Can some of the Edge Impulse superstars reply ( @janjongboom, @dansitu, @aurel and others … ). I really want to have a bigger than 96x96 pixel Vision model on the Portenta and I am not that interested in accuracy (presently just while I test the memory flexibility Arduino is working on). I would like to trim the layers and wondering which layers you think are most advantageous to reduce model size without killing the basic Machine Learning ability. (As I solved my base question… see further down, lets switch this to which model should I try and what reductions do you suggest.)
Here is an image of the present 96x96 compared to the Vision area (the box is 96x96 skewed a little by the 128x64 Grove OLED)
This is model manipulation area I want to get better at and to make a video about it for my students on my playlist, but I haven’t delved into it yet. Any suggestions for where to start?
A bit confused by the 3 vertical dots. not sure where to find them.
Wow the model is fairly easy. Think I answered my own question. Either reduce the density (16) of the main layer or pick another model.
…
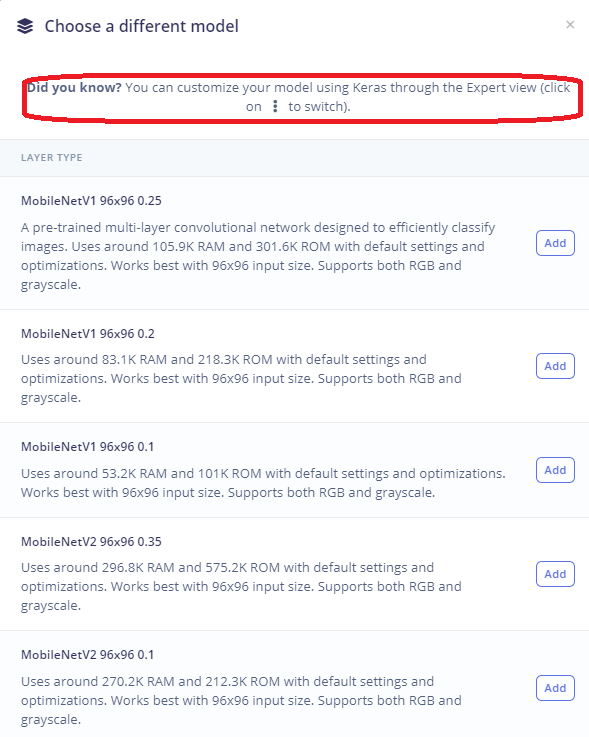
Probably should not post this as I kind of answered my own question, but maybe someone else is having the same issues. Still need suggestions for other models to try. I noticed a GRAYSCALE model which should probably help.
Which looks like it’s original size was 224x224, so I tried that and got a much bigger resolution 224x224 working on the Portenta.
The model is far less accurate, than the original 96x96 but from the image you can see the sensing resolution 224x224 is much larger than the original (skewed by the 128x64 pixel screen)
Hi @Rocksetta! You can actually use all of the transfer learning models with any input size—they are trained and tested on 96x96, but they’ll work with whatever input size you prefer. There may be some impact to accuracy, but often it’s relatively minor.
@dansitu
This code simply detects a microcontroller and the LED goes blue, it would be green seeing the stapler. The box is the 96x96 classification window, and the code does a “cutout”. See code below
/**
* This function is called by the classifier to get data
* We don't want to have a separate copy of the cutout here, so we'll read from the frame buffer dynamically
*/
int cutout_get_data(size_t offset, size_t length, float *out_ptr) {
// so offset and length naturally operate on the *cutout*, so we need to cut it out from the real framebuffer
size_t bytes_left = length;
size_t out_ptr_ix = 0;
// read byte for byte
while (bytes_left != 0) {
// find location of the byte in the cutout
size_t cutout_row = floor(offset / CUTOUT_COLS);
size_t cutout_col = offset - (cutout_row * CUTOUT_COLS);
// then read the value from the real frame buffer
size_t frame_buffer_row = cutout_row + cutout_row_start;
size_t frame_buffer_col = cutout_col + cutout_col_start;
// grab the value and convert to r/g/b
uint8_t pixel = frame_buffer[(frame_buffer_row * FRAME_BUFFER_COLS) + frame_buffer_col];
//uint8_t pixel = (pixelTemp>>8) | (pixelTemp<<8);
//uint8_t pixel = 255-pixelTemp;
uint8_t r = pixel;
uint8_t g = pixel;
uint8_t b = pixel;
// then convert to out_ptr format
float pixel_f = (r << 16) + (g << 8) + b;
out_ptr[out_ptr_ix] = pixel_f;
// and go to the next pixel
out_ptr_ix++;
offset++;
bytes_left--;
}
// and done!
return 0;
}
I know that fancier code can do a “squish” instead of a “cutout” that is what Edge Impulse does when it firsts defines your model. Does anyone know how to do that for Arduino? I hope to have the 320x320 camera activated soon. See Github here With the extra memory size of the Portenta but not an increased heap, I think the 96x96 classification will be fine as long as we use more of the Camera frameBuffer and a Squish might help with that.
Yes, instead of cropping in cutout you can take a look at resizeImage() in nano_ble33_sense_camera.ino from our Arduino library export. Note that you can use a single buffer for the input and output buffer.
You can also take a look out our crop_and_interpolate_rgb888() in edge-impulse-sdk/dsp/image/processing.cpp.
The difference between two is the former is our deprecated and ad-hoc function while the latter will consolidate all our image processing functions.
Thanks so much Raul @rjames. I will look at those. I just tested the Portenta in 320x320 camera view and it crashes even at M7 100:0 M4 so it must use the same heap that the ML model is using. I will put an Issue on Arduino to see if they have any suggestions.
.
Here is the issue I filed
If anyone can add information or star it as important that might help.
@rjames Good luck with all the technical stuff, it is out of my league, I just simplify what already works. If I can help in anyway please let me know. (Please let me test what your working on when it is public)
So I got working:
The Portenta 320x240 camera setting using any Portenta memory split (I used M7 50:50 M4) and the standard 96x96 Edge Impulse model using the cutout technique with the Grayscale 128x128 1.5 inch OLED (Waveshare or Adafruit, I strongly suggest getting this, it is surprisingly fast). My latest sketch shows on screen when a classification match is recorded and counts how many were witnessed.
What I would like to get working and will need to wait for your version Raul is:
Portenta 320x320 camera
M7 75:25 M4 memory split (or 50:50 if possible)
1.5 inch 128x128 GrayScale OLED
The newer Edge Impulse resize_image not cutout code
Largest resolution Edge Impulse model possible but fine with 96x96 if that is the best we can do.
Good luck with all the … " you could have a huge heap by just using Portenta_SDRAM library and replacing the calls to malloc and free with ea_malloc and ea_free ." message from Martino!
If you need me to test code just message @Rocksetta or put it in this thread.
In light of the new information on the other threads (and on GitHub) have you tried placing the framebuffer on the SDRAM to be able to run larger models? Something like this…
So this is very exciting, using a slightly changed @rjames code above I did get SDRAM working for the Portenta Camera using 320x320 Grayscale, with the 96x96 Edge Impulse model and the 128x128 Grayscale OLED here. Thanks so much Raul for the alignment code snipet, I did not find anything even remotely like it on the web.
The speed that you can move the camera and get detections is amazing for a microcontroller.
I looked into putting the edgeImpulse model into SDRAM but I could not find a main buffer to store. I also looked at TensorflowLight which has much simpler code
but could not figure out how to put the unsigned char array into SDRAM.
Anyway, so far this is all really good news, I just have to figure out how to go from CUTOUT using only the 96x96 pixels to RESIZEIMAGE squishing the full 320x320 images down to 96x96 and I am a bit stuck here. Not sure if I can just replace the cutout function with the resize image function. May need a bit of help with this part.
Somehow I logged in differently this is still @rocksetta.
This seems very wrong. @louis, I am struggling with how to get the out_ptr into the features_signal structure. This is what I have tried so far, seems very wasteful of memory. It does compile but flashes red on loading to the Portenta.
int myCamResult = myCam.grab(sdram_frame_buffer); // myCamResult should be zero
// the features are stored into flash, and we don't want to load everything into RAM
signal_t features_signal;
features_signal.total_length = CUTOUT_COLS * CUTOUT_ROWS;
float model_input_buffer[features_signal.total_length];
//features_signal.get_data = &cutout_get_data; // this activated the old code
// somehow activate resize???
// void image_resize_linear(uint8_t *dst_image, uint8_t *src_image, int dst_w, int dst_h, int dst_c, int src_w, int src_h)
uint8_t * tmp_buffer = (uint8_t *) malloc(features_signal.total_length);
image_resize_linear( tmp_buffer, sdram_frame_buffer, 96,96, 1 /* 1 = GRAYSCALE */, 320,320 );
// convert int_8 to float
for (int i=0; i < features_signal.total_length; i++){
model_input_buffer[i] = tmp_buffer[i] / 255.0f;
}
features_signal.get_data((unsigned int)sizeof(uint8_t), (unsigned int)features_signal.total_length, model_input_buffer);
free(tmp_buffer);
I just checked how I did the project using the ESP32 Cam to see if there was any differences, in fact, the way I did allocated the pointer using Espressif SDK was using this function dl_matrix3du_alloc …
This will be different with the Portenta.
/**
* @brief Resize the image in RGB888 format via bilinear interpolation
*
* @param dst_image The output image
* @param src_image Source image
* @param dst_w Width of the output image
* @param dst_h Height of the output image
* @param dst_c Channel of the output image
* @param src_w Width of the source image
* @param src_h Height of the source image
*/
void image_resize_linear(uint8_t *dst_image, uint8_t *src_image, int dst_w, int dst_h, int dst_c, int src_w, int src_h);
It has to be in RGB888 format to use this function… I might have misread your initial question.
If needed, here is an arduino sketch I wrote to show how it works with the ESP32 Cam + Edge Impulse
Your amazing @rjames, thanks so much for the code examples. This is the first time I have ever had the Arduino Portenta using all 320x320 camera pixels resized to a 96x96 Edge Impulse model, using the SDRAM of the Portenta for the camera buffer.
Raul @rjames, any hints about testing multi-object “bounding boxes object detection” instead of what we have working for single object “one label per data” ?
I know from my work with WASM that the differences between the two types of code are very small. I am wondering if this line still grabs the result correctly
EI_IMPULSE_ERROR res = run_classifier(&signal, &result, false /* debug */);
Also
the result structure has changed for multi-object, but I can’t find any information about the new structure other than the header file ei_classifier_types.h. I think from my WASM the calls look something like this.
Any confirmation here. Not expecting bounding boxes to work well, just wondering if it works at all on the Portenta. It was very slow on the web browser.






 320x320 Portenta Camera classifying 96x96 edge impulse model showing on a 128x128 Grayscale OLED, using M7:M4 50:50
320x320 Portenta Camera classifying 96x96 edge impulse model showing on a 128x128 Grayscale OLED, using M7:M4 50:50
 thanks so much for the code examples. This is the first time I have ever had the Arduino Portenta using all 320x320 camera pixels resized to a 96x96 Edge Impulse model, using the SDRAM of the Portenta for the camera buffer.
thanks so much for the code examples. This is the first time I have ever had the Arduino Portenta using all 320x320 camera pixels resized to a 96x96 Edge Impulse model, using the SDRAM of the Portenta for the camera buffer.