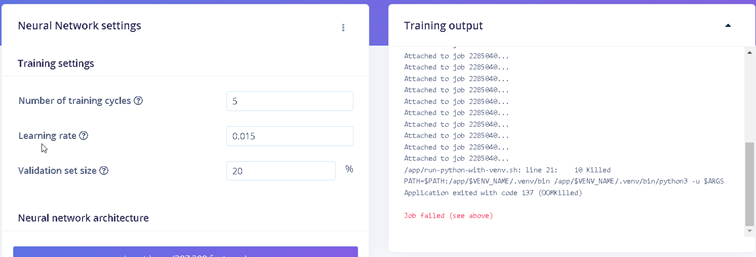
I am trying to train my model after uploading about 1500 images and 10 classes.
Project ID: 85642
I’ve tried running the transfer learning phase several times, and I am getting the following error each time:
/app/run-python-with-venv.sh: line 21: 10 Killed PATH=$PATH:/app/$VENV_NAME/.venv/bin /app/$VENV_NAME/.venv/bin/python3 -u $ARGS
Application exited with code 137 (OOMKilled)
Job failed (see above)
I Would appreciate your help here
Thanks!
Training Output:
Creating job... OK (ID: 2280450)
Scheduling job in cluster...
Job started
Splitting data into training and validation sets...
Splitting data into training and validation sets OK
Training model...
Training on 956 inputs, validating on 240 inputs
Building model and restoring weights for fine-tuning...
Finished restoring weights
Fine tuning...
Attached to job 2280450...
Attached to job 2280450...
Attached to job 2280450...
Attached to job 2280450...
Attached to job 2280450...
Attached to job 2280450...
Attached to job 2280450...
Attached to job 2280450...
Attached to job 2280450...
Attached to job 2280450...
Attached to job 2280450...
Attached to job 2280450...
Attached to job 2280450...
Attached to job 2280450...
/app/run-python-with-venv.sh: line 21: 10 Killed PATH=$PATH:/app/$VENV_NAME/.venv/bin /app/$VENV_NAME/.venv/bin/python3 -u $ARGS
Application exited with code 137 (OOMKilled)
Job failed (see above)
I have now minimised the images to 974 in the training data and minimised them to 253 items in the test data and it still doesn’t work. What could be the reason for this? Could you please help me? This is very important for my bachelor thesis
Hi @Patricksch - maybe a bit late to the party - but we’ve upped the memory limits for all jobs to be less stringent (they can go over memory limits without being killed immediately) and this should resolve all OOMKilled issues. We’re monitoring actively to see if any others happen and can tweak the limits if that’s the case.
Hi @janjongboom
No worries
I’m already done with all the tests for my bachelor
It works for me after deleting some images.
But later i used your new algorithm FOMO and it works fine and it’s very fast.
I’m also getting the same error, now whats the solution, I have already decreased my dataset now I can’t reduce more.
Creating job… OK (ID: 9726117)
Scheduling job in cluster…
Container image pulled!
Job started
Scheduling job in cluster…
Container image pulled!
Job started
Splitting data into training and validation sets…
Attached to job 9726117…
Splitting data into training and validation sets OK
Training model…
Training on 800 inputs, validating on 200 inputs
Attached to job 9726117…
Attached to job 9726117…
Attached to job 9726117…
Trained 1 batches.
Attached to job 9726117…
Attached to job 9726117…
Trained 2 batches.
Attached to job 9726117…
Trained 3 batches.
Attached to job 9726117…
Trained 4 batches.
Attached to job 9726117…
Trained 5 batches.
Attached to job 9726117…
Trained 6 batches.
Attached to job 9726117…
Trained 7 batches.
Attached to job 9726117…
Trained 8 batches.
Attached to job 9726117…
Trained 9 batches.
/app/run-python-with-venv.sh: line 21: 13 Killed PATH=$PATH:/app/$VENV_NAME/.venv/bin /app/$VENV_NAME/.venv/bin/python3 -u $ARGS
Application exited with code 137 (OOMKilled)
Hello, i am having the same issue.
Training model…
Training on 776 inputs, validating on 194 inputs
Attached to job 13823588…
Attached to job 13823588…
Attached to job 13823588…
Attached to job 13823588…
/app/run-python-with-venv.sh: line 17: 11 Killed /app/$VENV_NAME/.venv/bin/python3 -u $ARGS
Application exited with code 137 (OOMKilled)
Hi @janjongboom. I’ve been having the same issue for a bit now. More details are at How to fix "Application exited with code 137 (OOMKilled)", but as a quick explanation my model fails to train after about 99% profiling is completed with this error. I have enterprise edition, and I don’t think I’m going above those limits. I’m not sure how to fix it, and am wondering if it is something I did, or if it is a bug.