Feature Description: I am requesting a set of enhancements for the AI Label feature to improve stability and workflow efficiency when processing large datasets. Specifically, I need improvements in four areas: (1) Immediate UI reflection of metadata changes, (2) Error handling for malformed LLM responses, (3) Configurable concurrency for performance, and (4) Granular batch selection to manage job execution better.
Context/Use case: I am currently using the AI Label feature to process large sets of image data. My workflow involves running batch jobs where an LLM analyzes images and assigns labels/metadata.
Problem to be Solved: I am facing four distinct issues that hinder my progress:
-
UI Sync Lag: When I run a labeling job on a large dataset, I can see the metadata is successfully set in the background, but the visual label on the image does not update immediately. And if the job fail, the metadata got update, but label for those no
-
Job Fragility (JSON Parsing): Sometimes the LLM returns a bad format (e.g., unparsable JSON). Currently, this causes the specific AI Label job to break and terminate entirely. This is frustrating because one bad response shouldn’t stop the whole process.
-
Slow Sequential Processing: The jobs appear to run sequentially.
-
Limited Data Selection: Currently, I can only choose broad categories like “All data” or “Not labeled.” If a job with 1,000 items breaks at item 500, I have no way to easily resume from item 501. I am forced to re-evaluate the logic for the whole set or rely on the “Not labeled” filter, which isn’t always accurate for my needs.
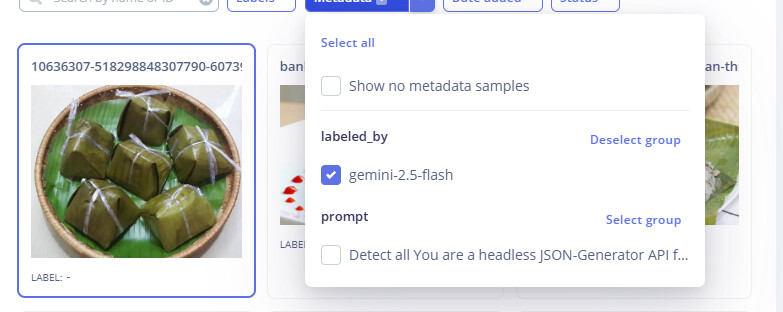
Proposed Solution: To solve these problems, I propose the following technical implementations:
- Real-time UI Updates: : Label data and metadata set at the same time
- “Ignore Errors” Option: A checkbox configuration in the job setup (e.g., “Ignore Parsing Errors”). If checked, the system should log the JSON error, or maybe 502/503 error, skip that specific item, and continue to the next one without crashing the job.
- Configurable Concurrency: An option to configure the number of parallel LLM calls (e.g., a “Concurrency Limit” input). This will allow me to run parallel calls on items to significantly improve performance.
- Batch/Range Selection: A better way to choose segments for labeling. Instead of just “All” or “Unlabeled,” please allow me to define a range or batch limit (e.g., “Run on items 1–200” or “Process next 500 items”).
Expected Benefits:
- Workflow Stability: Able to run long jobs overnight without worrying that a single bad LLM response will crash the entire process.
- Performance: Able to label datasets much faster by utilizing parallel processing.
- Control: Have the ability to test the prompt on small batches (e.g., first 10 items) before committing to a full run, saving me time and API costs.
Potential Impact: This will drastically improve efficiency in dataset preparation. It transforms the AI Labeling tool from a fragile feature into a robust production tool that I can rely on for high-volume data.
Related Issues or Requests: [List any related issues or feature requests]
Additional Information:
- I have attached a screenshot in the description showing the issue where metadata is set, but the label is not yet updated visually.