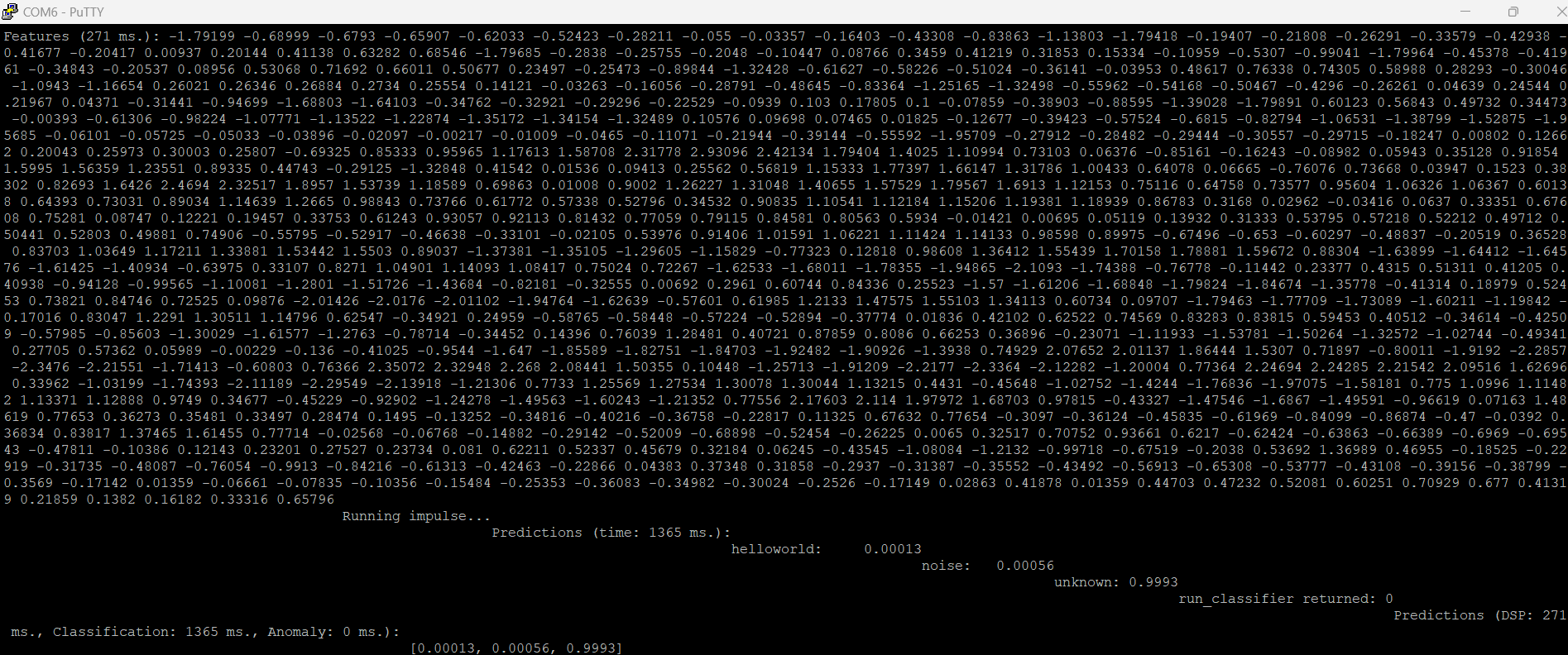
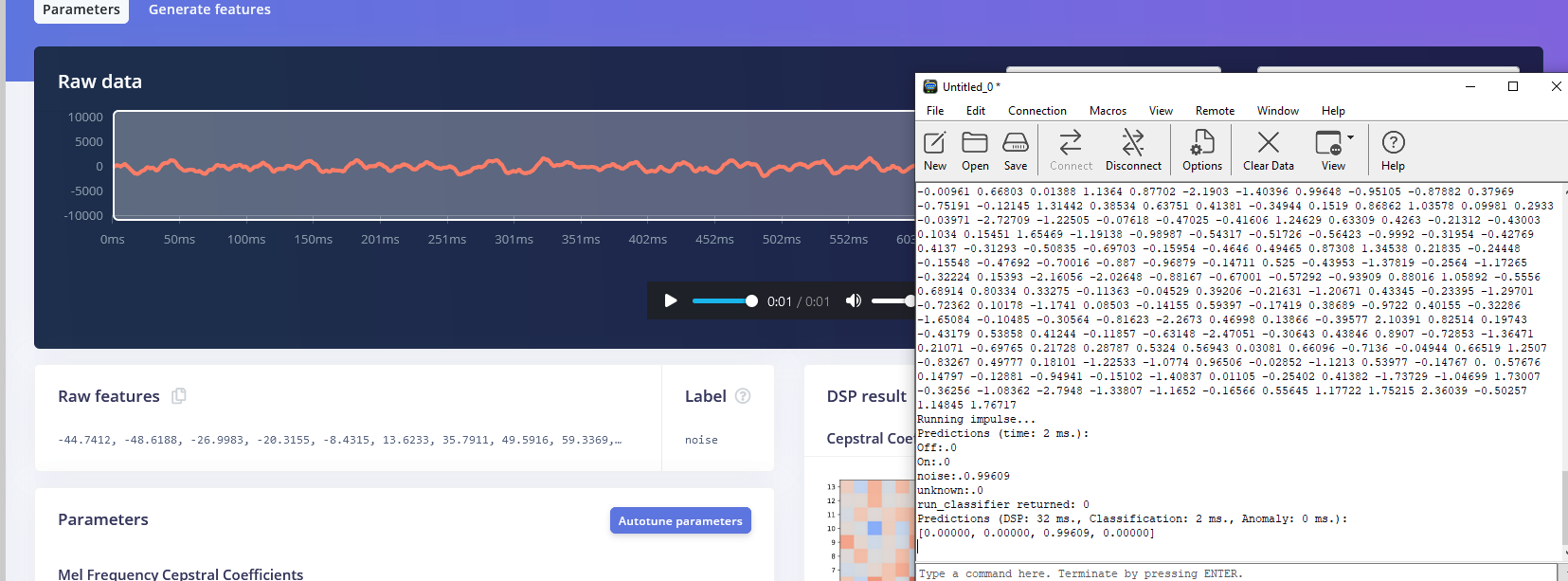
Hi, I am reaching out for assistance with a project I am working on, specifically related to implementing Edge Impulse voice control on the STMicroelectronics B-L475E-IOT01A board.
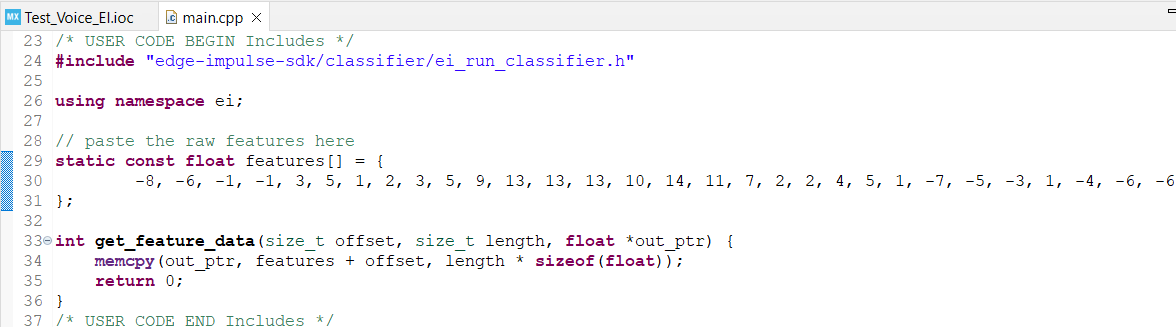
Following the Cube.MX CMSIS-PACK tutorial (Cube.MX CMSIS-PACK | Edge Impulse Documentation), I have successfully compiled the code, and everything appears to be functioning correctly. However, I am encountering discrepancies in the inference results. Despite utilizing raw data that was correctly classified within Edge Impulse, the inference results on the board differ significantly.
I am perplexed by this inconsistency and am seeking guidance to identify the root cause of this error. Could you please provide assistance in troubleshooting this issue?
Did you deploy as a float or int8 quantized model? That can make a difference. The “Model testing” section in Studio will display results using the floating point version of the model.
I have tried both options, but unfortunately, neither of them seems to be working for me. I have conducted more tests on my end:
I successfully deployed the Tutorial: continuous motion recognition using Cube.MX CMSIS-PACK on my STMicroelectronics B-L475E-IOT02A board. The model works well when quantized as either float or int8.
I also deployed the Tutorial: responding to your voice using Cube.MX CMSIS-PACK on the same STMicroelectronics B-L475E-IOT02A board. However, I encountered the same issue that I described in my initial post.
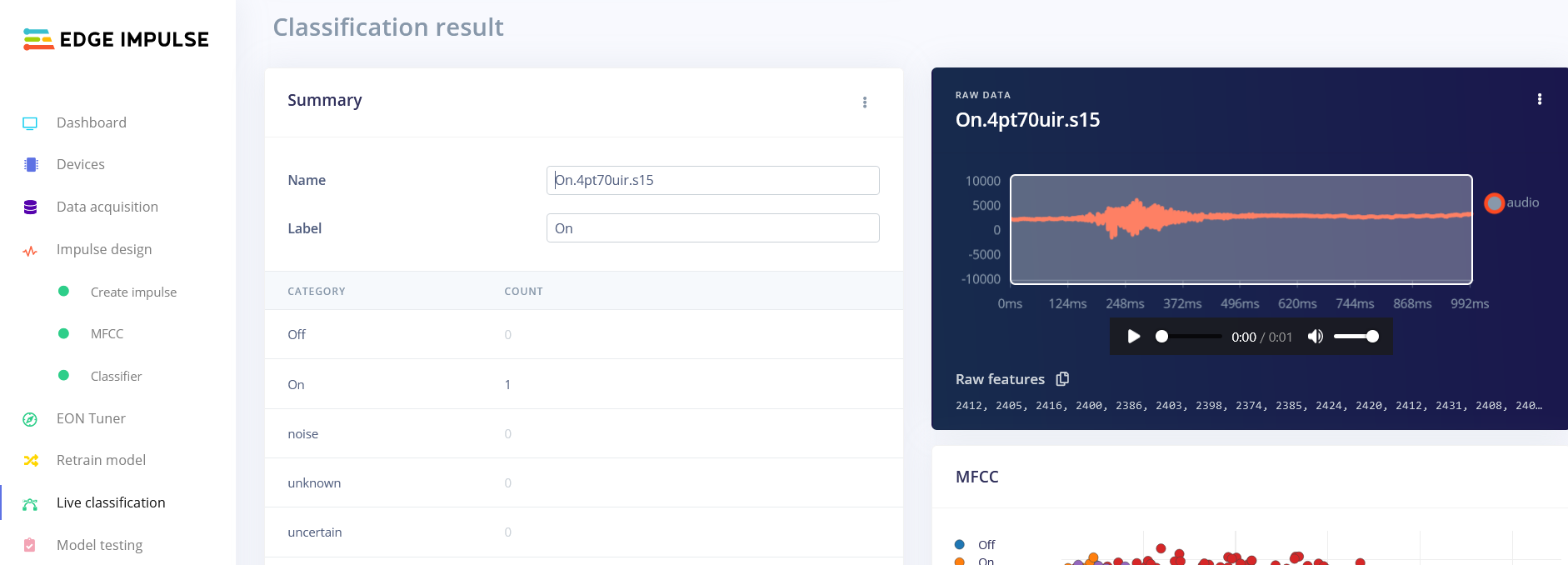
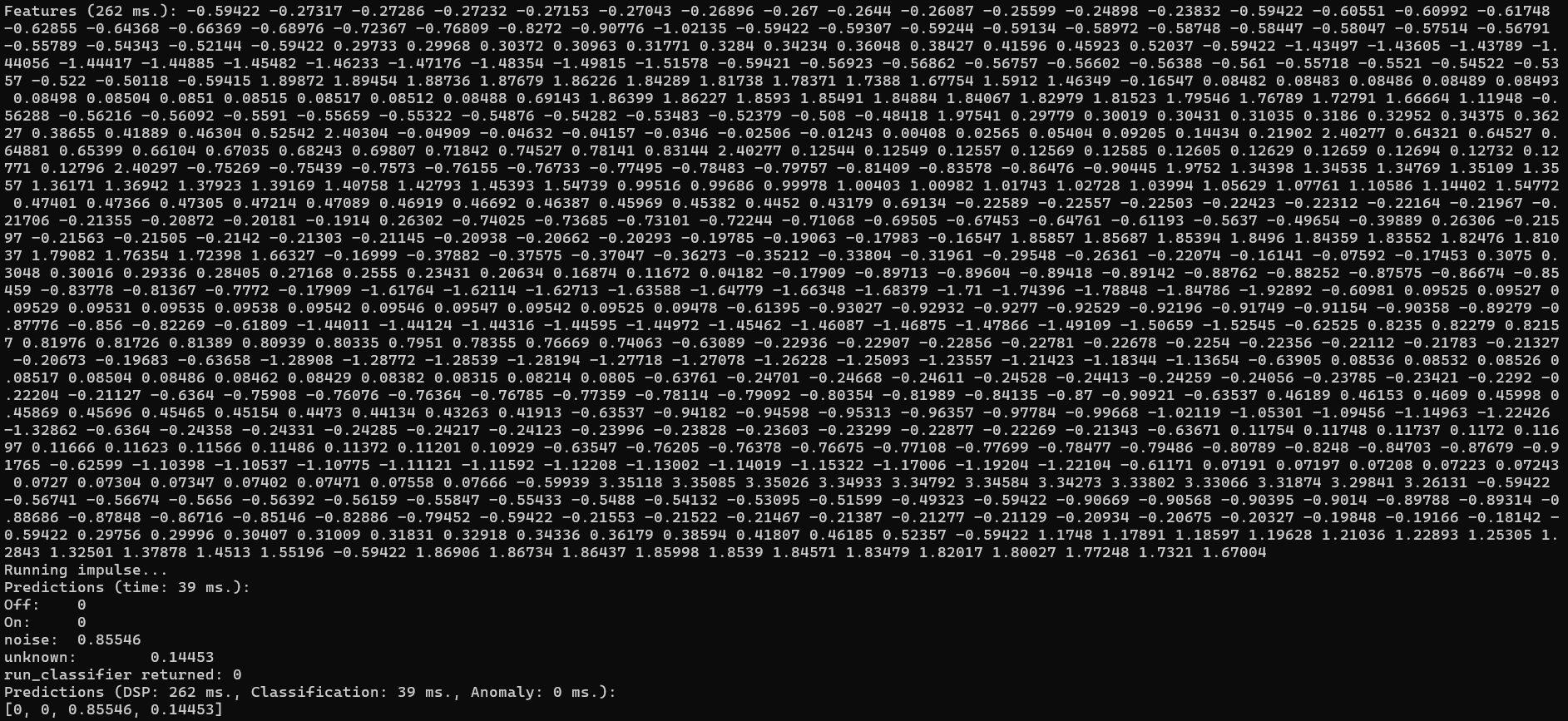
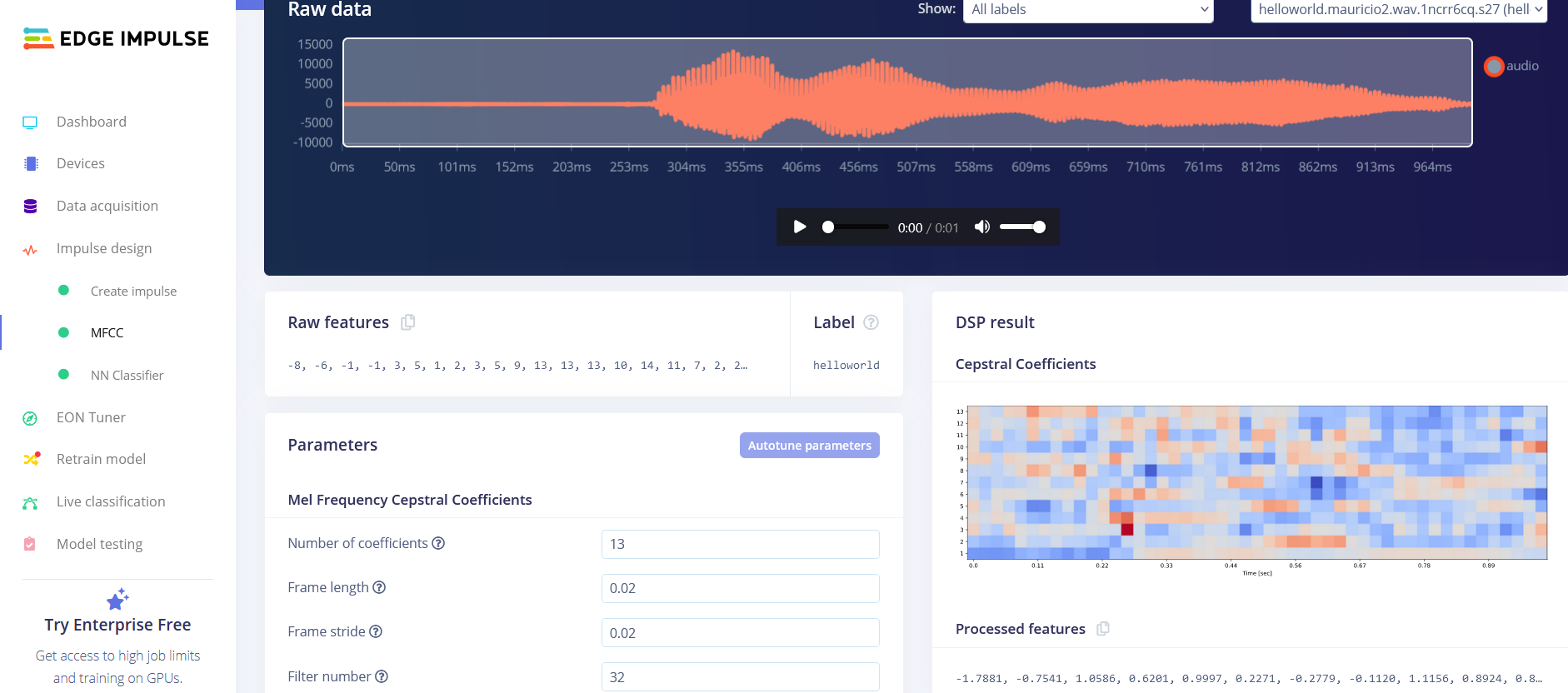
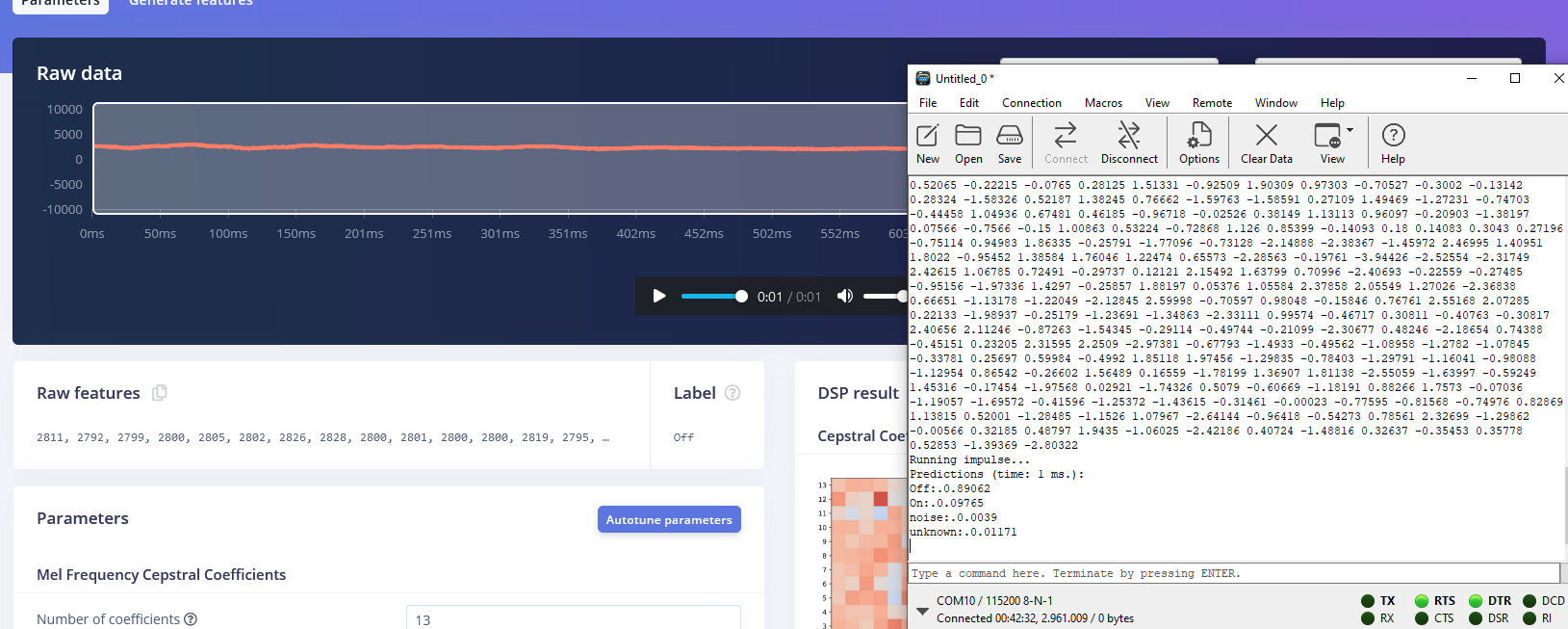
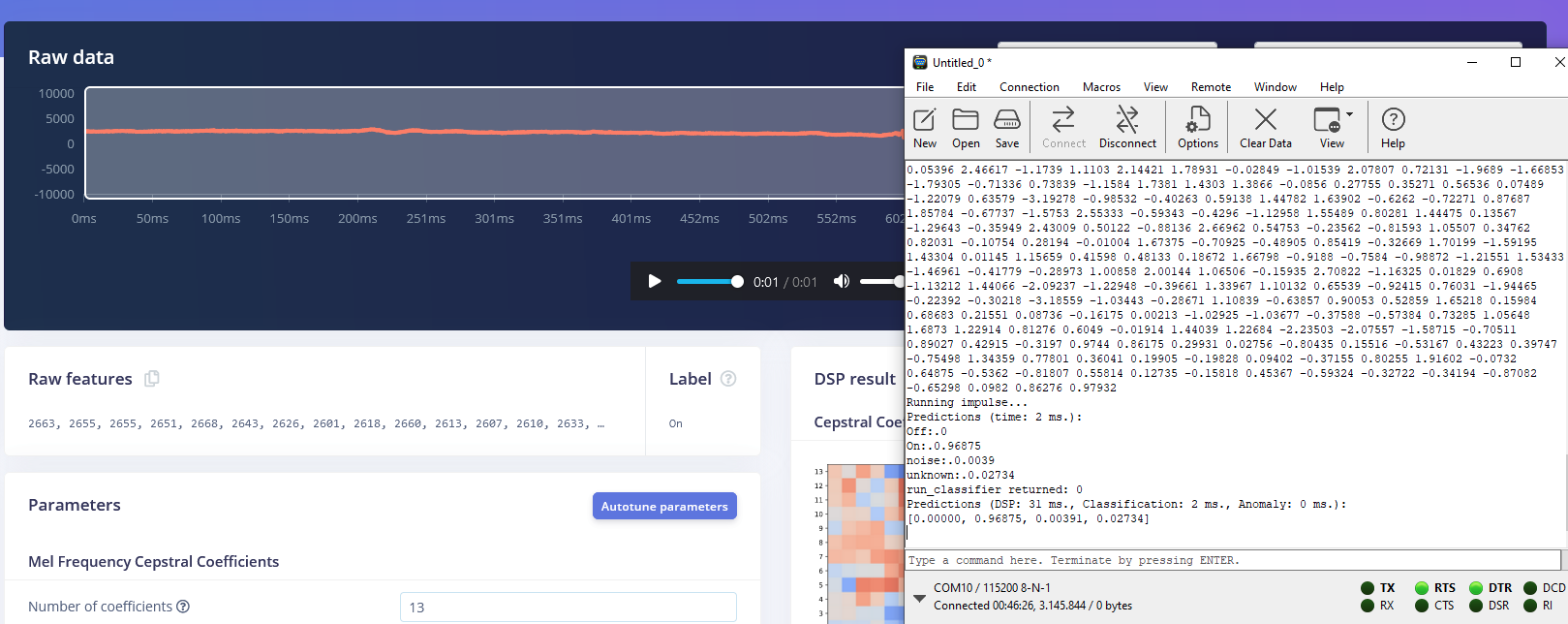
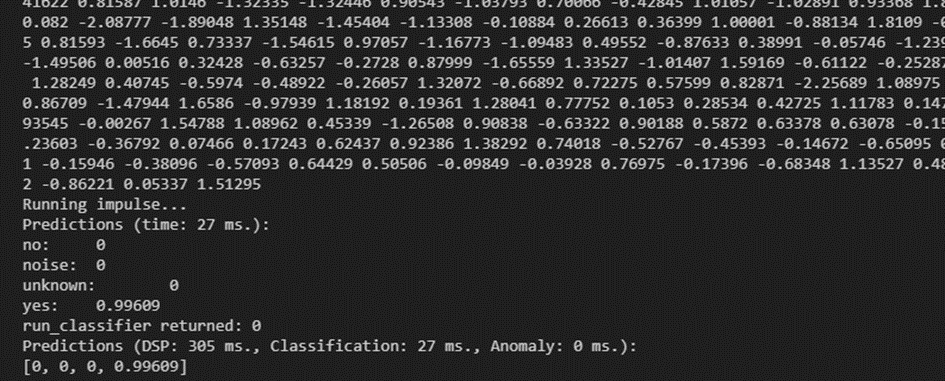
Following these attempts, I have a hunch that there might be an issue with the MFCC block. Upon examining the output of the MFCC block, I noticed that the Processed features do not seem to align with what we would expect from the set of Raw features provided as input. This inconsistency is leading me to suspect that there might be an underlying problem with the MFCC block’s functionality in my project or before this bloc.
I chatted with our engineering team. It seems that the CubeMX deployment option may be deprecated soon, and we recommend using the Open CMSIS pack as the preferred deployment option. Could you try that?
Both deployments labeled as “not working” were attempted using Cube.MX CMSIS-PACK or Open CMSIS pack for the voice recognition project. I encountered the same problem as with the Cube.MX CMSIS-PACK deployment, as described in my second post.
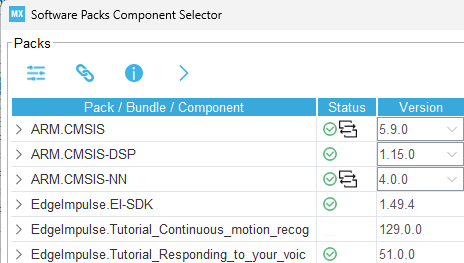
For the Open CMSIS pack, I used CMSIS v5.9.0, CMSIS-DSP v1.15.0, CMSIS-NN v4.0.0, and EI-SDK v1.49.4. Can you confirm if these are the correct versions?
Additionally, I noticed 10 warnings each time during the deployment of all projects in the EI-SDK. I will further investigate these 10 warnings. It’s possible that the Motion recognition project doesn’t utilize the functions associated with these warnings, which might explain why it works while the Voice recognition project doesn’t.
I confirm the problem, I’ve been suffering for a week now. CUBE.MX CMSIS-PACK not working on NUCLEO STM32F767ZI, i can compile it but features wrong after dsp. and when i use float instead Q8 NN time on 200Mhz CortexM7 is 485ms!!! BUT the same project compiled for arduino XIAO NRF52 NN around 50 ms (Cortex M4 - 64Mhz). I haven’t tried it yet OPEN CMSIS on STM32F767.
Did you use a CMSIS-PACK or a C++ library when testing?
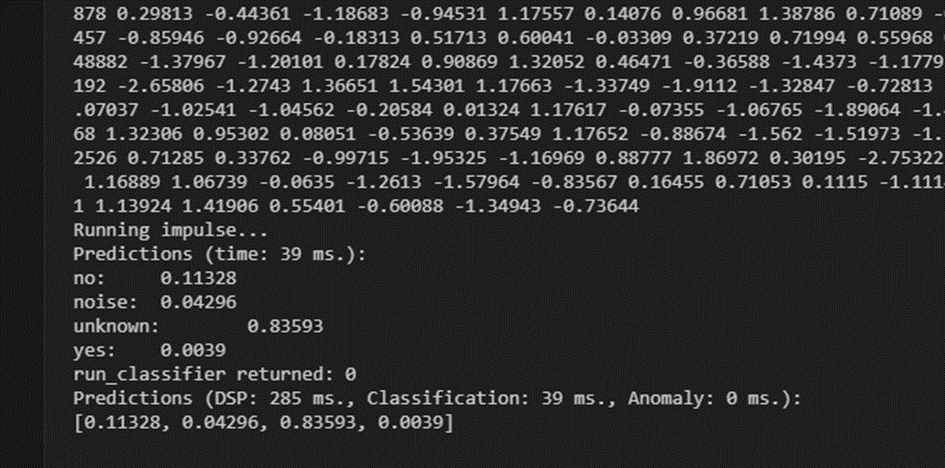
I have the same problem as Hcelle. I have a keyword spotting model that I want to get working on an -L475-IOT01A1. The model works perfectly on an Arduino Nano 33 BLE Sense. But if I run it on the B-L475-IOT01A1 using a CMSIS-PACK or C++ library, it does not work. I do this in the STM32CubeIDE environment. I get an ‘unknown’ back as the highest prediction when I put the data from sample ‘yes’ in it.
I also tried this several times on a NUCLEO-L452RE-P (with a CMSIS-PACK). But this also gives the wrong predictions. The same predictions as the B-L475-IOT01A1.
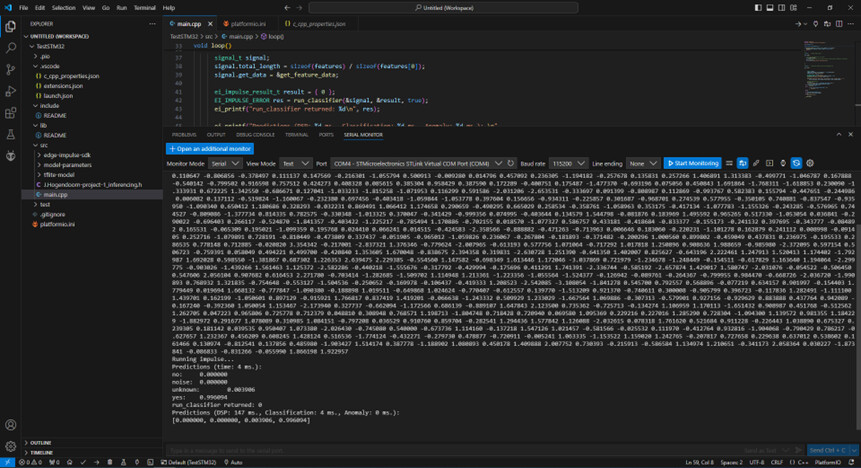
Now I have been able to get the Arduino library working on the B-L475-IOT01A1 using PlatformIO. So this is completely run by Arduino code. I am now getting the correct predictions back. For this I used the same sample data that I used in STM32CubeIDE.
But I have discovered a difference between the outputs. With the Arduino variant I see different output values than with the CMSIS-PACK while I use the same sample data. Is something going wrong in the code I am using?
Both codes: https://github.com/JohanHogendoorn/Edge-Impulse-Audio/tree/main
I haven’t tried using Cube, that seems the IDE everybody is using with this issue - I’ll focus on Cube.
If the output is different, the DSP is returning different results, why idk, need to check. I saw something similar in the past, it was a problem of the math.h used.
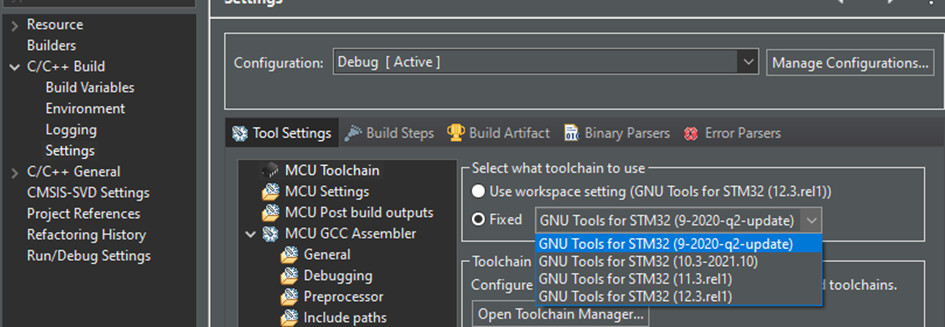
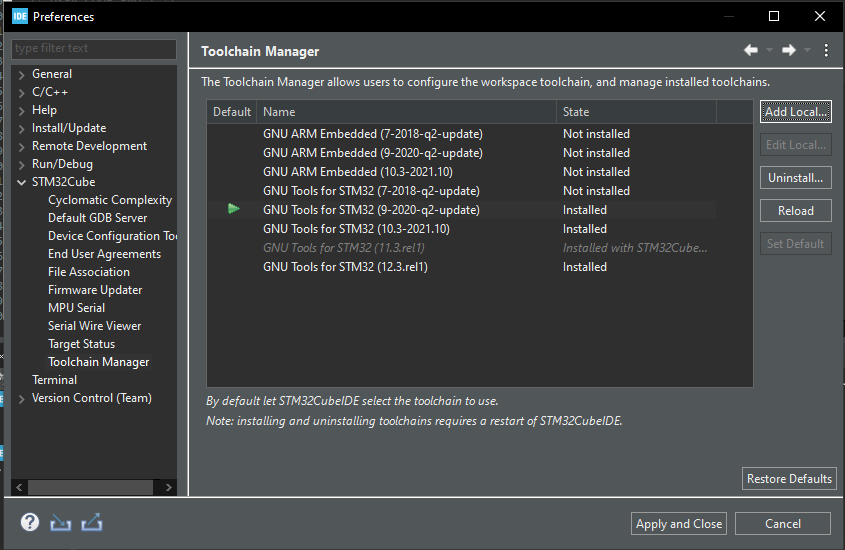
Which Arm-GCC version are you using ? I tested with 10.3.
There you can click on the version and press install. After installation, set the GNU to default (press ‘Set Default’). Hopefully it will now work for others too
Thank you all for your help.
I just tested it in stm32cubeIDE with the Cube.MX CMSIS-PACK and it’s works on my side too !!!
I used the ‘GNU Tools for STM32(9-2020-q2-update)’.
And in stm32cubeIDE the Cube.MX CMSIS-PACK doesn’t work with versions :
I had the same frustrating issue, and I think I’ve found the underlying problem after debugging deep into the Edge Impulse SDK.
The core issue is a risky speed optimization hack in the log function inside numpy.hpp. Newer GCC compilers (like the 13.3.rel1 I use for my Cortex-M7) compile this hack incorrectly for the FPU, leading to corrupted results in the DSP blocks (like MFE).
Essentially, the MFE frequency buckets were being calculated based on wrong logarithm values. My classifier couldn’t recognize the truncated spectrum values and always interpreted them as my background class.
Quick Test to Confirm the Bug
You can verify this in 5 minutes with a minimal test:
This should correctly return log(2.7)=0.993252. If you see a vastly different, wrong number (like 3.386...), you have this problem.
The Clean Code Fix (No GCC Downgrade Needed)
The fastest and most stable fix is to simply replace the unsafe hack with the standard, safe C function logf().
Open the file .../edge-impulse-sdk/dsp/numpy.hpp
Find the log function and replace its contents with this code
__attribute__((always_inline)) static inline float log(float a)
{
return logf(a);
}
This completely fixed the issue for me. Since log is only called once per MFE filter, I highly doubt the minor performance difference will be noticeable on modern cores.