Question/Issue:
I’m experimenting with Image Classification on the ESP32‑S3. However, only one specific project fails at startup with an error during AllocateTensors(). The error message suggests it’s running out of memory, but according to the Deployment tab, the RAM usage is about 251 KB, so it seems like there should be enough.
Does anyone know how to investigate this issue or how to fix it?
Logs:
Starting continious inference in 2 seconds...
AllocateTensors() failedERR: Failed to run classifier (-3)
AllocateTensors() failedERR: Failed to run classifier (-3)
AllocateTensors() failedERR: Failed to run classifier (-3)
AllocateTensors() failedERR: Failed to run classifier (-3)
AllocateTensors() failedERR: Failed to run classifier (-3)
AllocateTensors() failedERR: Failed to run classifier (-3)
AllocateTensors() failedERR: Failed to run classifier (-3)
AllocateTensors() failedERR: Failed to run classifier (-3)
AllocateTensors() failedERR: Failed to run classifier (-3)
Project ID:
1004578
Reproducibility:
[x] Always
[ ] Sometimes
[ ] Rarely
Environment:
Platform: Seeed Studio XIAO ESP32S3 Sense
Build Environment Details: Arduino IDE 2.3.8, ESP32 BSP 3.3.8
OS Version: Windows 11
Edge Impulse:
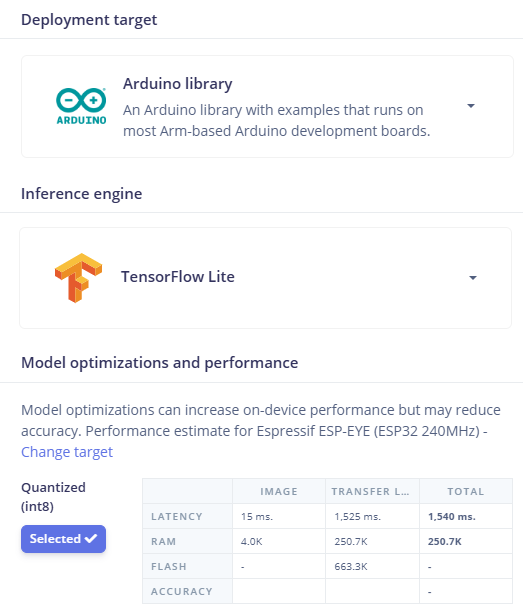
Impulse: Image data 96x96 - Image - Transfer Learning(Images)
Image: Grayscale
Transfer learning: Profile int8 model, MobileNetV2 96x96 0.35(8neurons, 0.1dropout)
Hi @matsujirushi - I have forwarded your post to our embedded team. They have created an issue and are debugging. We recently upgraded our version of TensorFlow and it may be related. Stay tuned.
Just following up on this issue. Is there any update from the embedded team on the AllocateTensors() failed / Failed to run classifier (-3) error?
I am facing the same issue with an example keyword-spotting model based on MobileNetV2 0.35 alpha. I am trying to understand whether the failure is related to tensor arena sizing, memory fragmentation, PSRAM allocation, or the recent TensorFlow Lite upgrade mentioned earlier in the thread.
I also tried deploying much smaller MLP models, changing the ESP32 BSP version, and enabling/forcing PSRAM allocation, but I still see the same error.
Are there any recommended workarounds or debugging steps at this point? For example, should I try pinning to an older Edge Impulse/TFLite runtime, manually increasing the tensor arena size, or reducing specific model/input parameters?
Hi @srijayjk - the Embedded team in still looking into a proper fix. In the meantime, they have provided these workaround steps:
Depending on your deployment type (EON Compiled or TFLM):
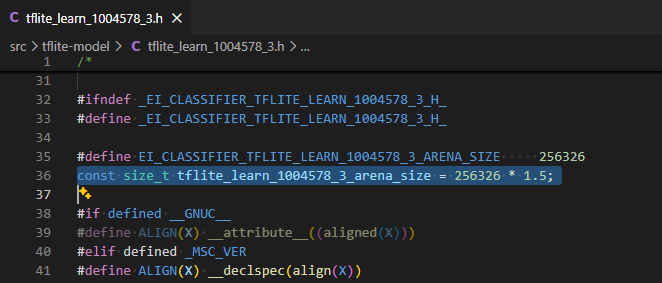
for the EON Compiler deployments, look for kTensorArenaSize in the tflite-model/tflite_learn_*_compiled.cpp and increase the size (depending on the memory available, you can start with doubling it)
For the TensorFlow deployments, look for tflite_learn_*_arena_size constant in the tflite-model/tflite_learn_*.h and increase this value.
Hi @brianmcfadden ,
I tried the workaround.
The failedERR no longer occurs, but the classification value doesn’t change, so it looks like the inference isn’t running correctly.
I’m looking forward to further updates.
I’m running a slightly modified version of the esp32/esp32_camera component included in the Deployment package.
To make it work on the XIAO ESP32S3 Sense, I’ve adjusted the camera interface definitions.
By the way, if I set EI_CLASSIFIER_TFLITE_ENABLE_ESP_NN to 0, inference runs without any issues (although it becomes noticeably slower).
Hi @matsujirushi !
Apologies for the delayed response from our team. Embedded team will test out your deployment with esp32/esp32_camera sketch before the end of the week. It would be more helpful if you can paste the complete sketch - in case you missed mentioning some changes.
@matsujirushi ,
I have some good news and bad news. The bad news is that it does seem we have regression in ESP NN optimized kernels specifically for MobileNet v2 model. We know it used to work before, but we do not have runtime testing for ESP32-S3 (only regular ESP32), so somewhere along the way it stopped producing correct results. Our embedded team has logged the issue and will work on eliminating it.
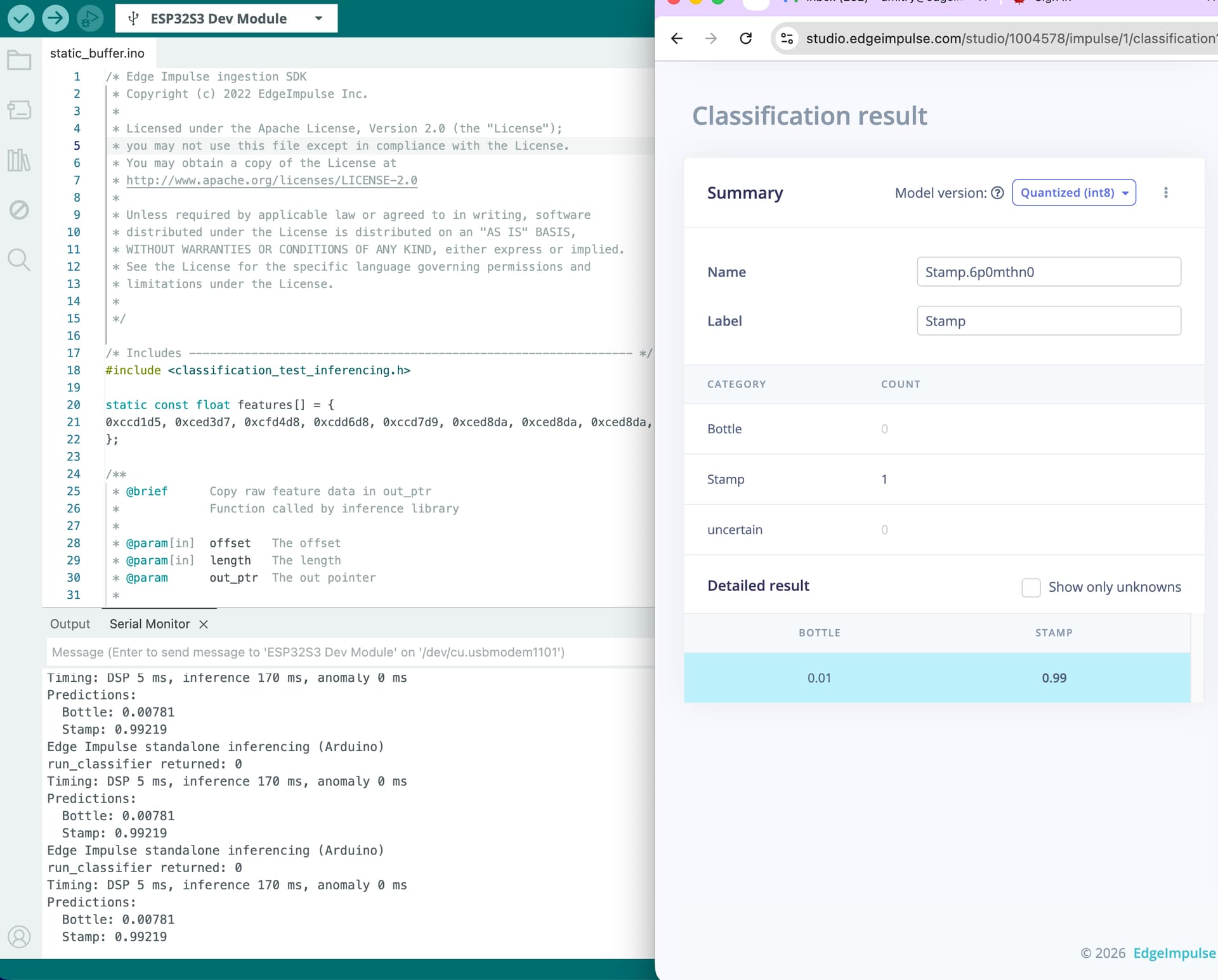
The good news however is that MobileNet v1 models are not affected - I trained one on your data and achieved the same accuracy, while running at almost half the latency! You can find it under Impulse #2 in your project - and you can try it on ESP32-S3 with static_buffer example, to make sure the inference is correct for a canned sample.
hi @AIWintermuteAI , I’m also experiencing the exact same issue / error logs as @matsujirushi as of now. Only difference is I’m using the Freenova ESP32S3-CAM and Arduino IDE 1.8.18. Other parameters are the same as @matsujirushi . May I know how should i resolve this issue?
hi @matsujirushi !
I tested with your project (Impulse 1, sample Stamp.6p0mthn0) - I am able to get correct inference results, that differ from your previous (incorrect outputs):
To achieve that I did have to increase the arena size - we have only resolved the incorrect classification results issues on ESP32-S3. The arena size issue is a bit trickier to fix, but we are working on it. Just increasing the arena size manually should be a suitable workaround for now.
@LTGoh hi!
Please, create a new topic. It is not helpful to tell us that "you are experiencing the exact same issue / error logs as @matsujirushi as of now. ", especially since we debugged not one, but two issues with matsujirushi