an event detection system. It works by filtering the output of the model over time to minimize the number of false accepts and false rejects over a long, labelled audio recording. This recording can either be generated synthetically (by layering your test dataset over background noise) or uploaded manually.
Because your original samples contain a lot of periods of silence/background noise, there are a lot of regions in the synthetically generated recording that are labelled as an animal noise but are in fact silence or background noise. If a sample begins or ends with a period of background noise, this will combine with the background noise of the synthetic sample to create a longer region of mislabelled audio that may be larger than your 2000ms window.
This “label noise” (mislabelled regions) results in a poorly calibrated post-processing algorithm that does not work effectively.
To resolve these issues, you might try:
Cleaning up your samples to reduce the duration of silence or background noise in each one. This will also allow you to reduce the length of your window, which will also increase the amount of unique inputs available during training and should result in a better performing model.
Creating and uploading a hand-labelled audio sample to performance calibration that does not include mislabelled regions of background noise: only the animal sounds themselves should be labelled. You can use a tool like Audacity to create a label file for an audio recording.
• why the split between training/test is divided like that in your project? And are you able to run this sketch in the continuous model on RP2040 or is it designed for another board?
• Why did you use the MFCC instead of MFE?
Thanks you for your response. Yeah, that’s correct that there is too much noise in the animal samples, therefore the unwanted correlations. The model works for now despite this, but good to know for future projects. I have used Audacity for some samples, but since I recorded with the built in microphone in my RP2040 at 16000 Hz, the audio was pretty much acceptable for the project.
Now into another current issue:
If you have a board connected to a project and you want to add a new board with a different serial connection ID, you should be able to connect it to Edge Impulse and choose wich project to run it , right?
I´ve tried every possible way but are unable to connect my second board to Edge Impulse.
This is the errors I receive (that i haven´t got before):
[SER] Connecting to COM3
[SER] Serial is connected, trying to read config…
[SER] Failed to get info off device Timeout when waiting for > (timeout: 5000) onConnected