@rjames
Thanks for reply. Maybe I understand your advise. The easiest way to achieve my goal is to install Ubuntu on my target,then install our edge-impulse-linux. The i can run the model.eim.
Cause i want to learn something from our Edge Impulse,i will try the traditional way to achieve it. Firstly, i need to install a compiler (e.g gcc-7.5.0) . Secondly, install the alsa lib development package (to get the headers) for my target. I need to cross-compiler them to my Aarch64 target without Ubuntu? Is there any instruction for me to refer.
So far you’ve tried edge impulse for linux C++ SDK but couldn’t get it to build because of not having the dependencies (alsa lib headers, C/C++ compilers) on your AARCH64 Linux target.
If you’re not able to get the C++ SDK running, there’s other SDKs you can try given you have the right dependencies:
- If you have python on your target you can try the Linux Python SDK, follow instructions here and/or see this video.
- Or if you have Node.js, you can use the Linux Node.js SDK,
- Or if you have Go then use the Linux Go SDK.
Each provide you with the edge-impulse-linux-runner utility that can run your modelfile.eim.
@rjames Hi rjames
I cross-compiler the ALSA-LIB on Ubuntu,and then link the libasound.so to the path.
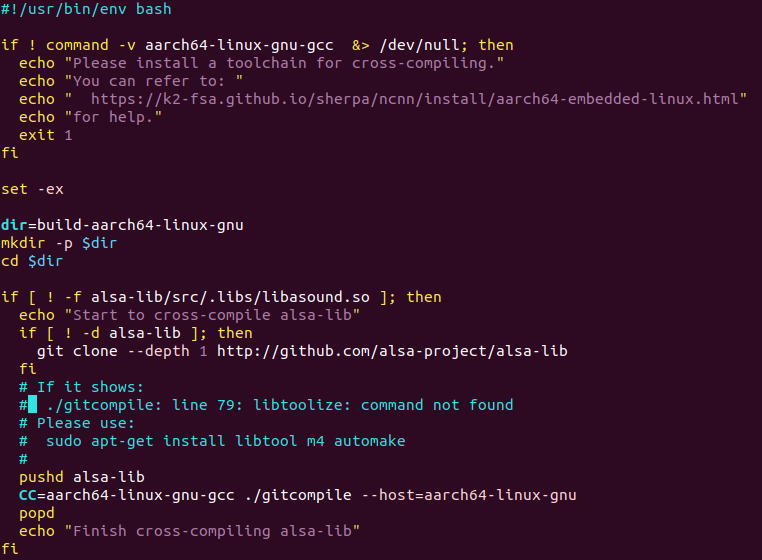
Then i successfully build “AUDIO” file by run "APP_AUDIO=1 CC=aarch64-linux-gnu-gcc CXX=aarch64-linux-gnu-g++ TARGET_LINUX_AARCH64=1 USE_FULL_TFLITE=1 make -j
". Does this run successfully like this ? But maybe my microphone has some problem,it doesn’t change anyway.
@y1165949971
Awesome work!
It can be either (1) unexpected behaviour of the model or (2) an issue with the audio/microphone.
To rule out (1)
- Build the
APP_CUSTOM. - Grab features from Studio.
2.1 Go to Live Classifaction and choose a sample and Load sample
2.2 Copy the Raw features and save it to a file called “features.txt” - Run the custom app against the copied features and compare the results with studio.
3.1./custom features.txt
Repeat the steps above with different features (copied from Studio). If it produces the same results then we can rule out (1) and the issue may be (2).
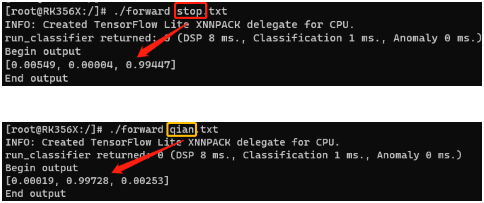
Great looks like the model is performing as expected. I’m glad you got it working
1 Like
@rjames
I have solved the recording problem by setting .asoundrc file. And the model runs great!
I get another question about it. My project has three commands (forward, backward,stop). When I don’t say anything or I just say something else, it will also have a corresponding maximum probability. If I try to use it to control the progress of a car, it will cause the car to run around. This is the result when i speak nothing.
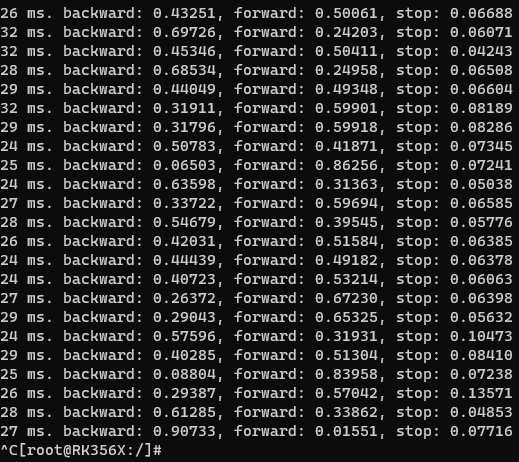
Of course, I can decide whether to control the car by setting the output probability threshold, but it does not solve the fundamental problem.
May I ask if it is possible to train an additional set of data as noise interference, and everything that has nothing to do with the three instructions I need is classified as noise.
Thanks~
Hi @y1165949971,
Nice!! that you have the audio working.
For better visibility, for future posts can you please create a new topic on our forum? https://forum.edgeimpulse.com/
Regarding your question, yes you should add a new class i.e. noise and train your model to classify this class when it’s not any of the others. Take a look at our docs for tips on how to recognize sound.
Yes i can . Thanks for your help