@janjongboom sir, I am also having the same issue.
Can you please help me too?
My project ID is 53685
@janjongboom sir, I am also having the same issue.
Can you please help me too?
My project ID is 53685
Hi @HShroff
Quick fix (while we fix this for real):
This will have all the smaller split-up files already (rather than trying to crop the large audio files in the DSP process).
Thanks sir. It is working well now!
Hello there, (It’s my first post on the platform)
I wished to know if there was a way to actually run the process using the local machine’s resources. It’s because I was facing a similar isssue, and that was when my dataset still needed to be enlarged by like 200%. So, if I could somehow gain access to the code which I could just run locally in , say PyCharm, that would be great, since I also do not want to overburden your servers’ resources.
Thanks!
And sir, unlike as you mentioned earlier, the features are NOT generated in my case at all, so unfortunately I cannot train the4 model as of now. Is this a bug?
Hi, I’m having the same issue ( [Application exited with code 137) when I train the network for 20 epochs. It works for 15 epochs though. Please, could you help me out?
Hello @okosa20d ,
It seems that your training was successful with 20 epochs (on your project ID 79163).
I also increased a bit your training jobs performances. Let me know if you still have some issues.
Regards,
Louis
Hi, I’m happy that I’m using such a great tool for tinyML. I’m really enjoying it. I did some scratch project with about 163 images first with bounding box annotation and I can see the model output and its classification result. The project ID is 87553 which is working fine, from workflow perspective.
Later I experimented with about 438 images with transfer learning. Initially i went with 100 epoch and I got this code 137 error. Then I thought it was running out of 20 minutes allocated time. I later reduced upto 25 epoch, then I’m facing the same error. The project ID is 88632.
Now, I see that the transfer learning is still attached to some job since yesterday. It would be a great help to know whether I’m running out of resources or what I’m doing wrong?
Thank you in advance!
Hello @asma ,
I increased your compute resources and the compute time limit of your project.
Indeed, by default, we use 4GB-ram containers to run the training jobs which was probably too small for your project.
However, the job that is still attached seems odd. Can you try to cancel the job and run it again. It will take into account your new performance settings.
Regards,
Louis
Thank you for the support @louis and for increasing the compute resource. I’m able to train it with 100 epoch now.
Hi,
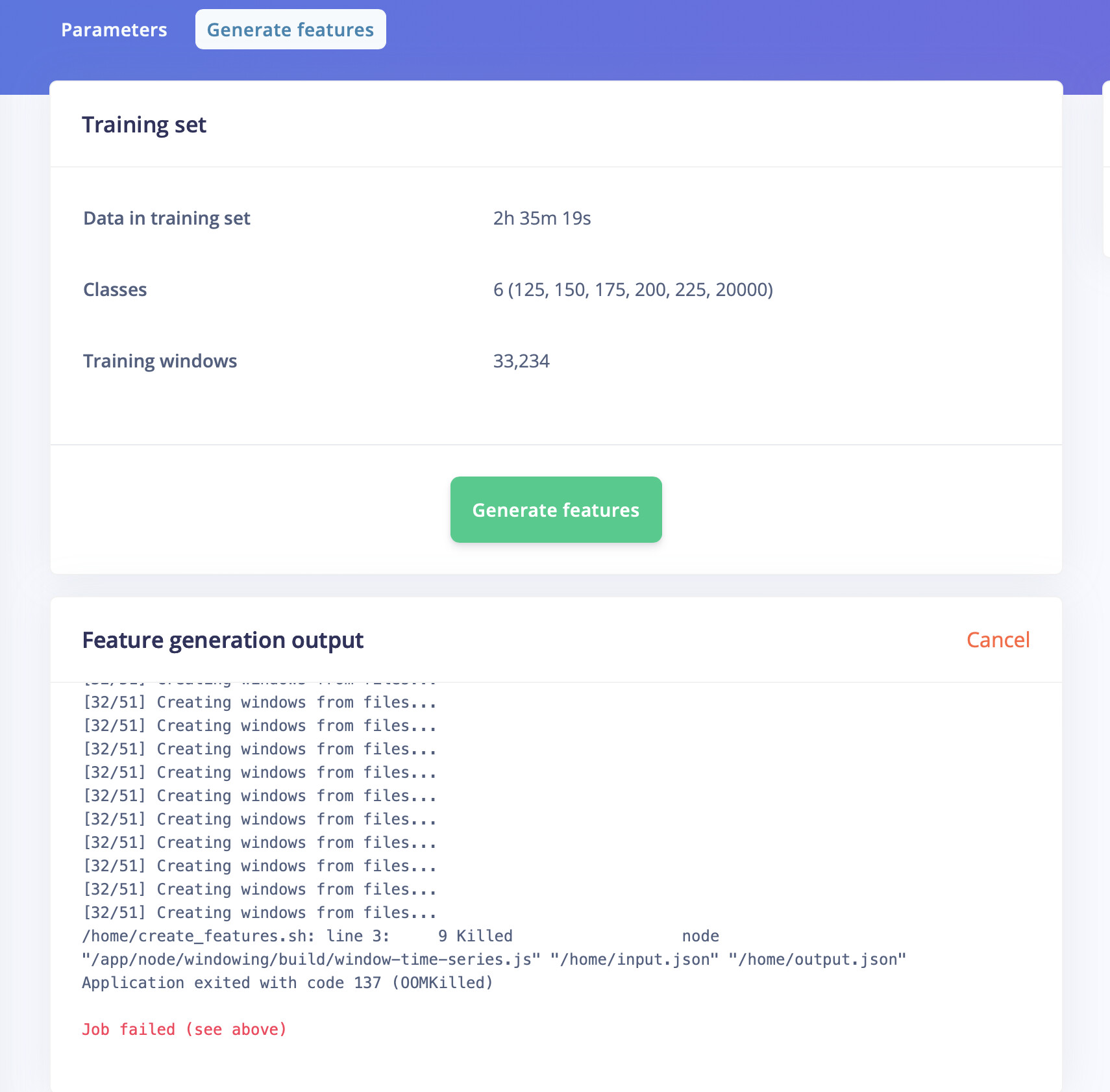
I have the same issue (project ID 38986). I’m training on 2,35 hours of audio data. I did a lot of adaptation of the window lengths to try and make it run in various ways. Is there any solution to this yet? 
Hi Louis,
Thanks a lot!! I tried a couple of times now, also logging out and back in - I keep getting the same error  Any suggestions what I am doing wrong here?
Any suggestions what I am doing wrong here?
Hello @mette.lvl ,
It seems that your MFCC page takes ages to compute even one window size. I am not sure about the reason.
Could you try to delete all the blocks in your Impulse (in Create Impulse tab, remove them all and add them again). Alternatively, exporting all the data in your project and import them again on a new project could eventually work too (I’d need increase the performances on your second project so if you do that, please give me your project ID).
Let me know if the trick worked.
Regards,
Louis
Still no luck, Louis.
I tried deleting the entire impulse and building it up in various ways.
I also exported all of my code into a zip, which my MacBook is unable to unzip. And I cannot find any easy way to upload my existing dataset into a new project. It was quite a pain to upload the data in batches for each label originally. I’m on the edge of giving up on EdgeImpulse 
It seems that it is always sample #32 that fails - perhaps you can tell me which one that is and I can try and delete it from the dataset?
Hi there,
I seem to be getting the same error but when I’m training the model.
Hi @newmanreece - we’ve upped the memory limits for all jobs to be less stringent (they can go over memory limits without being killed immediately) and this should resolve all OOMKilled issues. We’re monitoring actively to see if any others happen and can tweak the limits if that’s the case.
Same issue. Project Id : 122758