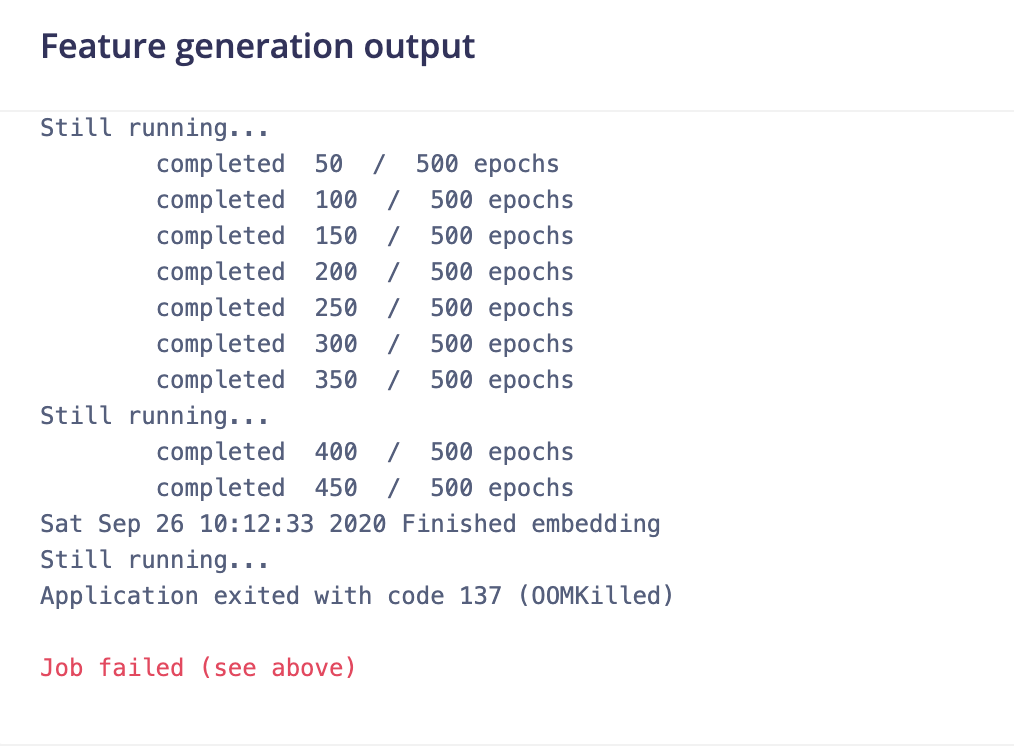
Hi @janjongboom! Was trying to generate some features from 3 classes and was greeted with the above message. There are approximately 2600 images in the training set. Any idea what I could be doing wrong?
Hi @zulyang, looks like it’s running out of memory there… Those jobs already have 4GB of RAM so we’ll see if we can take a smaller slice of the raw data to generate the visualizations (we currently take 2,000 of them, which apparently is a bit overkill on RGB images). Will put out a fix in the coming week.
The features were generated though, so you should be able to train a network (I just did it in your project).
Thank you so much, @janjongboom! 
Any chance we’ll see a tutorial for loading an edge impulse model on a browser ?
 Awesome…worked like a charm
Awesome…worked like a charm
I have the same problem, My data set also has 2500+ images. how can I fix this?
Hi @dilanperera,
I just increased your performances on your project.
Note that on the Object Detection model, we still have a memory leak issue. An internal ticket has been created but I don’t have an ETA at the time.
You can also try to reduce your dataset if you still have the error even with the augmented performances.
Regards,
Louis
I reached this post as I’m facing the same problem after applying augmentation to my dataset as discussed here.
Can you please increase my project limits (project id:44851) to solve this issue.
Hello @yahyatawil,
I see that your dataset contains 9185 objects.
To avoid this error (even if with augmented performances), can you try to make it fit within 2200 objects while we are trying to fix the tensorflow memory leak in Object Detection learning block?
Regards,
Louis
In the previous version it was 3K objects and now after I applied the augmentation manually it increased to 3x times because of applying 2 types of augmentation to the same original dataset.
So if we do this calculation:
Number of objects in your dataset: 9185
Math.ceil(9185 / 32);
> 288 (number of batches)
288 * 200;
> 57600 (MB of RAM needed)
Here we would need to trigger a job on a pod that has more than 57GB of RAM and we don’t have instances that powerful.
Object Detection is indeed very greedy in terms of resources consumption and we are trying to optimize this but it is still in a work-in-progress stage.
Oh, this it is too much of memory!
Could you support kindly with any workarround or boosting my project resources and re-train internally and then switch back to current one? . This is my last experiment for this dataset before sharing the results in our smart wheelchair paper next Wed 
Hello @yahyatawil,
Unfortunately, I have no solution to retrain the model with your number of samples at the moment.
I would start by removing your data samples which have the smallest bounding boxes as our Object Detection model is not great at detecting small objects in a frame.
And secondly I would remove the images which have too much objects in the frame. This would both reduce your dataset size and secondly help increasing the accuracy.
Then I would remove some pictures where you have the most occurence. I see that the trunk and traffic_sign classes are much more represented than the others.
Regards,
Louis
2 Likes
As some background: we use our own training libraries for everything (based on Keras) except for object detection which is based on a training library from Google. The memory leak is somewhere in that code (see https://github.com/tensorflow/models/issues/9981) but no luck in getting it fixed. We’re working (in parallel) on our own object detection training library, which will support a wider variety of models, input sizes, and targets, and then we have full control over when and where we leak memory
@janjongboom sir, I am also having the same issue.
Can you please help me too?
My project ID is 53685
Hi @HShroff
Quick fix (while we fix this for real):
- Go to Dashboard > Export, and export with ‘Retain crops and splits’ enabled.
- Create new project, and upload the exported files to the project.
- Done.
This will have all the smaller split-up files already (rather than trying to crop the large audio files in the DSP process).
Thanks sir. It is working well now!
1 Like
Hello there, (It’s my first post on the platform)
I wished to know if there was a way to actually run the process using the local machine’s resources. It’s because I was facing a similar isssue, and that was when my dataset still needed to be enlarged by like 200%. So, if I could somehow gain access to the code which I could just run locally in , say PyCharm, that would be great, since I also do not want to overburden your servers’ resources.
Thanks!