I have a project where I am detecting error states of a fan. Normal, zip tie in the fan, banging with a hammer at periodic intervals, and banging with a small screwdriver at periodic intervals to begin with.
I am running audio inference on a 1 second window at a time over a 10 second recording. The point of this is that new error states may present themselves temporally differently and the DSP should be suitable for that possibility. (some error states may be periodic bangs, others may be consistent change in pitch, etc.) Basically, I am trying to cast the net wide because I don’t know what errors will occur or how they will present themselves.
The idea is to have it automatically detect new possible error states and notify me so that I can retrain on various conditions (some potentially being new classifications), using the anomaly detection.
Since the window size is a little large, I have used the MFE DSP with default settings but a FFT length of 512 to pick up more discreet changes in the pitch or fast bangs over the second. This seems to work surprisingly well with the spectrogram and with the NN. The issue is with the anomaly detection.
The output is comprised of a few thousand “audio features”. When I select all features, the bubbles created exceed the size of the plotted points by a huge margin. I am only seeing the “cluster count” and “minimum score” settings, neither of which fix the issue. I have tried with different DSP settings to no avail. It is difficult to determine what the issues may even be here or how to address them, and I haven’t seen many forum posts or much documentation on this. Any info or suggestions would be much appreciated!
@Kerkenstuff, the anomaly detection block does not work well with high-dimensional data like the spectrograms. My suggestion would be to train a classifier if you already have ‘normal’ vs. ‘fault state’ features.
I have some for my test case, and the classifier works well. But the real value to the application is to detect unclassified anomalies. The system will run autonomously and far from people, so it is important to be able to notice issues without human intervention and signal me remotely. For example, if a leaf were to get caught in the fan, the NN would just classify it randomly and not notice that it is a new state.
Has anyone considered, an autoencoder for anomaly detection on high-dimensional data?
Unless you are meaning to create a NN that is trained between “normal” and “general not normal” states. Which might actually work with a large enough dataset if there is enough variance in normal and non normal states to generalize? I have never heard of that method. But would that be great if it could work as a general method of anomaly detection
@Kerkenstuff Check. Audio anomaly detection is really hard. We’ve had someone work on autoencoders for audio over the summer and the results were not great unfortunately.
@dansitu could you lend some advice on how to approach this best?
As @janjongboom mentions, this is a tricky problem! Using Edge Impulse, I would recommend trying the following approach:
Use your existing DSP and NN configuration to distinguish between normal operation and known error states that you can collect training data for.
Add another DSP block that extracts some simple high-level features. For example, you could use our “Spectral features” block. I was able to get decent results for audio by setting the filter type to “none”.
Set this new DSP block as the input to the “Anomaly detection” block, but make sure your NN block only has the original DSP as its input.
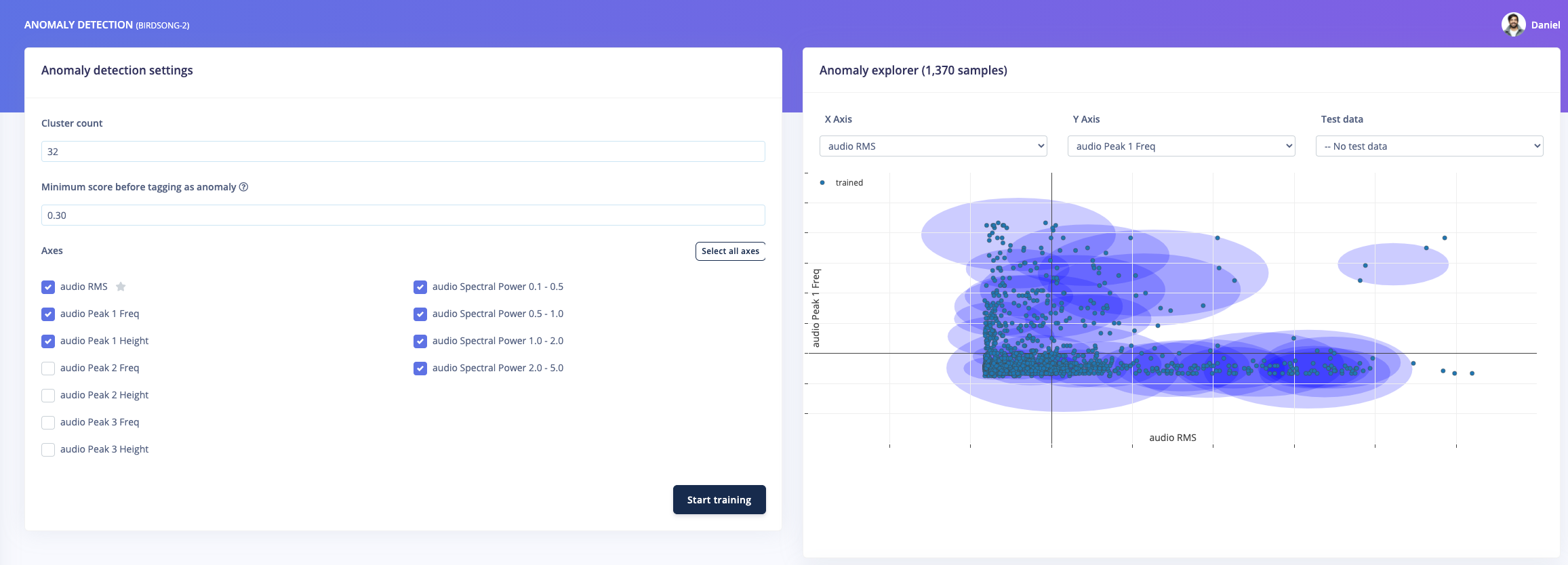
Play with the configuration of the DSP block until you find a combination that gives reasonable clusters. For example, here’s a screenshot of the results from one of my own projects that appears promising:
This should help detect some out-of-distribution anomalies, so perhaps in conjunction with your classifier detecting “known” anomaly types it will get good enough performance for your application.
I tried the K-means approach, but for my purpose it seemed the resolution was too low to pick up much after testing. I may go back later to test it further, but for now I focused on the NN approach.
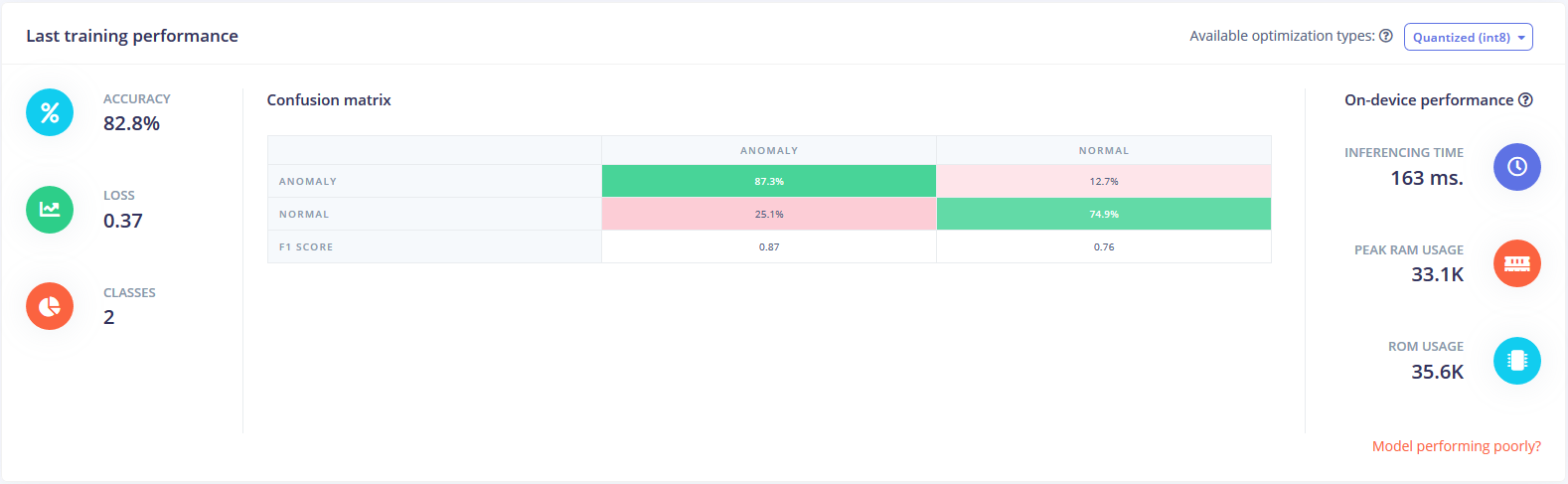
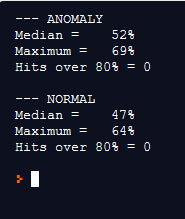
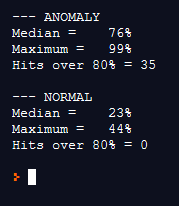
The NN was trained using about 10 minutes of “normal” and 10 minutes of “anom” data. The model testing shows a pretty low accuracy at 63%, but a closer look at the classification shows that the prediction difference is pretty accurate at detecting error states. Interestingly, when tested with normal data, the NN predictions are almost exactly 50/50 on average. Since this is for general anomaly scoring over longer periods of time (over all 90 windows of a 10 second recordings every hour, in my case), the data from this approach could be used to track changes in the recording sounds over time by post-processing the NN output data.
If / when I try the K-means method in more depth, I will post here.
@Kerkenstuff, you have lots of uncertain which means the sample did not go over the minimum confidence threshold. Could you set the ‘minimum confidence rating’ in your NN to 0.5 and try again? I think it’ll be a good jump up.
@aurel@jenny Could you take a look at the project and see whether there’s an easy way to improve? Maybe raw spectrogram over MFE?
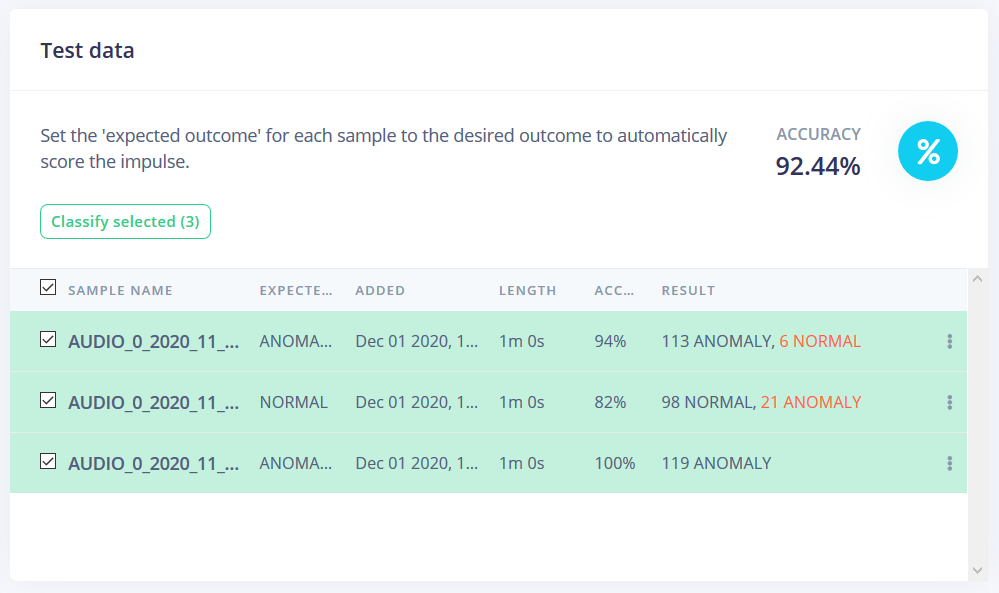
New test at 0.50. I guess the accuracy of “normal” was higher than I eyeballed. Overall it did a surprisingly great job! I will be testing this with various other recordings to see how the model works on various new recordings soon.
Using the spectrogram block with a 1D CNN would give you a much better accuracy (> 90%). I would also suggest increasing the window to 2 sec with an increase of 1 sec as you may not even need to average over multiple windows during inferencing.
For the spectrogram block, you can also double the frame values (0.04 and 0.02 respectively) to decrease inferencing time, this should not affect much accuracy for your use case.
Would decreasing the size of the NN not reduce its abilities in detecting errors? The environment of the audio will have periodic banging and other background noises. So what falls within the “normal” range would be quite a few different but specific frequency patterns. Thats is why I decided to stick with the 2D, but I am not well versed in this.
I want it to be sensitive enough to detect relatively minor new sounds. New squeaks, bumping, etc. that may be relatively low in magnitude and happen consistently (between 1 - 10+ times / second) over various recordings. It may also be consistent noise. So would increasing the window size reduce my ability to detect lower magnitude noises by “diluting” it?
The ultimate goal is to track the percentage confidence that it is within normal range over many recordings at 1/hour over multiple days. Since the recordings are only 10 seconds with an hour in between, the inferencing time isnt much of a factor for me here.
@Kerkenstuff, this is the hard part of ML at the moment, there’s not one right answer and still a bit of trial and error in getting the right parameters [1]. I think that @aurel looked at your dataset and got the 90% accuracy number from a quick experiment with the spectrogram block though. If you have a lot of processing power I’d play with decreasing the frame length / stride and increasing the number of filters in spectrogram block (resulting at a larger spectrogram), and then throwing the largest NN at it and use that as a baseline - then compare it to Aurelien’s suggestions. Note that biggest != always best though, with lots of parameters you also increase the chance of overfitting.
[1] We’re working on some tools to make this easier though!
That was more along the lines of what I was thinking. I will test a few different methods and see which ones work. The difficulty will be coming up with various anomalies to test with to be able to properly benchmark the different solutions, but I imagine it will be different for different use cases, so learning the different strategies would be advantageous.