Hi, I tried to upload a csv file through studio without a timestamp column but got this error message. Anyone can help me pls? And is there a limit of how much data in 1 file that I can upload?

@martin449 pls check: https://docs.edgeimpulse.com/reference/importing-csv-data. I am not aware of a practical limit.
@yodaimpulse if my data only has one column without timestamps, can I have a csv file with the content like this?
data
1
2
3
4
.
.
.
or what can I do to make it valid?
Hello @martin449,
Indeed csv without a timestamp should be have only 1 row containing numerical values (+ header). On the example you are giving you have 1 column only.
You can try to transpose your csv to obtain something like:
| Sensor 1 | Sensor 2 | Sensor 3 | Sensor 4 |
|---|---|---|---|
| 1 | 2 | 3 | 4 |
Then if you import it through the uploader you should have something like that:
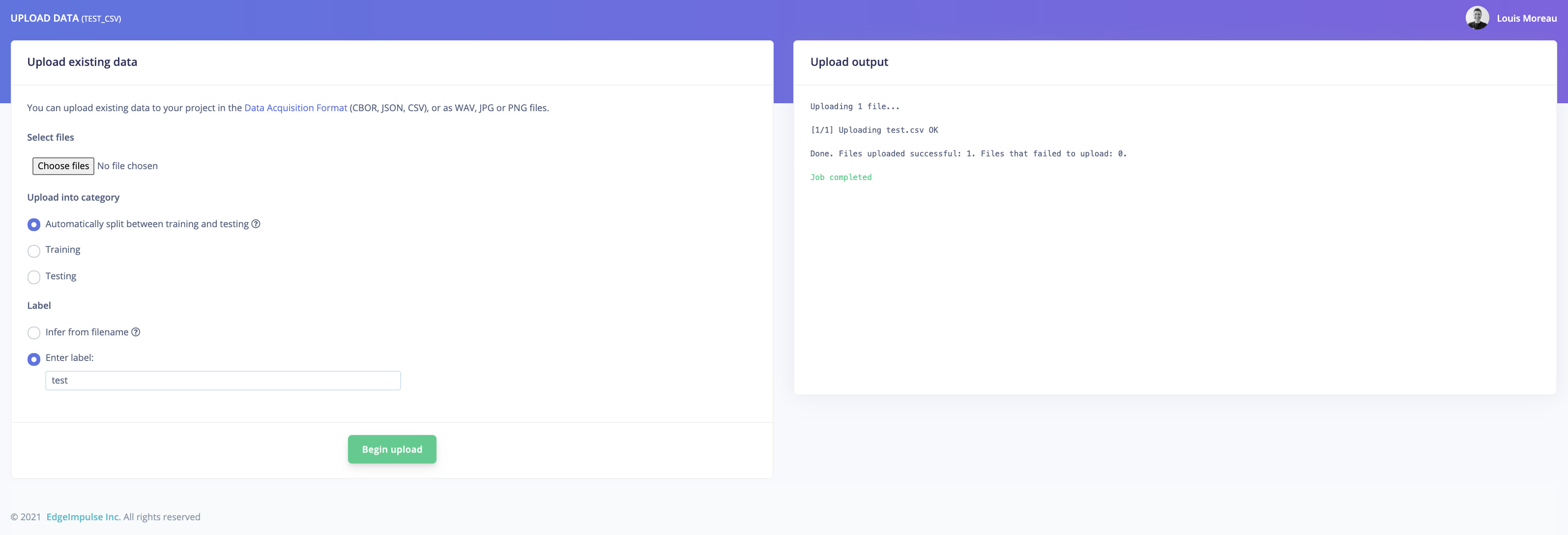
And on your data acquisition tab:
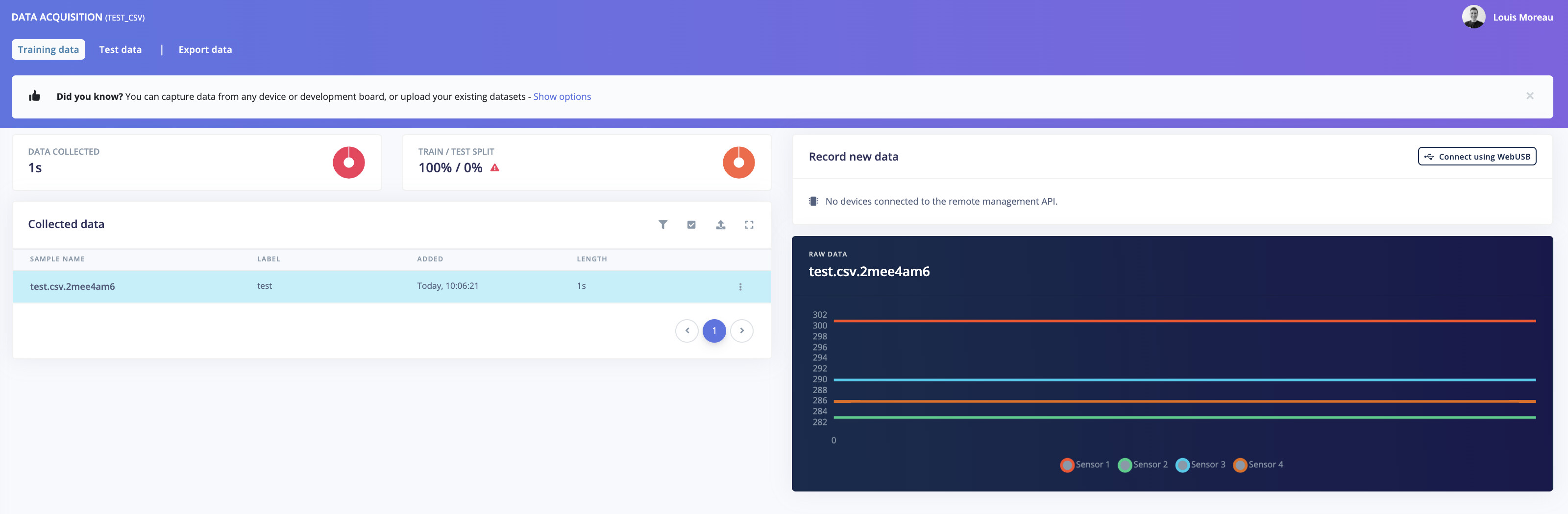
Here is a python3 code snippet if you want to split a big csv file into 1 row CSVs (+header):
my-file.csv
| Sensor 1 | Sensor 2 | Sensor 3 | Sensor 4 |
|---|---|---|---|
| 1 | 2 | 3 | 4 |
| 3 | 1 | 4 | 2 |
| 8 | 3 | 5 | 4 |
| 3 | 4 | 3 | 4 |
into
output.1.csv
| Sensor 1 | Sensor 2 | Sensor 3 | Sensor 4 |
|---|---|---|---|
| 1 | 2 | 3 | 4 |
output.2.csv
| Sensor 1 | Sensor 2 | Sensor 3 | Sensor 4 |
|---|---|---|---|
| 3 | 1 | 4 | 2 |
etc…
This code is not really clean but it should work. Also it does not take into account labels, you will need to set them on the studio or on your output names and select infer from label names in your upload portal:
import csv
def write_new_csv(csv_file_write, column_headers, split_number):
writer = csv.DictWriter(csv_file_write, fieldnames=column_headers)
writer.writeheader()
return writer
def loop_through_csv(csv, split_threshold, column_headers, output_name):
row_counter = 0
split_number = 0
write_csv = None
for row in csv:
if (row_counter == 0) or (row_counter == split_threshold):
# close file if it already exists before writing to a new csv file
if write_csv:
write_csv.close()
split_number += 1
write_csv = open(f'{output_name}.{split_number}.csv', 'w')
writer = write_new_csv(write_csv, column_headers, split_number)
writer.writerow(row)
row_counter = 0
else:
writer.writerow(row)
row_counter += 1
def main():
# grab inputs from user
csv_file_path = input('Enter csv file path: ')
split_threshold = int(input('Enter how many rows per CSV file you would like: '))
output_name = input('Name prefix of the output files: ')
with open(csv_file_path) as csv_file:
csv_reader = csv.DictReader(csv_file)
column_headers = csv_reader.fieldnames
loop_through_csv(csv_reader, split_threshold, column_headers, output_name)
if __name__ == "__main__":
main()
Save this to something called csv-splitter.py and to execute it run:
$> csv-splitter.py
Enter csv file path: your-file.csv
Enter how many rows per CSV file you would like: 1
Name prefix of the output files: your-label
You can also check this thread for more context (we initially focused on timeserie data): Upload dataset in CSV file to Edge Impulse
Regards,
Louis
2 Likes
Hi @louis,
Thank you for your help. Would you mind clarifying on the first row “Sensor 1, Sensor 2,…”? I only use 1 sensor to record data over time, but if my first and only row contain numerical data, the uploader can’t recognized any row (0).
Regards,
Hello @martin449,
In that case you can just run the script I gave you for your CSV looking like:
data
1
2
3
4
.
.
.
I hope that was clear. In my case I had several sensors but if you have only 1, you can either rename your data header with the name of your sensor of leave it as is.
Regards,
Louis
1 Like
hi @louis, I have the same problem, can’t upload the CSV without a timestamp. tried your python code to split my csv dataset, but nothing happen. I have run it on a windows machine.
please help.
this is my example csv data:
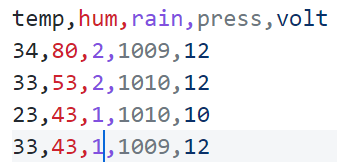
@desnug1 if you know the frequency of the sampled data, just add a column with the timestamp and it should be fine. It is also better to have that since you can better visualize your data with the time using the studio