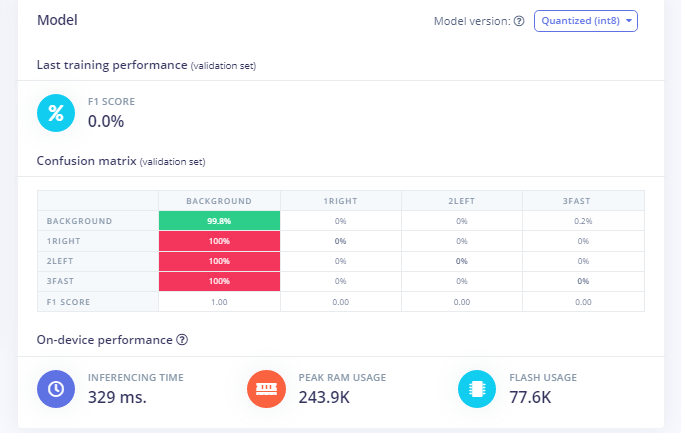
Thanks for the reply @matkelcey. I agree it seems difficult. I might try Daniels hack to load the weights in base64 format. I am also trying a TensorflowJS method.
For the training of 2 models approach I simply have to redirect the ouput of the FOMO model as a completely new input for a classification model. That isn’t as awful as it sounds, since the data would be very similar to the raw data that we get from the Pixy2Cam (#, x, y, width, height), which I have always wanted to get working with EdgeImpulse and my latest maker101 work on uploading raw data is making that kind of thing easier to do.
Might take a while, thanks for your help.
By the way, having some success with TFJS. Does this look at all sensible for the FOMO model. Converting it to a tfjs layers model was a pain.
___________________________________________________________________________________________________________________
tfjs@3.19.0:17 Layer (type) Input Shape Output shape Param # Receives inputs
tfjs@3.19.0:17 ===================================================================================================================
tfjs@3.19.0:17 input_1 (InputLayer) [[null,96,96,1]] [null,96,96,1] 0
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 Conv1 (Conv2D) [[null,96,96,1]] [null,48,48,16] 144 input_1[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 bn_Conv1 (BatchNormalizati [[null,48,48,16]] [null,48,48,16] 64 Conv1[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 Conv1_relu (ReLU) [[null,48,48,16]] [null,48,48,16] 0 bn_Conv1[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 expanded_conv_depthwise (D [[null,48,48,16]] [null,48,48,16] 144 Conv1_relu[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 expanded_conv_depthwise_BN [[null,48,48,16]] [null,48,48,16] 64 expanded_conv_depthwise
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 expanded_conv_depthwise_re [[null,48,48,16]] [null,48,48,16] 0 expanded_conv_depthwise
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 expanded_conv_project (Con [[null,48,48,16]] [null,48,48,8] 128 expanded_conv_depthwise
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 expanded_conv_project_BN ( [[null,48,48,8]] [null,48,48,8] 32 expanded_conv_project[0
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_1_expand (Conv2D) [[null,48,48,8]] [null,48,48,48] 384 expanded_conv_project_B
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_1_expand_BN (BatchNo [[null,48,48,48]] [null,48,48,48] 192 block_1_expand[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_1_expand_relu (ReLU) [[null,48,48,48]] [null,48,48,48] 0 block_1_expand_BN[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_1_pad (ZeroPadding2D [[null,48,48,48]] [null,49,49,48] 0 block_1_expand_relu[0][
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_1_depthwise (Depthwi [[null,49,49,48]] [null,24,24,48] 432 block_1_pad[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_1_depthwise_BN (Batc [[null,24,24,48]] [null,24,24,48] 192 block_1_depthwise[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_1_depthwise_relu (Re [[null,24,24,48]] [null,24,24,48] 0 block_1_depthwise_BN[0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_1_project (Conv2D) [[null,24,24,48]] [null,24,24,8] 384 block_1_depthwise_relu[
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_1_project_BN (BatchN [[null,24,24,8]] [null,24,24,8] 32 block_1_project[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_2_expand (Conv2D) [[null,24,24,8]] [null,24,24,48] 384 block_1_project_BN[0][0
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_2_expand_BN (BatchNo [[null,24,24,48]] [null,24,24,48] 192 block_2_expand[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_2_expand_relu (ReLU) [[null,24,24,48]] [null,24,24,48] 0 block_2_expand_BN[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_2_depthwise (Depthwi [[null,24,24,48]] [null,24,24,48] 432 block_2_expand_relu[0][
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_2_depthwise_BN (Batc [[null,24,24,48]] [null,24,24,48] 192 block_2_depthwise[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_2_depthwise_relu (Re [[null,24,24,48]] [null,24,24,48] 0 block_2_depthwise_BN[0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_2_project (Conv2D) [[null,24,24,48]] [null,24,24,8] 384 block_2_depthwise_relu[
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_2_project_BN (BatchN [[null,24,24,8]] [null,24,24,8] 32 block_2_project[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_2_add (Add) [[null,24,24,8],[null,24,24 [null,24,24,8] 0 block_1_project_BN[0][0
tfjs@3.19.0:17 block_2_project_BN[0][0
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_3_expand (Conv2D) [[null,24,24,8]] [null,24,24,48] 384 block_2_add[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_3_expand_BN (BatchNo [[null,24,24,48]] [null,24,24,48] 192 block_3_expand[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_3_expand_relu (ReLU) [[null,24,24,48]] [null,24,24,48] 0 block_3_expand_BN[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_3_pad (ZeroPadding2D [[null,24,24,48]] [null,25,25,48] 0 block_3_expand_relu[0][
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_3_depthwise (Depthwi [[null,25,25,48]] [null,12,12,48] 432 block_3_pad[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_3_depthwise_BN (Batc [[null,12,12,48]] [null,12,12,48] 192 block_3_depthwise[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_3_depthwise_relu (Re [[null,12,12,48]] [null,12,12,48] 0 block_3_depthwise_BN[0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_3_project (Conv2D) [[null,12,12,48]] [null,12,12,16] 768 block_3_depthwise_relu[
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_3_project_BN (BatchN [[null,12,12,16]] [null,12,12,16] 64 block_3_project[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_4_expand (Conv2D) [[null,12,12,16]] [null,12,12,96] 1536 block_3_project_BN[0][0
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_4_expand_BN (BatchNo [[null,12,12,96]] [null,12,12,96] 384 block_4_expand[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_4_expand_relu (ReLU) [[null,12,12,96]] [null,12,12,96] 0 block_4_expand_BN[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_4_depthwise (Depthwi [[null,12,12,96]] [null,12,12,96] 864 block_4_expand_relu[0][
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_4_depthwise_BN (Batc [[null,12,12,96]] [null,12,12,96] 384 block_4_depthwise[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_4_depthwise_relu (Re [[null,12,12,96]] [null,12,12,96] 0 block_4_depthwise_BN[0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_4_project (Conv2D) [[null,12,12,96]] [null,12,12,16] 1536 block_4_depthwise_relu[
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_4_project_BN (BatchN [[null,12,12,16]] [null,12,12,16] 64 block_4_project[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_4_add (Add) [[null,12,12,16],[null,12,1 [null,12,12,16] 0 block_3_project_BN[0][0
tfjs@3.19.0:17 block_4_project_BN[0][0
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_5_expand (Conv2D) [[null,12,12,16]] [null,12,12,96] 1536 block_4_add[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_5_expand_BN (BatchNo [[null,12,12,96]] [null,12,12,96] 384 block_5_expand[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_5_expand_relu (ReLU) [[null,12,12,96]] [null,12,12,96] 0 block_5_expand_BN[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_5_depthwise (Depthwi [[null,12,12,96]] [null,12,12,96] 864 block_5_expand_relu[0][
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_5_depthwise_BN (Batc [[null,12,12,96]] [null,12,12,96] 384 block_5_depthwise[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_5_depthwise_relu (Re [[null,12,12,96]] [null,12,12,96] 0 block_5_depthwise_BN[0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_5_project (Conv2D) [[null,12,12,96]] [null,12,12,16] 1536 block_5_depthwise_relu[
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_5_project_BN (BatchN [[null,12,12,16]] [null,12,12,16] 64 block_5_project[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_5_add (Add) [[null,12,12,16],[null,12,1 [null,12,12,16] 0 block_4_add[0][0]
tfjs@3.19.0:17 block_5_project_BN[0][0
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_6_expand (Conv2D) [[null,12,12,16]] [null,12,12,96] 1536 block_5_add[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_6_expand_BN (BatchNo [[null,12,12,96]] [null,12,12,96] 384 block_6_expand[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 block_6_expand_relu (ReLU) [[null,12,12,96]] [null,12,12,96] 0 block_6_expand_BN[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 head (Conv2D) [[null,12,12,96]] [null,12,12,32] 3104 block_6_expand_relu[0][
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 logits (Conv2D) [[null,12,12,32]] [null,12,12,2] 66 head[0][0]
tfjs@3.19.0:17 ___________________________________________________________________________________________________________________
tfjs@3.19.0:17 softmax (Softmax) [[null,12,12,2]] [null,12,12,2] 0 logits[0][0]
tfjs@3.19.0:17 ===================================================================================================================
Or in netron.org format